Datacom HCIP笔记
非重点但需了解的知识
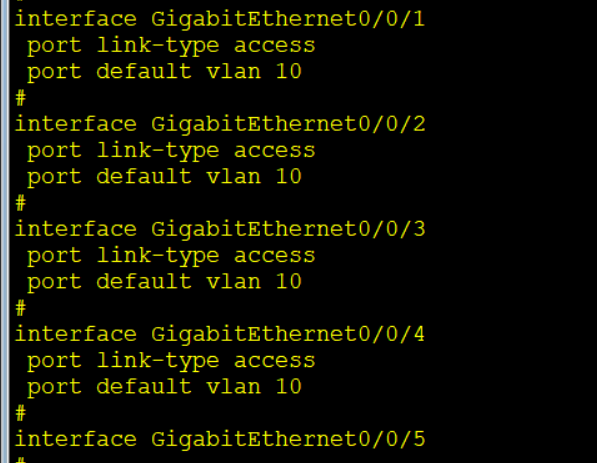
Voice Vlan
网络中的的数据流量可以简单的分为语音流量和数据流量
通过配置Voice vlan可以让语音流量优于业务流量,从而保证语音流量的服务质量
目前电话连接的电话线有两种,一是四针头的小水晶头,二是网线用的八针头水晶头
使用网线的电话是IP电话
对于IP电话,对其进行VLAN划分时必须划分进
Voice Vlan
配置命令:
vlan 2 # 创建一个vlan
int G0/0/1 # 进入接口
voice-vlan 2 enable # 设置vlan2为voice-vlan 并启用
voice-vlan mode auto # 设置voice自动识别
# 配置voice-vlan自动识别的mac地址范围 ffff-ff00-0000 是mac掩码
voice-vlan mac-address 0011-2200-0000 mask ffff-ff00-0000
注:类似0011-2200-0000这样只有高6位有值的MAC地址范围,称为一个OUI (厂商标识符)
在向运营商、国际组织购买MAC地址时,也是以OUI为单位
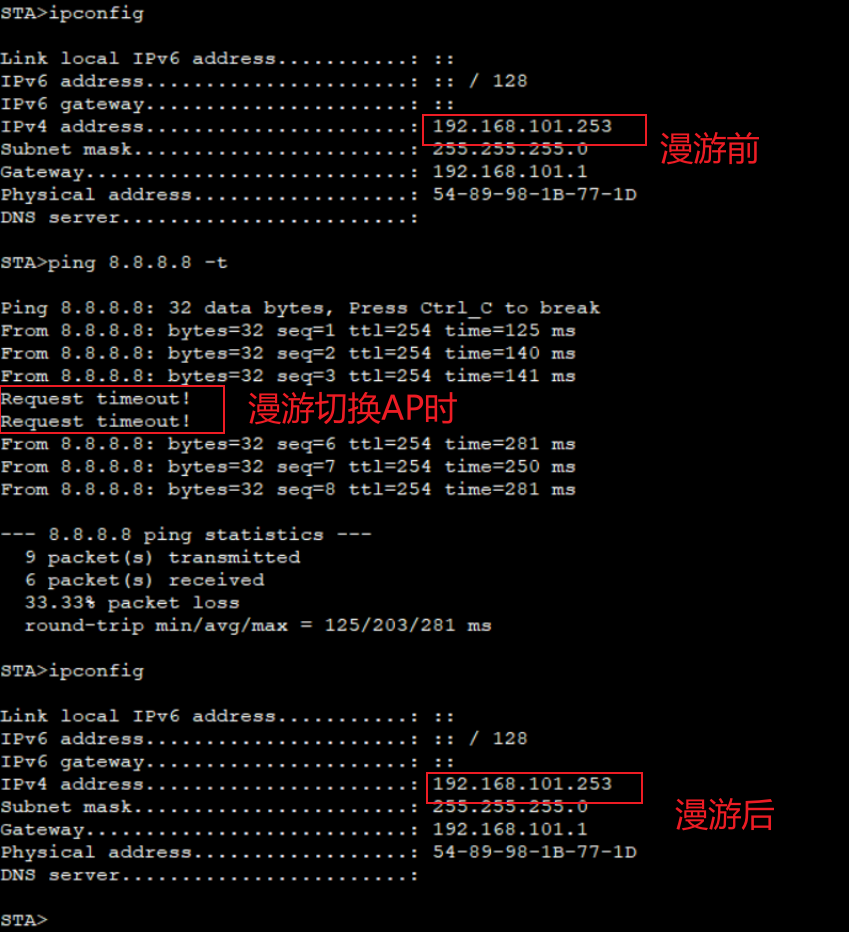
链路状态说明
路由器物理链路又两种状态
- 物理状态:当两端的设备接口接上物理线路之后,互相交换电流脉冲信号,此时接口物理状态UP
- 协议状态:在物理状态UP的基础上,给接口配置合法的IPv4单播地址后,协议状态UP
协议状态基于物理状态存在,当物理状态为Down时,协议状态无论是UP或者DOWN,都转为DOWN状态
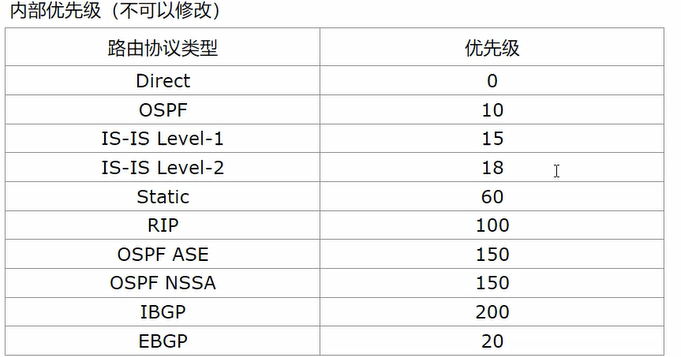
路由协议内部优先级
路由优选规则与掩码、路由优先级、开销值有关
路由优先级有两种
- 外部优先级:路由表中可见,并且可以修改的优先级
- 内部优先级:路由表中不可见,不可修改,是协议开发时就内定的优先级
所以路由优选的正确顺序是:掩码、外部优先级、内部优先级、开销值
例如:
相同协议(OSPF)存在两条掩码长度、外部优先级、开销完全一致的路由,则形成负载分担
不同路由协议(OSPF、ISIS)存在两条掩码长度、外部优先级、开销完全一致的路由
由于内部优先级OSPF为10,ISIS为15/18。所以OSPF路由优于ISIS,路由表中加载OSPF路由。
并且由于优先级已经达到优选路由的目的,不会再去比较开销值

交换机的高级特性
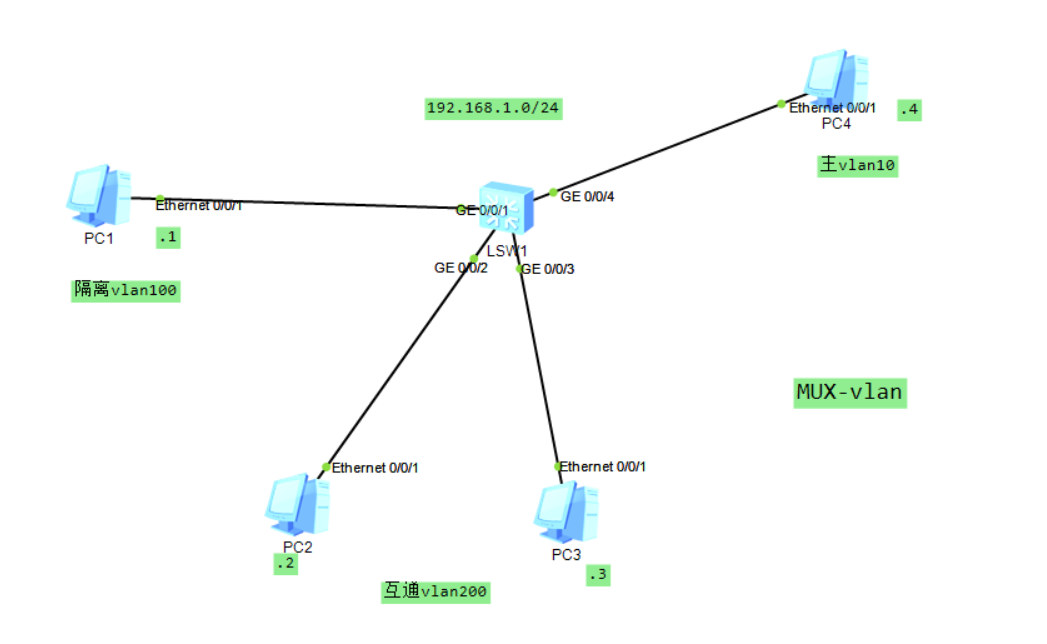
Mux-vlan技术
当一个企业有如下需求:
1、一个部门一个vlan,访客单独一个vlan
2、所有部门和访客都可以访问共享资源
3、部门之间相互隔离,访客与除共享资源外的所有区域隔离
此时就需要使用mux-vlan技术,Mux-vlan技术是vlan技术的高级用法
思科中管mux-vlan叫做
private vlan【私有vlan】
Mux-vlan角色
- 主vlan:
- 一个Mux-vlan网络只有一个主vlan
- 开启Mux-vlan功能的vlan自动成为主vlan
- 主vlan可以被Mux-vlan中的所有vlan访问
- 隔离型子vlan:
- 一个Mux-vlan网络只有一个隔离子vlan
- 隔离型子vlan和除主vlan外的其他vlan不通
- 隔离子vlan内也不互通
- 互通型子vlan:
- 一个Mux-vlan网络可以有多个互通子vlan
- 互通子vlan和除主vlan外的其他vlan不通
- 互通子vlan内部可以互通
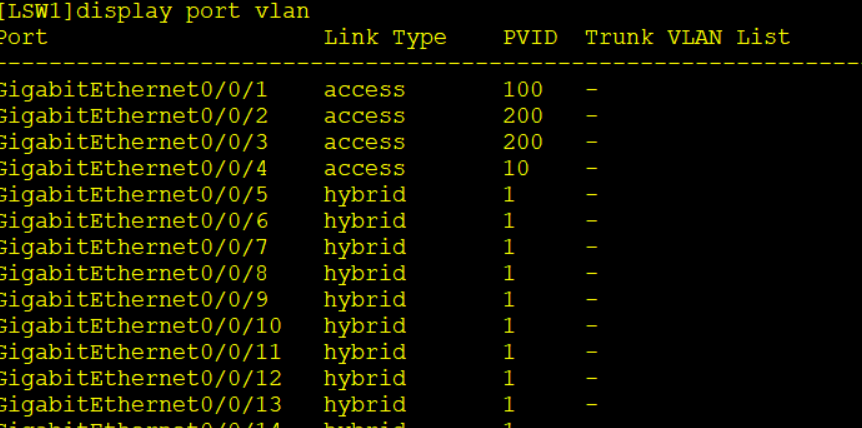
Mux-vlan配置
1、创建vlan
vlan batch 10 100 200
2、配置接口,划分vlan(略)
3、配置Mux-vlan
vlan 10 # 进入vlan视图
mux-vlan # 开启mux-vlan 【谁开启,谁就是主vlan】
subordinate separate 100 # 设置隔离型vlan
subordinate group 200 # 设置互通型vlan
4、在所有相关接口上开启Mux-vlan功能(不开则配置无效)
interface GigabitEthernet0/0/1
port mux-vlan enable # 开启Mux-vlan
truck口不需要也不被允许开启MUX-VLAN
如果一个MUX-VLAN系统中有多台交换机,则每台交换机都需要进行MUX-VLAN的配置
Mux-vlan其他相关命令
1、查看Mux-vlan转发表
display mux-vlan

如果接口启用了mux-vlan功能,交换机使用mux-vlan作为控制表项
如果有一个相关接口没有启用mux-vlan功能,交换机使用port vlan作为控制表项
ARP代理
如果有需求:两个主机之间二层隔离,但是要求可以互通,此时就需要使用ARP代理
ARP代理的分类
ARP代理按使用的场景,可以分为三类
同一网段终端被路由器隔离的场景:路由式ARP代理
enable相同VLAN内,同网段终端被交换机二层隔离的场景:VLAN内ARP代理
inner-sub-vlan-proxy- VLAN内ARP代理常配合端口隔离使用
不同VLAN间,同网段终端在聚合VLAN中的场景:VLAN间的ARP代理
inter-sub-vlan-proxy- VLAN间的ARP代理常在VLAN聚合中使用
路由式ARP代理
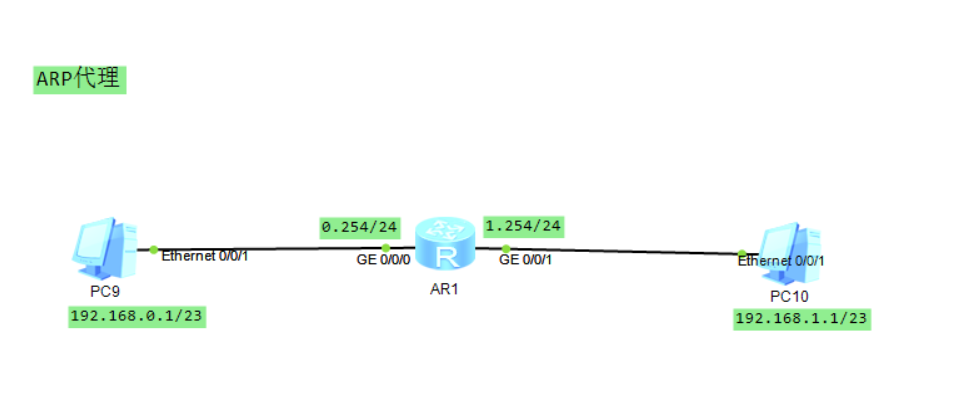
如上:PC9和PC10在同一网段,要求他们互通且不能配置路由
此时ARP报文需要跨网段,但路由器隔离广播域,ARP报文不可达
【上图没有配置给PC网关】
ARP代理配置
ARP代理的实质就是通过三层转发二层ARP报文
interface GigabitEthernet0/0/0
arp-proxy enable # 开启arp代理
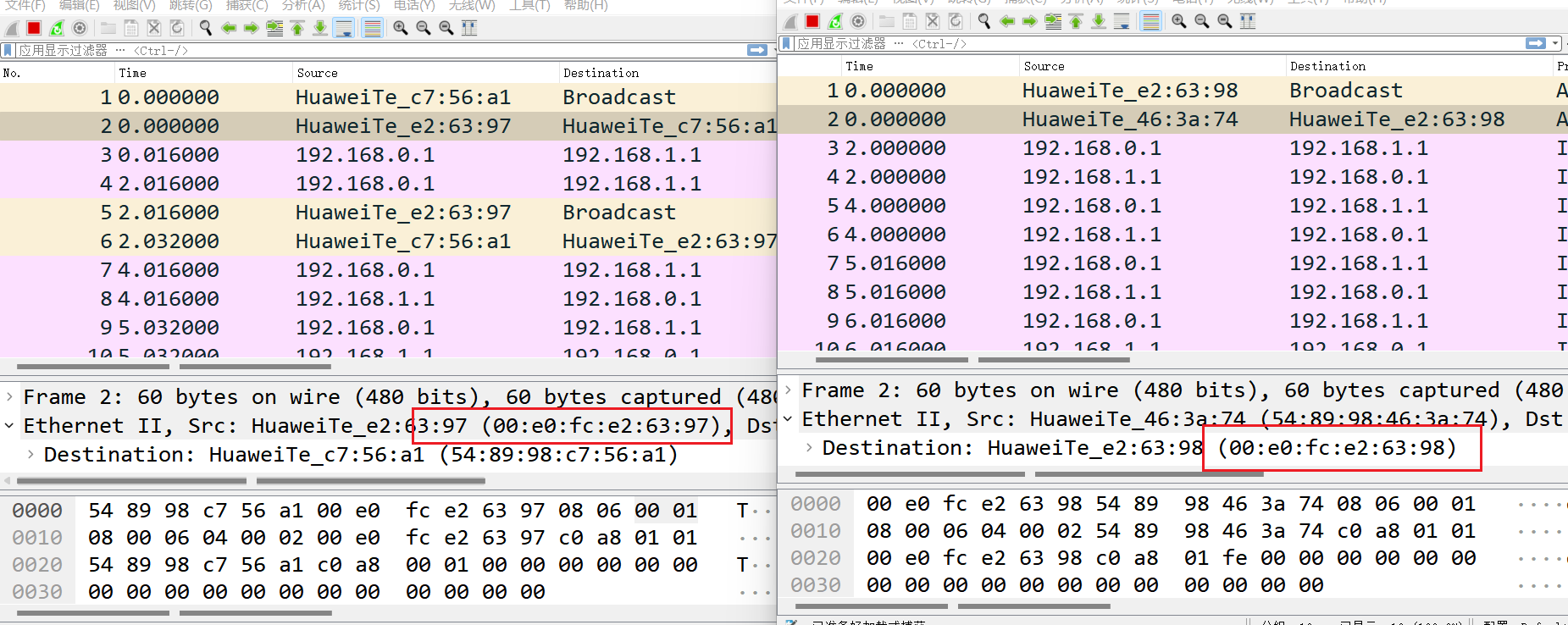
当开启ARP代理后,G0/0/0端口收到ARP请求报文,将查找路由表进入三层转发
以路由表找到的出接口为源,PC10为目的,以路由器的身份发送ARP请求
收到响应包后,又以ARP代理端口为源发回PC9
VLAN内ARP代理
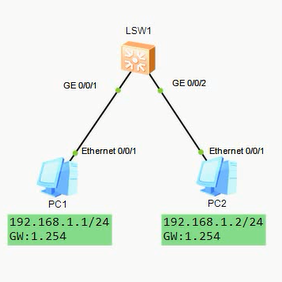
如图,PC1和PC2被交换机连接,但交换机做了端口隔离,此时如果需要PC1和PC2二层互通,就需要ARP代理
端口隔离在以太网交换安全部分
配置方式:
int vlanif 30 # 进入网关vlanif端口
arp-proxy inner-sub-vlan-proxy enable # 开启VLAN内ARP代理
配置端口隔离技术,同网段二层无法直接通信,只能通过网关代理,此时网关就可以对数据进行监控和处理,增大以太网络安全性
聚合VLAN(super-vlan)
传统的vlan划分每个vlan都需要一个网段,由于子网划分的特性,传统vlan每划一个vlan,就浪费两个地址
在一些对安全性要求很严格的企业往往会划分很多vlan
此时传统的vlan划分方式会导致ip地址数不足
聚合VLAN技术就是为了解决传统vlan划分浪费ip的问题
实现原理
聚合vlan技术通过定义一个主vlan,下挂多个子vlan的方式实现
子vlan所有终端都设置在同一网段
在主vlan配置网关,让主vlanif接口是所有子vlan的网关
由于vlan隔离二层,相同网段通信不会进入三层,此时子vlan之间无法互通
又因为不同网段通信进入三层,所以子vlan和外界可以通信
注意事项
由于子vlan用于二层,主vlan负责三层,所以有以下注意事项
- 子vlan只能绑定在物理端口上,不能开启三层路由(vlanif)
- 主vlan只负责三层路由(vlanif),不能绑定在物理端口上作为二层使用
聚合vlan配置
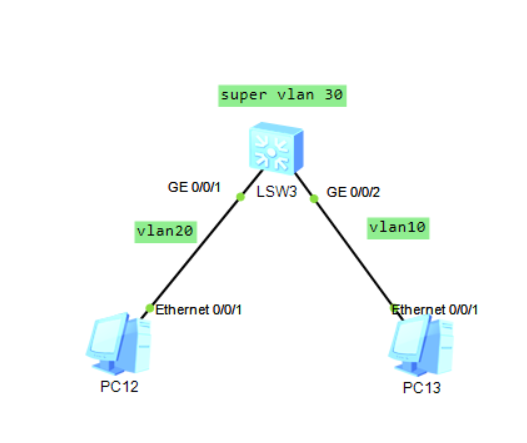
[Huawei]vlan 30 # 进入vlan30
[Huawei-vlan30]aggregate-vlan # 开启聚合vlan
[Huawei-vlan30]access-vlan 10 20 # 设置下属子vlan
和mux-vlan一样,谁开启了功能,谁就是主vlan
跨交换机的VLAN聚合按正常VLAN配置即可,可以不在trunk链路中放行super vlan
聚合VLAN的ARP代理
vlan隔离二层,同网段不走三层,所以聚合vlan中的子vlan在不另外配置三层的情况下是无法互通的
如果有需求让子vlan之间二层互通,就需要使用ARP代理(VLAN间的ARP代理)
让主vlan的vlanif代理子vlan的arp请求
配置命令:
[Huawei]int Vlanif 30 # 进入vlanif接口
[Huawei-Vlanif30]arp-proxy inter-sub-vlan-proxy enable # 开启VLAN间ARP代理
QinQ技术
QinQ概述
QinQ,即802.1q in 802.1q
QinQ内部数据透明传输
字面意思,就是一个VLAN TAG套一个VLAN TAG,是一种二层的VPN技术,可以让私网的VLAN透穿公网,从一个局域网广播域到另一个广播域

使用场景
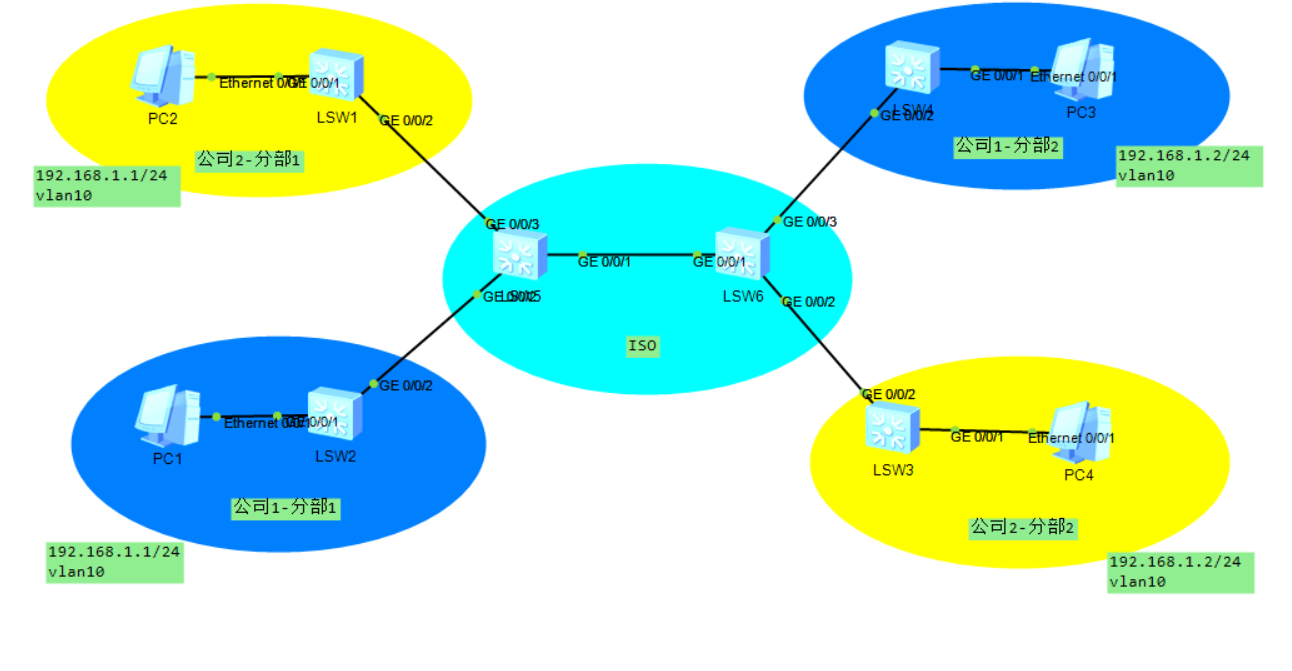
如果,公司使用交换机和运营商交换机连接,并且公司两个分部属于同一vlan,同一网段
此时如果想让公司两个分部之间实现二层互访,就需要配置qinq隧道
QinQ隧道在运营商交换机(公网设备)入口给数据打上vlan
vlan-tag是入口打的,不是出口打的。但是隧道是出口到隧道对端入口
绝大多数VPN都是入口对数据进行操作,出口才是真正的隧道
在运营商网络中交换时,运营商交换机只看自己打的vlan,而不理会公司内网的vlan
当数据传输到QinQ隧道另一端时,运营商交换机将自己的vlan剥离,将数据还给另一端内网
QinQ配置
基本配置
公司1分部1内网交换机 and 公司1分部2内网交换机
[Huawei]v 10
[Huawei]int g0/0/1
[Huawei-GigabitEthernet0/0/1]p l a
[Huawei-GigabitEthernet0/0/1]p d v 10
[Huawei-GigabitEthernet0/0/1]int g0/0/2
[Huawei-GigabitEthernet0/0/2]p l t
[Huawei-GigabitEthernet0/0/2]p t a v 10
建立QinQ隧道
交换机配置端口类型有四种
[LSW5-GigabitEthernet0/0/2]port link-type ?
access Access port
dot1q-tunnel QinQ port
hybrid Hybrid port
trunk Trunk port
其中dot1q-tunnel就是QinQ隧道
LSW5:
[LSW5]v 100
[LSW5]int g0/0/2
[LSW5-GigabitEthernet0/0/2]port link-type dot1q-tunnel # 设置端口模式为dot1q隧道
[LSW5-GigabitEthernet0/0/2]port default vlan 100 # 设置默认为vlan100
QinQ隧道出入口要进行相同的配置
转发规则:
- 进QinQ隧道:进QinQ隧道的数据包全部再打一层默认vlan的标签(不改变原来的标签)
- 出QinQ隧道:出QinQ隧道的数据包规则和access一样,剥离vlan标签(剥离的是进隧道打的标签,不剥原来的)
这样一个vlan帧就从一个局域网到了另一个局域网
灵活QinQ
对隧道来说,无论是什么vlan的数据经过,都会在外层套上一个固定的vlan
在site有多个时,这样做会出现问题:本来site1发往site2的vlan10数据,被同属QinQ网络的site3 vlan10接收
灵活QinQ可以解决这个问题,争对不同的站点打上不同的外层vlan
配置:
LSW5:
[LSW5]v 100
[LSW5]int g0/0/2
[LSW5-GigabitEthernet0/0/2]qinq vlan-translation enable # 开启灵活QinQ
[LSW5-GigabitEthernet0/0/2]port hybrid untagged vlan 100 200 # 设置hybrid口,剥离vlan 100 200
[LSW5-GigabitEthernet0/0/2]port vlan-stacking vlan 10 stack-vlan 100 # 给vlan10套上vlan100
[LSW5-GigabitEthernet0/0/2]port vlan-stacking vlan 20 stack-vlan 200 # 给vlan20套上vlan200
QinQ隧道出入口要进行相同的配置
以太网交换安全
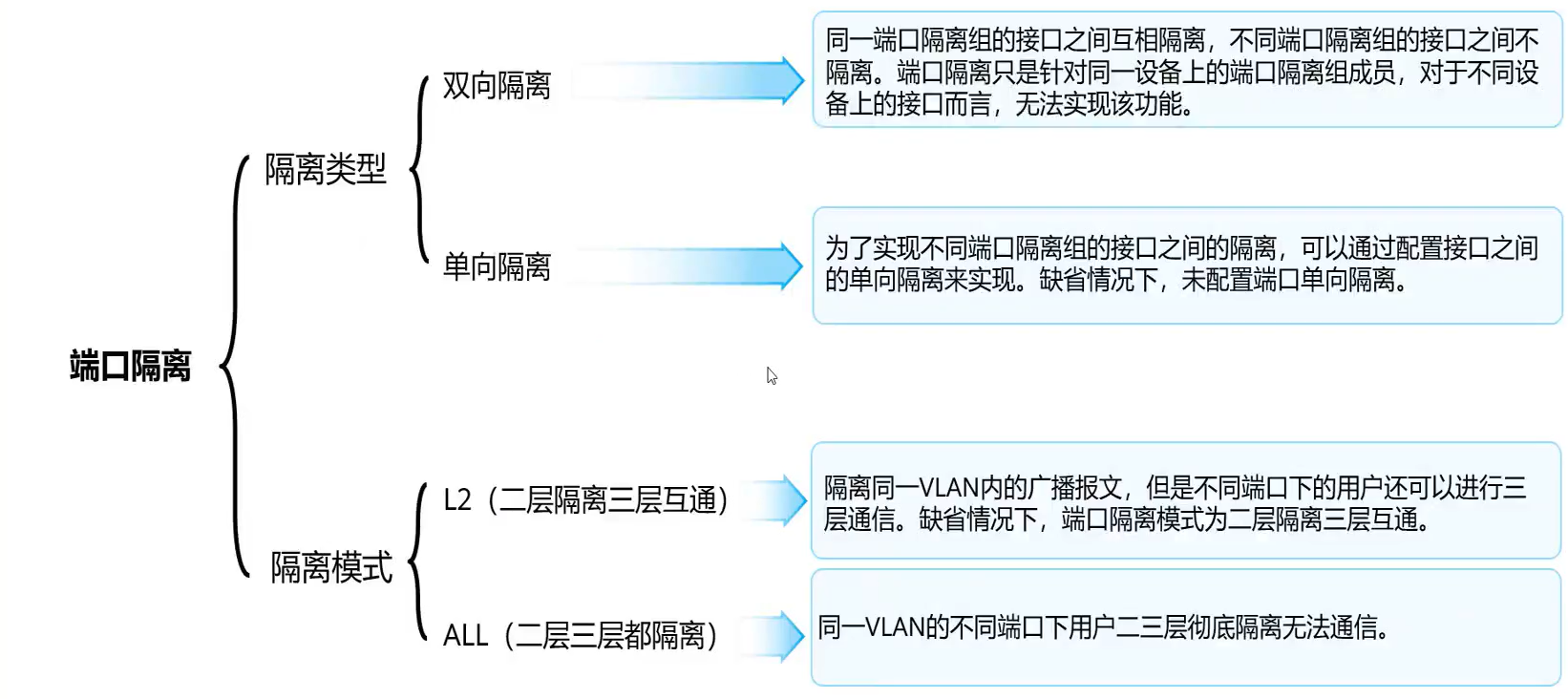
端口隔离
端口隔离的目的是让同一个VLAN中的设备仍然可以隔离广播域
类似Mux-VLAN的隔离型子VLAN,但与之不同,端口隔离并不会影响三层数据交换,Mux-VLAN目前无法三层转发
从实现流过滤的角度看,三层可以通过acl,二层流过滤并不方便,端口隔离可以实现二层的简单过滤
端口组的应用与配置
在配置交换机端口时,往往有很多端口的配置是重复的,这时一个个敲就很麻烦
可以通过将多个端口划分进组的方式,一次配置多个端口
port-group 1 # 开启端口组1
group-member GigabitEthernet 0/0/1 to GigabitEthernet 0/0/4 # 将g0/0/1到g0/0/4口划入端口组
p l a # 简写,port link-type access
p d v 10 # 简写,port default vlan 10
此时在组里的配置将同时应用在端口组内的所有接口上
端口隔离模式
- L2模式:同一VLAN二层隔离但三层可以通信
- ALL模式:同一VLAN二层和三层都无法通信
注意是同一VLAN,不同VLAN还是按VLAN间通信的规则处理
[Huawei]port-isolate mode ?
all All
l2 L2 only
默认是L2模式
端口隔离的配置
双向端口隔离配置
双向端口隔离实现同一隔离组的内复数端口间的相互隔离
在端口配置隔离组后,如果数据包的入端口和出端口属于同一隔离组,那么交换机将丢弃该数据包
- 相同隔离组端口下的主机不同互通
- 不同隔离组端口下的主机可以互通
- 一个端口可以配置多个隔离组
interface GigabitEthernet0/0/1 # 进入0/0/1口
port-isolate enable group 1 # 开启端口隔离,设置隔离组为1
port-isolate enable group 2 # 开启端口隔离,设置隔离组为2
单向端口隔离
单向端口隔离实现不同隔离组间的端口隔离
int g0/0/1
am isolate GigabitEthernet 0/0/2
设置当前接口和指定接口的隔离,即当前接口不能访问指定接口
指定接口仍然可以访问当前接口,但是由于没有回应报文,多数情况任然无法通信
MAC地址表安全
MAC地址表的类型
MAC地址表项分为三类:
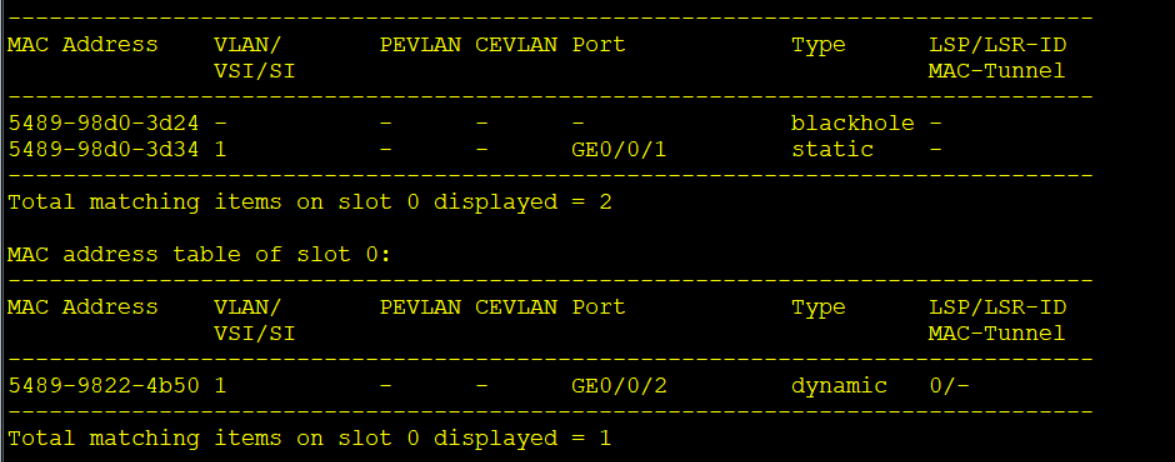
- 动态MAC表项(dynamic)
- 动态MAC表项是交换机自己学习的MAC地址表项
- 动态MAC表项存在老化时间,在系统复位、接口热插拔后丢失
- 静态MAC表项(Static)
- 静态MAC表项是由管理员手动下发的表项
- 静态MAC表项不老化,在系统复位、接口热插拔后也不会丢失
- 静态MAC表项绑定接口后,其他接口收到源MAC为该静态MAC的数据将会丢弃
- 黑洞MAC表项(Blackhole)
- 黑洞MAC表项是由管理员手动下发的表项
- 黑洞MAC表项不老化,在系统复位、接口热插拔后也不会丢失
- 配置黑洞MAC表项后,源或目的MAC为该黑洞MAC的数据将会丢弃
dispaly mac-address # 查看MAC转发表
MAC地址静态绑定
由于交换机会主动学习收到数据的源MAC地址更新动态的MAC地址表项,导致如果有人非法伪造MAC地址,就会造成MAC地址欺骗攻击
MAC欺骗攻击:攻击者伪造网关或其他终端的MAC地址,让交换机将去往该MAC的数据帧发给错误的端口
这种情况就可以使用MAC地址静态绑定防范
绑定方式:
# 绑定MAC地址
mac-address static 5489-98d0-3d34 GigabitEthernet 0/0/1 vlan 1
绑定MAC地址5489-98d0-3d34到g0/0/1,VLAN为1
对个人主机而言,静态MAC绑定非常麻烦并且没有价值,所以无需配置
对与服务器连接的二层端口而言,服务器位置固定且一般极具攻击价值,所以最好配置MAC地址静态绑定
黑洞MAC地址表项
mac-address blackhole 5489-98d0-3d34 {vlan 1}
设置5489-98d0-3d34为黑洞MAC
可选:指定vlan
黑洞MAC地址表项其实就是黑名单,丢弃源或目的MAC为该黑洞MAC的所有数据
限制MAC地址学习功能
还是由于交换机会主动学习收到数据的源MAC地址更新动态的MAC地址表项,如果有人不断变换自己的MAC地址向交换机发送数据,就会导致MAC地址泛洪攻击
MAC泛洪攻击:攻击者发送大量源MAC不同的数据帧,导致交换机无法正常转发数据帧,从而将数据帧全部泛洪
为了解决这个问题,可以有管理员手动限制或者关闭MAC地址的学习功能
限制MAC地址表的学习功能

MAC地址表安全的问题在于限制后只是进行告警,这样的后果就是查找麻烦,而且动作太少
比如拿集线器连接网口,扩展上网的设备,此时虽然交换机上学习的MAC多了,但MAC地址表安全只是告警却不禁止。如果网络中没有网管系统,网络管理员一人维护几百设备,除非正好登录了这个设备,否则连告警信息都看不到
所以一般不使用MAC地址表安全相关功能限制MAC地址学习数量
关闭MAC地址学习功能

限制或禁止MAC地址学习这个功能端口安全做的更好
端口安全
端口安全可以看做MAC地址表安全的升级版
端口安全相关措施和MAC地址表安全相关措施的思想一致,但是效果更好
交换机会主动学习数据包源MAC地址的特性会被非法利用
- MAC泛洪攻击:攻击者发送大量源MAC不同的数据帧,导致交换机无法正常转发数据帧,从而将数据帧全部泛洪
- MAC欺骗攻击:攻击者伪造网关或其他终端的MAC地址,让交换机将去往该MAC的数据帧发给错误的端口
MAC地址表安全可以解决上述问题,但是不够优秀。
端口安全可以有效的解决上述问题
端口安全开启命令
默认不开启端口安全
[Huawei]int g0/0/1
[Huawei-GigabitEthernet0/0/1]port-security enable
安全MAC转发表
当一个端口开启了端口安全后,原来的MAC地址表就会变成安全MAC转发表
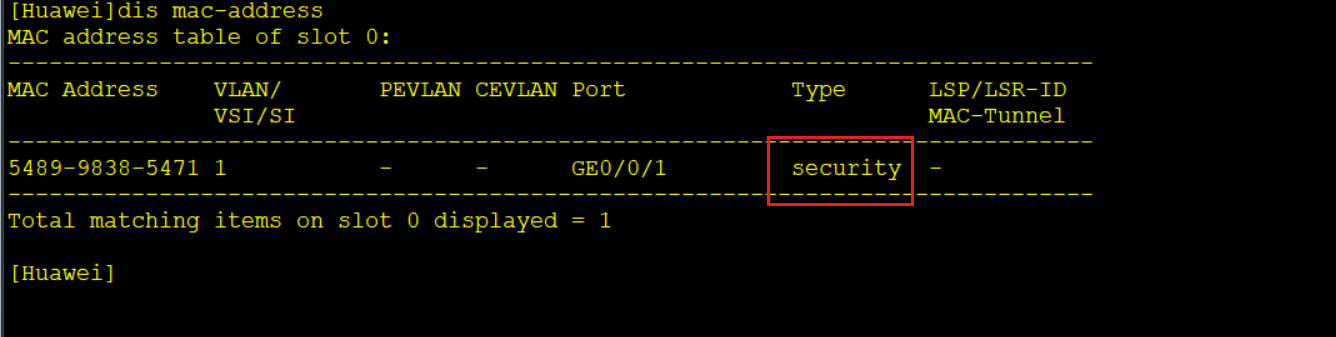
安全MAC地址表有【安全动态MAC地址表项】security 和【安全静态MAC地址表项】sticky
这两者的表现形式和【普通动态/静态MAC地址表项】完全一致
默认情况下:
- 开启端口安全的接口只允许学习一个MAC地址
- 学习到的MAC地址表项不会老化(包括安全动态地址表项)【前提:设备不重启,端口不down】
使用以下命令修改:
# 设置该端口允许学习的MAC表项条数
[Huawei-GigabitEthernet0/0/1]port-security max-mac-num 10
# 设置老化时间(安全动态表项的老化时间)
[Huawei-GigabitEthernet0/0/1]port-security aging-time 5 type ?
absolute Absolute time # 绝对老化
inactivity Inactivity time # 相对老化
[Huawei-GigabitEthernet0/0/1]port-security aging-time 5 type inactivity
设置老化时间为5分钟,老化模式为相对老化
老化时间有两个模式:
- 绝对老化:从第一次学习到一个MAC开始计时,到指定老化时间一定老化,中途再次学习到该MAC不会刷新老化时间
- 相对老化:从第一次学习到一个MAC开始计时,中途再次学习到该MAC,老化时间重新计时
安全MAC地址表静态绑定
和静态绑定的MAC表项一样,静态安全MAC地址表也不会随着交换机重启而丢失
绑定方式有两种:
# 绑定单个MAC地址
[Huawei-GigabitEthernet0/0/1]port-security mac-address sticky HH-HH-HH
# 绑定全部MAC地址(MAC地址粘滞绑定)
[Huawei-GigabitEthernet0/0/1]port-security mac-address sticky
- 单一绑定:手动MAC绑定到接口
- 粘滞绑定:交换机自动将此端口学习到的安全动态MAC全部静态绑定,直到MAC地址数达到设定的最大值
端口惩罚动作
如果端口MAC地址数达到设定的最大值,那么之后再有其他MAC经过就会执行惩罚动作,有三个动作
[Huawei-GigabitEthernet0/0/1]port-security protect-action ?
protect Discard packets # 丢弃数据
restrict Discard packets and warning # 丢弃数据并发送告警
shutdown Shutdown # shutdown端口
默认动作是restrict: 丢弃数据并发送告警
MAC地址表漂移的防止与检测
MAC地址表漂移的原理
MAC地址漂移指设备上一个接口学习到的MAC地址在同一VLAN中另一个接口上也学习到,后学习到的MAC地址表项覆盖原来的表项的现象。
正常情况下,网络中不会在短时间内出现大量MAC地址漂移的情况。出现这种现象一般都意味着网络中出现环路,形成广播风暴。【频繁MAC地址表漂移往往是环路的附带产物】
因此,可以利用MAC地址表漂移现象来监控网络中是否成环
防止MAC地址表漂移
网络中产生环路或者非法用户攻击网络都会导致MAC地址表漂移
有两种解决办法
1、修改接口上MAC地址学习优先级
- 当不同接口学习到相同的MAC地址时,高优先级接口学到的表项可以覆盖低优先级学到的表项
2、不允许相同优先级的同一MAC覆盖原有的表项
- 优先级相同:后学到的表项不允许覆盖先学习的表项
- 优先级不同:高优先级学到的表项可以覆盖低优先级学到的表项
防止MAC地址表漂移配置:
interface GigabitEthernet0/0/1
mac-learning priority 3 # 设置接口学习到MAC地址的优先级
undo mac-learning priority 0 allow-flapping # 不允许相同优先级的同一MAC覆盖原有的表项
MAC地址漂移检测
当交换机开启MAC地址漂移检测后,交换机可以察觉到MAC地址表学习接口的变化
如果察觉发生了MAC地址学习接口发生连续跳变现象,就认为发生了MAC地址表漂移
按检测的范围,MAC地址表漂移检测可以分为两种:
基于VLAN的MAC地址漂移检测
可以检测指定VLAN下的所有MAC地址是否发生漂移
可以指定发现漂移后的具体动作:
发送告警信息:默认,只发送告警不做其他处理
接口阻断:根据设定的阻塞时间对接口进行阻断,并关闭接口收发报文的能力
- 当指定block-mac参数时,将不阻断整个接口,而是按照发生漂移的MAC地址进行流量阻断。
MAC地址阻断:只阻塞发生漂移的MAC地址,接口下其他业务不受影响
全版本交换机都默认在全VLAN下开启了基于VLAN的MAC地址漂移检测
基于全局的VLAN地址漂移检测
可以检测设备上所有MAC是否发生了漂移
检测到漂移后只能发出告警
发现漂移后接口的动作
- error-down:将对应接口状态置为error-down,不再转发数据
- quit-vlan: 退出当前接口所属的VLAN
基于VLAN的MAC地址漂移检测配置
vlan 10 # 进入VLAN
loop-detect eth-loop ?
alarm-only 默认,仅发送告警
block-mac 可选,根据MAC地址阻断,不配置此选项就是根据接口阻断。
block-time 指定阻断时间。
retry-times 配置在block-time之后,指定接口永久阻断的重试次数
例如:loop-detect eth-loop block-mac block-time 10 retry-times 5
根据MAC地址阻断 阻断时间10s,重试次数5次
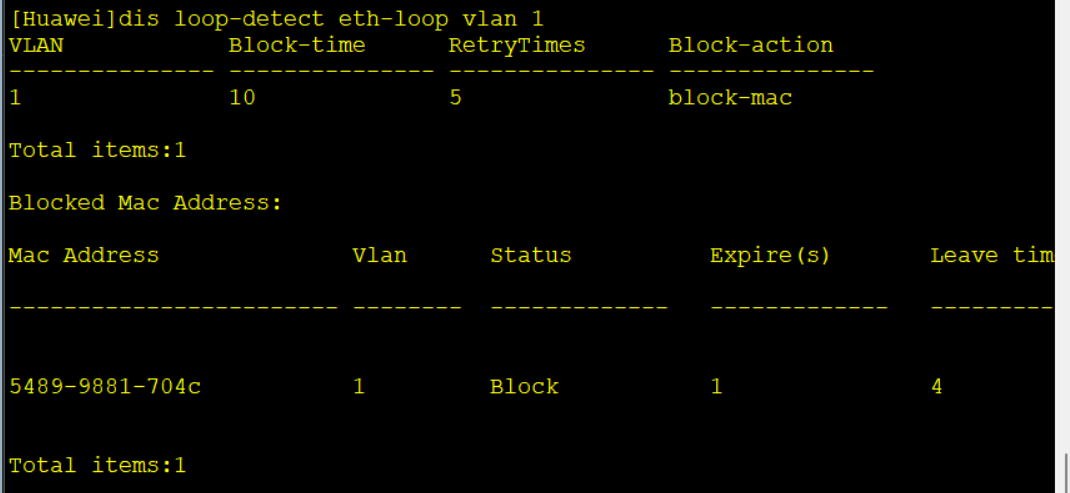
dis loop-detect eth-loop vlan [vlan-id] # 查看MAC阻断信息
reset loop-detect eth-loop vlan [id] {all | interface| mac-address} # 清除指定vlan下的MAC或接口阻断
当系统检测到某VLAN内有MAC地址发生漂移且发生漂移的接口或MAC地址被永久阻断时,只能通过配置解除指定VLAN下的接口阻断或MAC地址阻断来恢复到正常状态。
全局MAC地址漂移配置
系统视图:
mac-address flapping detection # 开启全局MAC地址漂移检测
# 在接口中配置动作,不做配置就只是告警
[Huawei-GigabitEthernet0/0/1]mac-address flapping trigger ?
error-down The interface was shutdown because of mac-flapping
quit-vlan The interface quit vlan because of mac-flapping
MACsec
同IPsec是提供了三成数据的加密传输,MACsec提供了二层的加密传输,但目前不常用
MACsec只有在对安全性要求非常高的网络中才有用武之地,一般的网络环境中并不需要MACsec
原理
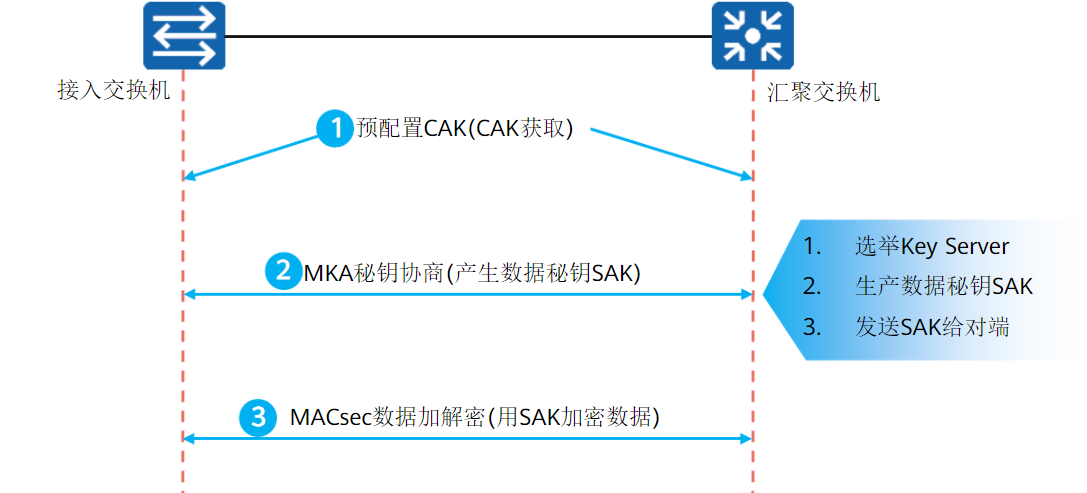
大致同IPsec,看IPsec就能明白MACsec的做法
配置:华为文档里我都没找到配置,略了,什么交换机支持了现查
交换机流量控制
当设备某个二层以太网接口收到广播、未知组播或者未知单播报文时,会向同一VLAN的所有接口发送这些报文
如果这个泛洪的报文流量很大,就会对现有的业务造成冲击,影响其他业务
注:上面的说法我不是很认可,但华为的ppt是如此说的
这里我很认可华为产品文档的说法:网络拥塞会导致丢包,流量控制是一种防止网络拥塞导致丢包的技术
为了解决这个问题,就需要对交换机的流量进行控制
交换机流量控制可以分为流量抑制和风暴控制
流量抑制
流量抑制主要通过配置阈值来限制流量,当超过阈值时,设备会丢弃超额的流量
简单说就是限速,超过规定速度的流量就直接丢掉让设备重发(并不是丢掉整个报文,而是丢掉超速的报文分片,从而让整体速度在阈值之下)
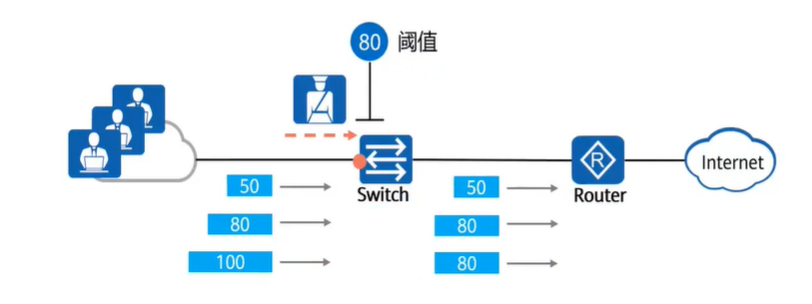
流量抑制的配置位置
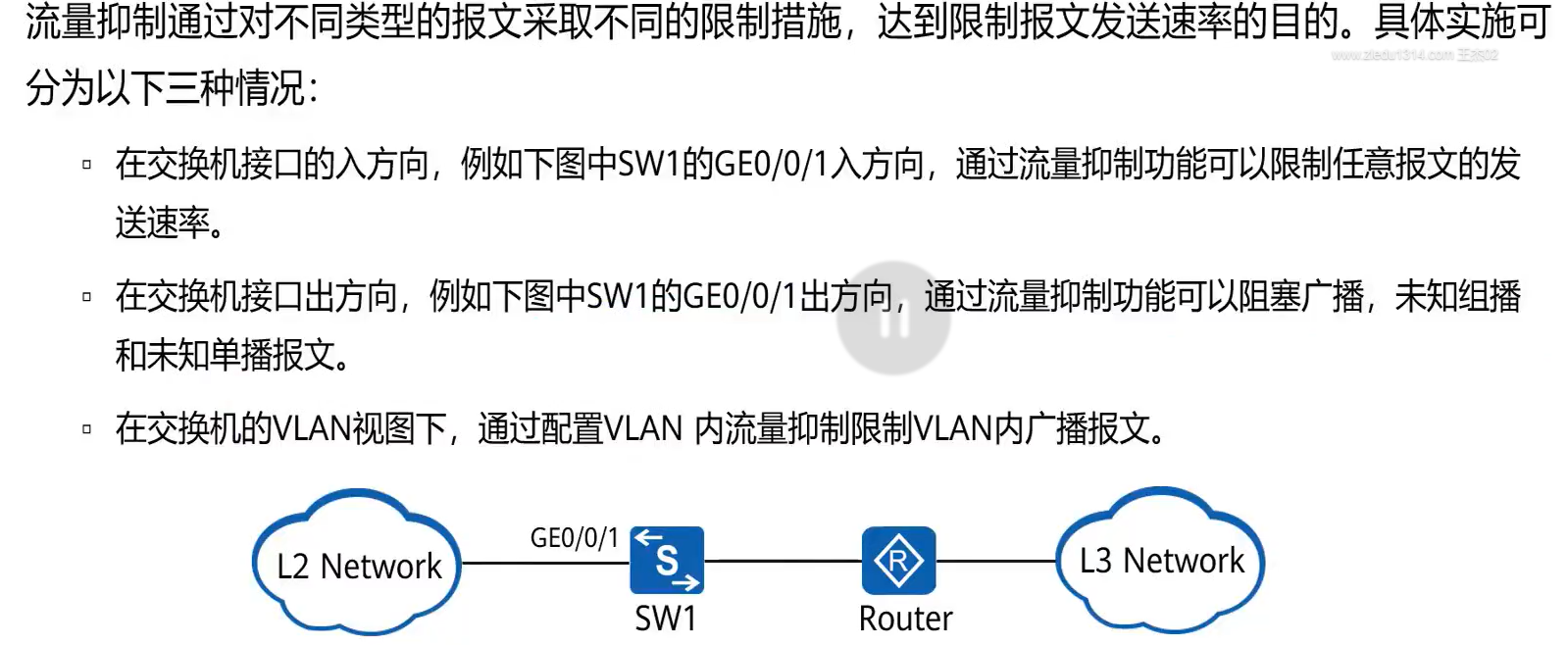
一般来说配置在入接口准没错
由于模拟器模拟不出大流量广播的场景,所以这里配置略
以后需要配置了查产品文档
风暴控制
风暴控制和流量抑制的原理相同,都是规定一个阈值,处理超过阈值的数据
但风暴控制的处理方式比流量抑制更加“极端”
- 流量抑制:丢掉超过规定速度的部分流量,并不是丢掉整个报文
- 风暴控制:只要超速,整个报文都丢掉,甚至关闭接口
风暴控制有两个动作
- 阻塞报文(Block):阻塞超速的整个报文
- 关闭接口(Error-down):关闭收到超速现象的接口
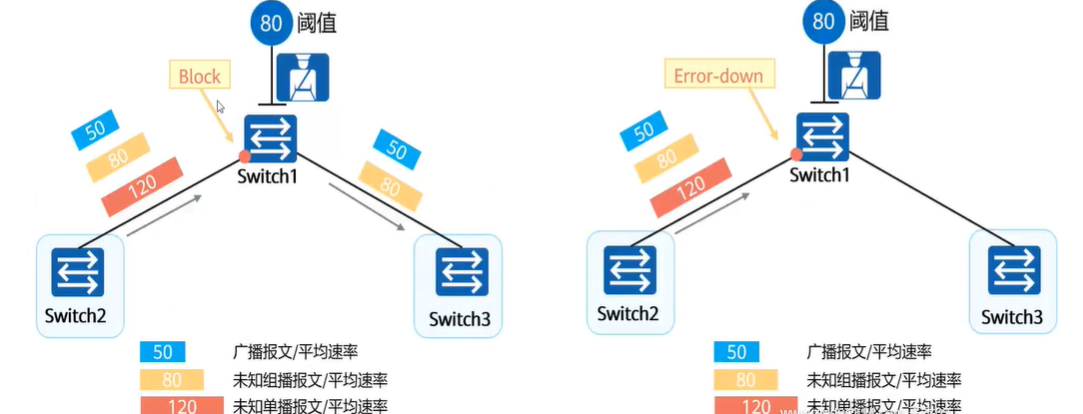
配置略
DHCP Snooping
DHCP Snooping 是DHCP的安全防范技术,用于保证DHCP客户端可以顺利从DHCP得到ip地址
由于DHCP在网络中的广泛应用,网络中也出现了很多针对DHCP的攻击,最常见的有四类:
DHCP Server仿冒者攻击:
DHCP Server 和 DHCP Client 之间没有认证机制,攻击者将自己伪造成DHCP服务器给其他网络设备分配IP地址和其他网络参数,如果伪造的DHCP服务器分配的IP地址是错误的,就会对网络造成很大的影响
解决方法:DHCP Snooping 信任功能
DHCP Server 拒绝服务攻击(DHCP 饿死攻击):
攻击者不断更改MAC地址或CHADDR,向DHCP服务器请求IP地址,使IP地址池中的地址耗尽。导致其他终端设备无法获取IP地址
解决方法:使能设备的DHCP Snooping功能后,配置设备接口允许接入的最大DHCP用户数,或者使用端口安全技术
DHCP 报文泛洪攻击:
攻击者向DHCP服务器发送大量的DHCP Discover报文,导致服务器无法处理正常的DHCP请求,严重时可能导致服务器瘫痪
解决方法:使能设备的DHCP Snooping功能时,同时使能设备对DHCP上送报文的速率检测
DHCP中间人攻击:
DHCP仿冒者攻击升级版,一边将自己伪造成DHCP服务器让正常客户端将DHCP各类消息发送给自己,一边伪造成正常客户端将收到的DHCP各类消息转发给正常的DHCP服务器。让自己成为一个“代理”,从而获取所有DHCP信息
解决方法:DHCP绑定表检查
DHCP Snooping 通过两种功能防止上述攻击
DHCP Snooping 信任功能
DHCP Snooping信任功能是通过将连接DHCP服务器的端口划入信任接口的方式防止DHCP中间人攻击和DHCP仿冒者攻击
DHCP Snooping将接口划分为信任接口和非信任接口
- 信任接口:正常转发收到的DHCP应答报文
- 非信任接口:接收到DHCP服务器响应的DHCP应答报文(DHCP Ack、DHCP Nak和DHCP Offer)后,丢弃该报文
默认的,除了设为信任接口的接口,其他接口都是非信任接口
配置信任功能
AR1上配置好DHCP
LSW1:
dhcp enable # 开启dhcp
dhcp snooping enable ipv4 # 使能dhcp snooping
接口使能DHCP Snooping
interface GigabitEthernet0/0/3 # 进入接口
dhcp snooping enable # 使能DHCP snooping
dhcp snooping trusted # 设置接口为dhcp snooping信任接口
VLAN使能DHCP Snooping
vlan 1 # 进入VLAN
dhcp snooping enable # 使能DHCP snooping
# 设置vlan1中的g0/0/1口为dhcp snooping信任接口
dhcp snooping trusted interface GigabitEthernet0/0/1
查看命令
display dhcp snooping global # 查看全局DHCP Snooping的信息
display dhcp snooping interface g0/0/1 # 查看接口下的DHCP Snooping信息。
DHCP Snooping 分析功能
DHCP Snooping分析功能会根据DHCP ACK报文生成DHCP绑定表
DHCP绑定表分两种:
- 动态绑定表:使能了DHCP Snooping功能后自动生成
- 静态绑定表:手动配置的
DHCP绑定表记录了DHCP客户端IP地址与MAC、租期、收到ACK报文的接口等信息
通过对报文和绑定表的匹配检查,可以有效防止DHCP攻击行为
DHCP饿死攻击比较特殊
由于DHCP分配IP时会根据MAC地址转换为
CHADDR参数,如果CHADDR值不同,就认为是不同的终端设备但是DHCP Snooping绑定表没有记录CHADDR
所以黑客通过伪造CHADDR值,可以绕过DHCP绑定表攻击服务器
防范方法:配置DHCP Snooping ,使能检查CHADDR和MAC的匹配关系
注意:DHCP Snooping分析功能只是生成了绑定表,并对收到的报文进行检查。但是检查到攻击之后的动作,是IPSG处理的
配置分析功能
开启DHCP Snooping功能后,默认生成绑定表,无需其他配置
display dhcp snooping user-bind {vlan 1} # 查看DHCP Snooping绑定表信息。
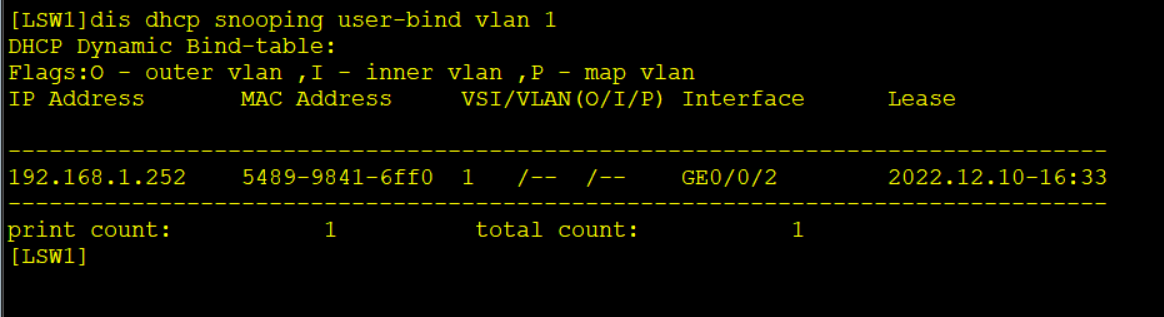
IPSG(IP Source Guard)
IPSG:IP源校验
IPSG是基于绑定表(DHCP Snooping 绑定表)检查二层接口收到的IP报文的安全验证技术
配置了IPSG的设备中,只有匹配绑定表的报文才允许通过,不匹配的报文将会丢弃
- 静态绑定表和动态Snooping绑定表都在IPSG的匹配范围内
默认的,如果只配置了IPSG但是没有开启绑定表(DHCP Snooping),设备将会拒绝除了DHCP报文外的所有报文
IPSG只能检测IP报文,非IP报文:ARP、PPPOE等无法匹配
IPSG接口角色
和DHCP Snooping一样,IPSG同样将接口分为信任接口和非信任接口
在配置了DHCP Snooping的情况下,DHCP Snooping信任接口就是IPSG信任接口,DHCP Snooping非信任接口就是IPSG非信任接口
- IPSG信任接口:信任接口收到的报文不会经过IPSG检查
- IPSG非信任接口:
- 接口使能IPSG:通过接口的报文将会经过IPSG检查
- 接口未使能IPSG:通过接口的报文不会经过IPSG检查
如果在VLAN中使能IPSG功能,该VLAN中的所有接口均使能IPSG功能
IPSG过滤方式
IPSG检查绑定表中的MAC地址、IP地址、VLAN ID、入接口四项
匹配静态绑定表时:四项全部检查
匹配动态绑定表时:缺省下四项全部检查,但管理员可以设置检查的组合
IPSG配置
开启DHCP静态或者动态绑定表后,IPSG默认没有配置
想要对被绑定表检查到的非法报文进行处理,就需要开启IPSG功能
IPSG基于接口或者基于VLAN都可以配置,并且配置大体相同
进入接口或者视图后
ip source check user-bind enable # 使能IPSG
ip source check user-bind check-item {vlan | interface} # 配置报文检查项
注:如果是静态绑定表项,无法手动配置检查项,所以静态绑定表项的IPSG不需要配置此项
ip source check user-bind alarm enable # 使能接口检查告警功能
ip source check user-bind alarm threshold 100 # 告警阈值,默认为100
检查相关命令
display ip source check user-bind {interface XX | vlan XX} # 检查接口或者VLAN下IPSG的配置信息
display nd snooping user-bind all [ verbose ] # 查看ND Snooping动态绑定表信息
# 带verbose参数可以查看到IPSG的状态。
RSTP&&MSTP
快速生成树协议(RSTP)
由于传统的STP协议存在收敛速度慢的问题,所以推出了RSTP(快速生成树协议)
RSTP的配置与传统STP完全一致,但是机制不同
传统的STP协议为了避免在拓扑还没有稳定下来就开启数据的转发导致环路问题
规定了两个15s的等待时间
Listening -> Learning :等待整个拓扑STP角色选举完毕
Learning -> Forwarding:等待整个拓扑mac地址表学习完毕
如今的网络设备处理能力得到了极大的增强,自然不需要等待15秒之久,stp淘汰
RSTP是基于传统STP的改进,相比于STP关注端口状态,RSTP更关注端口的角色
RSTP改进点
端口角色
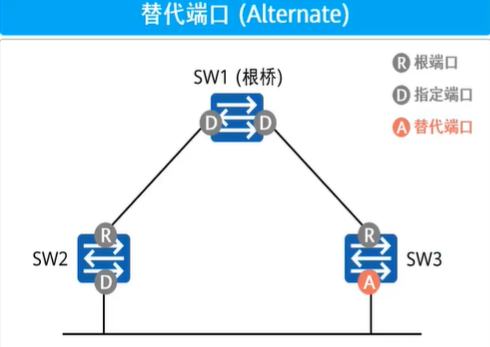
RSTP将阻塞端口AP分为了两种端口角色
注:任何生成树,都是先选端口角色,然后再到达对应的转发状态
给一个RSTP域内所有端口分配角色的过程就是整个拓扑收敛的过程。
替代端口(Alternate):替代端口作为设备根端口
RP的的备份,当设备上的根端口连接链路断开时替代端口立即成为根端口,无需进行状态跃迁- 替代端口提供从设备到根的备用路径
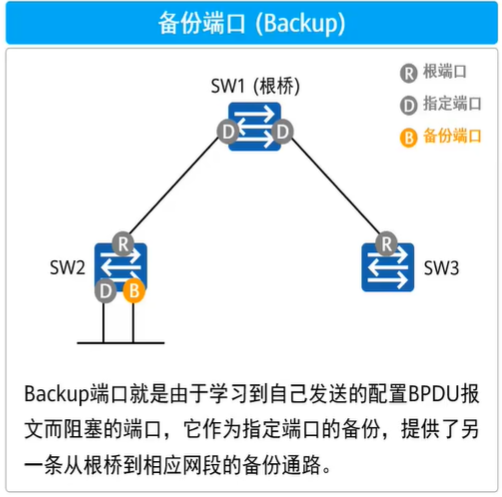
备份端口(Backup):备份端口是设备指定端口
DP的备份,当设备指定端口出现故障时,备份端口立即成为指定端口而无需进行状态跃迁备份是自己连自己造成的阻塞,一般不会出现。
常见的情况有:两条线连接同一个集线器成环;一条线连接设备的两个端口成环
端口状态
RSTP更加关注端口的角色,所以将STP五种状态降为三种
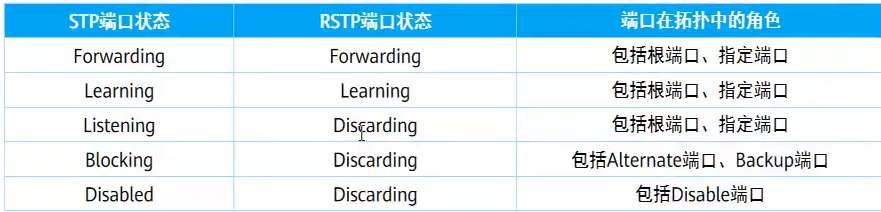
- Discarding:不转发流量也不学习MAC地址的端口
- Learning:不转发用户流量但是正在学习MAC地址的端口(这是一个过程,端口不会一直停留在此状态)
- Forwarding:即转发用户流量又学习MAC地址的端口
由于P/A机制存在,RSTP的状态跃迁是秒级收敛的,如果P/A机制失效,则仍然进行传统STP的30秒收敛
BPDU报文

RSTP对BPDU报文的利用更加高效
- 改进后的配置BPDU称为RST - BPDU
- RST - BPDU由于改变了Type字段,传统的STP不兼容RSTP(STP中Type=1是配置BPDU,Tpye=2是TCN BPDU。RSTP 的配置BPDU的Tpye=3)
拓扑中不再只有根桥才会发送配置BPDU,拓扑稳定后,无论根桥设备是否传来BPDU,非根桥都会按照Hello Time的时间间隔(2s)从指定端口发送配置BPDU
如果一个根端口在三个Hello Time周期(Hello time * 3 = 6s)内没收到配置BPDU,就认为本设备与邻居断开,于是Alternate端口立即成为根端口,进入Forwarding状态。然后RSTP网络进行RST BPDU泛洪
当一个端口收到上游的指定桥发来的RST BPDU报文时,该端口会将自身存储的RST BPDU与收到的RST BPDU进行比较。
如果该端口存储的RST BPDU的优先级高于收到的RST BPDU,那么该端口会直接丢弃收到的RST BPDU,立即回应自身存储的RST BPDU。
P/A机制
P/A机制是实现RSTP快速收敛而无需等待的关键,P/A带来了来回确认机制和同步变量机制,不再需要等待计时器超时来保障无环路。
P/A机制前提:
- DP端口处于Discarding状态
- 该DP端口所在链路是点到点全双工链路
P/A机制选举过程
初始状态,链路两端均认为自己是DP(指定端口),发送
RST BPDU收到更优
RST BPDU报文的一端(下面简称”本端”)意识到自己会成为RP/AP,所以停止发送BPDU如果设备其他接口已经收到了BPDU并且已经成为RP,此时本接口收到的BPDU没有RP接口收到的优秀,则本接口成为AP。此时链路两端为AP和DP,环路中P/A机制结束
收到不如本地
RST BPDU优秀的一端(下面简称”对端”)变为Discarding状态,发送P、A都置位的RST BPDU本端收到
P置位的RST BPDU,所有端口进入sync变量置位sync变量置位:收到
P置位RST BPDU的端口进入Forwarding状态,其他除阻塞、边缘端口以外的所有端口进入Discarding状态本端向对端回应
A置位的RST BPDU,对端收到后,进入Forwarding状态P/A机制向下游逐跳重复此过程,终止于存在DP和AP的链路上。
P/A机制实现了STP秒级收敛
一旦P/A协商不成功,指定端口的选择就需要等待两个Forward Delay,协商过程与STP一样。
边缘端口
如果某一个指定端口位于整个网络的边缘,即不再与其他交换设备连接,而是直接与终端设备直连,这种端口叫做边缘端口。
由于STP/RSTP协议的特性,一旦网络中topo发生变化,生成树就需要重新进行角色选举
所以当网络主接入一台不参与STP/RSTP的设备时(终端、路由器等),该设备连接的端口同样需要角色选举
由于P/A机制,运行RSTP的端口发送BPDU给不运行RSTP的设备,并等待回复
但不运行RSTP的设备明显不能回复,所以交换机端口等待三个Hello Time周期后将自己变为DP
相当于浪费6s时间
边缘端口不参与RSTP计算,直接成为DP,节约了6s的收敛时间
[Huawei-GigabitEthernet0/0/1]stp edged-port enable # 设备为边缘端口
一旦边缘端口收到配置BPDU,就丧失了边缘端口属性,成为普通STP端口,并重新进行生成树计算,从而引起网络震荡。
拓扑变更机制
一旦有非边缘端口迁移到Forwarding状态,RSTP视为拓扑变更
将进行以下操作
- 为本设备所有的非边缘端口启动一个
TC While Time,该计时器是Hello Time的两倍(4s)- 在一个
TC While Time内,清空端口上学习的MAC地址 - 在一个
TC While Time内,由非边缘端口向外发送RST BPDU,其中TC置位
- 在一个
- 其他设备收到TC置位的RST BPDU后,清空出接收端口外所有端口的MAC地址,自己同样启动一个
TC While Time,重复上述操作
RSTP保护功能
BPDU保护
设置为边缘端口的接口,一旦收到BDPU,就会自动将端口更改为非边缘端口并重新进行生成树的计算
所以如果有人伪造RST BPDU攻击设备,就会引发网路震荡
启动BPDU保护后,如果边缘端口收到BPDU会立即置为error down状态并通知网管系统,但不会更改为非边缘端口
stp bpdu-protection
根保护
根保护确保根桥不会因为一些网络问题而改变,比如收到恶意攻击者伪造的更优BPDU
根保护功能只有指定端口可以开启,启用Root保护功能的指定端口,其端口角色只能保持为指定端口。
开启根保护功能的端口收到更优BPDU时进入Discarding状态并不再转发报文,如果在两倍Forward Delay时间里一直没有收到优先级更高的配置BPDU,指定端口恢复正常转发状态
int g0/0/1 # 进入接口视图
stp root-protection # 配置根保护
配置根保护的端口不能配置环路保护
环路保护
环路保护功能只能在根端口或Alternate端口上配置生效。
如果链路上单向链路故障,替代端口认为链路故障变为根端口,此时网络中没有了阻塞端口,网络发生环路
开启环路保护功能后,如果根端口或阻塞端口长时间收不到BPDU时,向网管发送信息,角色切换为指定端口并进入Discarding状态,直到故障恢复
int g0/0/1
stp loop-protection # 使能环路保护
防止TC-BPDU置位攻击
根据RSTP特性,当拓扑发生改变时,设备发送TC置位的BPDU使链路重新学习MAC地址
但如果有攻击者伪造TC置位报文,就会导致设备频繁删除MAC地址表
启用防TC置位攻击功能后,可以配置单位时间内设备处理TC置位报文的次数
多生成树协议(MSTP)
STP/RSTP的原理是选一个最差的端口将其阻塞。这意味这网络中有链路被浪费
为了解决浪费问题,提出了MSTP
方法就是再一个环路中运行多个生成树(可以是STP/RSTP/MSTP的任意一种),生成树之间彼此独立。每个生成树阻塞不同的链路
默认MSTP实例中运行RSTP
MSTP将一个或者多个vlan映射到一个instance实例,再基于此实例计算生成树,同一实例的vlan使用同一生成树每棵生成树叫做一个多生成树实例MSTI,每个域叫做一个MST域。
每个VLAN只能对应一个MSTI,而一个MSTI可能对应多个VLAN。
配置
stp region-configuration # 进入MST域
region-name STP # 设置域名
revision-level 12 # 设置域等级
instance 1 vlan 10 30 # 将vlan 10 20 划入实例1
instance 2 vlan 20 # 将vlan 20 划入实例2
active region-configuration # 提交此配置
stp instance 1 root primary # 设置此交换机为实例1的主根
stp instance 2 root secondary # 设置此交换机为实例2的备用根
- MSTP中同属一个域的实例在同一个MSTP网络中,对单域MSTP网络来说,所有MSTP交换机必须在同一个域中
- 域名和域等级唯一标识一个MSTP域
- 默认的,同一型号的设备拥有相同的域名和域等级
由于同一型号的设备默认拥有相同的域名和域等级,所以region-name和region-level两个参数一般可以不用配置。但为了便于后期维护,最好配置一个值
当域设置错误时,接口状态为MAST
堆叠和集群
堆叠(iStack)【华三中称为(IRF)】和集群(CSS),同MSTP、VRRP、链路聚合等技术一样,都是用于提高网络可靠性的技术
做法是将复数设备堆叠为一台逻辑设备使用,堆叠后在堆叠系统中的任意设备都拥有系统内所有设备的接口以及资源
基本概念
盒式交换机的堆叠称为堆叠,最多可以支持8台设备
框式交换机的堆叠称为集群,有且只能有两个框式交换机集群
堆叠和集群除了应用的对象和配置命令有所区别,原理都一样
堆叠系统的角色
堆叠系统中一共有三个角色
1、主交换机(Master):管理整个堆叠系统的交换机,堆叠中只能有一台主交换机
2、备交换机(Standby):主交换机的备用,当主交换机故障时变为主交换机,堆叠中只有一台备交换机
3、从交换机(Slave):除主备交换机外的所有交换机都是从交换机
备交换机故障时由主交换机在从交换机中重新选举备交换机
堆叠ID
堆叠ID(Slot ID)是堆叠系统中成员交换机的槽位号,堆叠ID唯一确定堆叠系统中的一台成员交换机
- 在
G1/0/2这个端口编号中,1就是交换机的槽位号,2是端口编号
堆叠优先级
堆叠优先级用于选举堆叠系统中成员交换机的角色
堆叠选举原则:
堆叠系统中先启动的设备为主设备
如果系统中设备同时启动(启动时间差20s内都算同时启动),则优先级值大的为主设备
如果优先级值相同,则MAC地址小的为主设备
备交换机选举规则和主交换机一致,在主交换机选举完成后进行选举
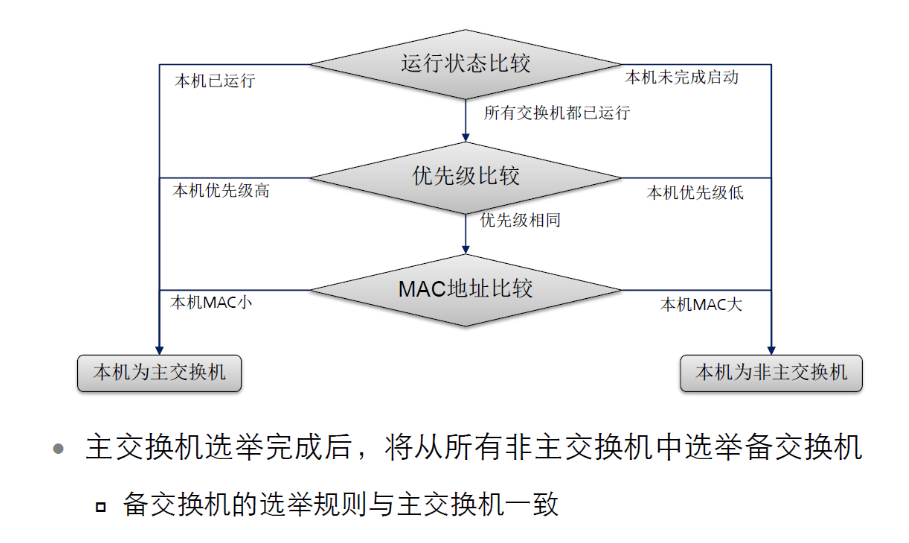
初次启动堆叠系统最好先做好各成员交换机堆叠配置,然后连接堆叠线缆
如果先连接线缆再配置,按原则1,先配好堆叠并且启动的会称为主交换机。后续优先级无需比较
堆叠系统建立
- 物理连接:根据网络需求,选择适当的连接方式和连接拓扑,组建堆叠网络。
- 主交换机选举:成员交换机之间相互发送堆叠竞争报文,并根据选举原则,选出堆叠系统主交换机。
- 拓扑收集和备交换机选举:主交换机收集所有成员交换机的拓扑信息,向所有成员交换机分配堆叠ID,之后选出堆叠系统备交换机。
- 稳定运行:主交换机将整个堆叠系统的拓扑信息同步给所有成员交换机,成员交换机同步主交换机的系统软件和配置文件,之后进入稳定运行状态。
成员交换机同步主交换机系统时会重启
设备堆叠ID缺省为0。堆叠时由堆叠主对设备的堆叠ID进行管理,当堆叠系统有新成员加入时,如果新成员与已有成员堆叠ID冲突,则堆叠主从0~最大的堆叠ID进行遍历,找到第一个空闲的ID分配给该新成员。
- 因此如果不手动指定堆叠ID,由于启动顺序等原因,最终堆叠系统中各成员的堆叠ID是随机的
堆叠ID和优先级都应在启动堆叠系统前配置好,主交换机自动分配对运维不友好
物理连接的方式
堆叠系统可以通过两种接口连接:
专用的堆叠口以及堆叠线缆连接
支持堆叠的设备一般会有两个堆叠口和配套的堆叠线缆,专用的堆叠口也称堆叠卡
逻辑堆叠口绑定业务口(网线接口)连接
如果没有堆叠线缆,可以手动创建逻辑堆叠口,然后绑定业务口进行堆叠
- 有且只能创建两个逻辑堆叠口
- 一个逻辑堆叠口可以绑定多个业务接口
无论是堆叠卡还是逻辑接口,一个设备有且只能有两个堆叠接口
连接时,堆叠设备之间要交叉连接,即设备A堆叠1口连接设备B堆叠2口
物理连接拓扑结构
| 连接拓扑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 链形连接 | 首尾不需要有物理连接,适合长距离堆叠。 | 可靠性低:其中一条堆叠链路出现故障,就会造成堆叠分裂。堆叠链路带宽利用率低:整个堆叠系统只有一条路径。 | 堆叠成员交换机距离较远时,组建环形连接比较困难,可以使用链形连接。 |
| 环形连接 | 可靠性高:其中一条堆叠链路出现故障,环形拓扑变成链形拓扑,不影响堆叠系统正常工作。堆叠链路带宽利用率高:数据能够按照最短路径转发。 | 首尾需要有物理连接,不适合长距离堆叠。 | 堆叠成员交换机距离较近时,从可靠性和堆叠链路利用率上考虑,建议使用环形连接。 |
堆叠系统的管理
由于堆叠的本质就是将多个设备在逻辑上作为一台设备使用,并且使用成员交换机的所有资源
不管通过哪台成员交换机登录到堆叠系统,实际登录的都是主交换机。以此管理整个堆叠系统
跨设备的链路聚合与流量优先转发
由于堆叠系统中的设备在逻辑上一台设备,自然可以通过Eth-Trunk口和其他设备之间链路聚合
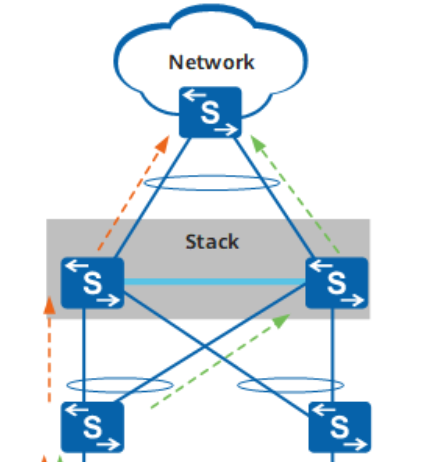
由于链路聚合有负载分担的特性,有时流量会形成次优路径通过堆叠口传输数据,所以需要启动流量优先转发
即从本设备进入的流量,优先从本设备相应的接口转发出去。如果本设备无出接口或者出接口全部故障,才会从其它成员交换机的接口转发出去。
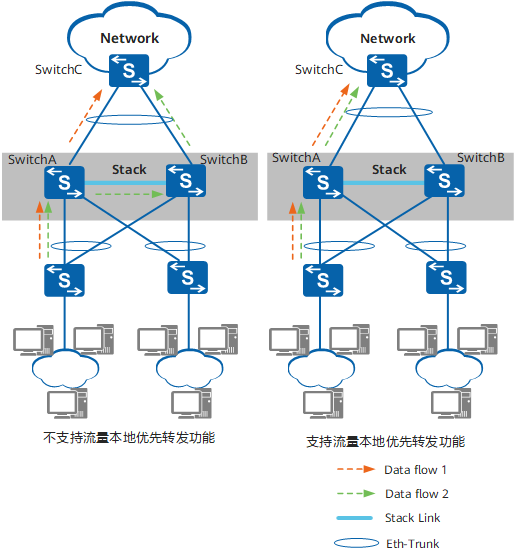
具体怎么配置,华为没说
堆叠成员的加入和退出
堆叠成员加入分为新成员交换机带电加入和不带电加入
新成员交换机加入堆叠系统时,建议使用不带电加入
不带电加入
- 新加入的交换机连线上电启动后,由于选举原则1(启动顺序),会选举为从交换机,堆叠系统中原有主备从角色不变。
- 主交换机更新堆叠拓扑信息,并同步到其他交换机,然后向新交换机分配堆叠ID(如果没有手动配置堆叠ID)
- 新加入的交换机同步堆叠系统,重启,进入稳定运行状态
带电加入
带电加入也称为堆叠合并,指两个堆叠系统合并为一个堆叠系统
- 两个堆叠系统的主交换机竞争,选举出一个更优的主交换机。
- 竞争失败的堆叠系统所有成员交换机重启,加载新的系统
- 新主交换机更新拓扑,同步到所有成员交换机
通常不建议带点加入,因为可能导致正在运行业务的设备重启,导致业务中断
堆叠成员退出
根据交换机角色不同,对堆叠系统的影响不同
1、主交换机退出
- 备份交换机升为主交换机,重新计算拓扑同步到其他交换机
- 指定新的备交换机
2、备交换机退出
- 主交换机重新计算拓扑同步到其他交换机
- 主交换机指定新的备交换机
3、从交换机退出
- 主交换机重新计算拓扑同步到其他交换机
堆叠的分裂和多主检测
堆叠分裂
不正常的成员交换机退出,称为堆叠分裂,指稳定运行的堆叠系统中带电移出部分成员交换机,或者堆叠线缆多点故障导致一个堆叠系统变成多个堆叠系统。
根据原堆叠系统主备交换机分裂后所处位置的不同,堆叠分裂可分为以下两类:
- 原主备交换机被分裂到同一个堆叠系统中
- 将移出的成员交换机的拓扑信息删除,并将新的拓扑信息同步给其他成员交换机
- 移出的成员交换机检测到堆叠协议报文超时,将自行复位,重新进行选举
- 原主备交换机被分裂到不同的堆叠系统中
- 原主交换机所在堆叠系统重新指定备交换机,重新计算拓扑信息并同步给其他成员交换机
- 原备交换机所在堆叠系统将发生备升主,原备交换机升级为主交换机,重新计算堆叠拓扑并同步到其他成员交换机,并指定新的备交换机。
由于堆叠系统中所有成员交换机都使用同一个IP地址和MAC地址(堆叠系统MAC),一个堆叠分裂后,可能产生多个具有相同IP地址和MAC地址的堆叠系统。从而导致网络故障。
MAD多主检测
MAD(多主检测) 的目的是为了在发生堆叠分裂时最大程度的减少损失
链路故障导致堆叠系统分裂后,MAD可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。
MAD有两种检测方式
1、直连检测
堆叠系统分裂后,分裂后的两台交换机以1s为周期通过检测链路发送MAD报文进行多主冲突处理
通过中间设备直连:
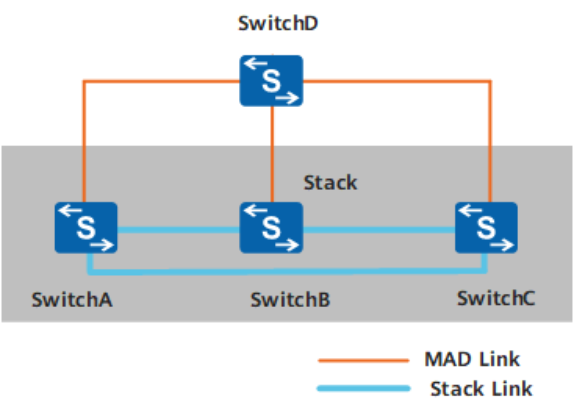
通过一台交换机作为中转连接所有成员交换机,优点是节省线路和接口,缺点是多费一台交换机
Full-mesh(全互联)方式直连:
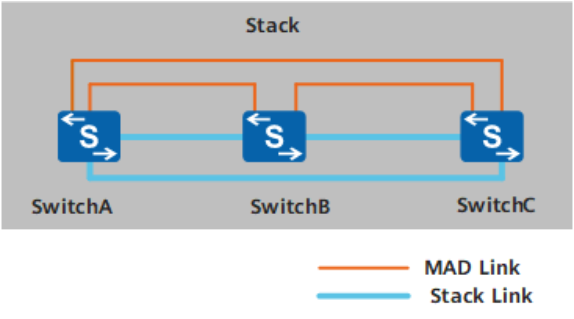
直接通过业务口使成员交换机全互联,优点是省钱,缺点是费接口
直连检测的两种方式没有直接区别,设备少或设备之间距离近优先考虑全互联,设备多或设备之间距离远有点考虑中间设备互联
接口配置直连多主检测功能后,不能再配置其他业务。
2、代理检测
代理检测方式是在堆叠系统Eth-Trunk上启用代理检测,在代理设备上启用MAD检测功能。此种检测方式要求堆叠系统中的所有成员交换机都与代理设备连接,并将这些链路加入同一个Eth-Trunk内。
与直连检测方式相比,代理检测方式无需占用额外的接口,Eth-Trunk接口可同时运行MAD代理检测和其他业务【就是说两个堆叠系统之间可以相互代理】。
在代理检测方式中,堆叠系统正常运行时,堆叠成员交换机以30s为周期通过检测链路发送MAD报文。
堆叠成员交换机对在正常工作状态下收到的MAD报文不做任何处理;堆叠分裂后,分裂后的两台交换机以1s为周期通过检测链路发送MAD报文进行多主冲突处理。
单机代理
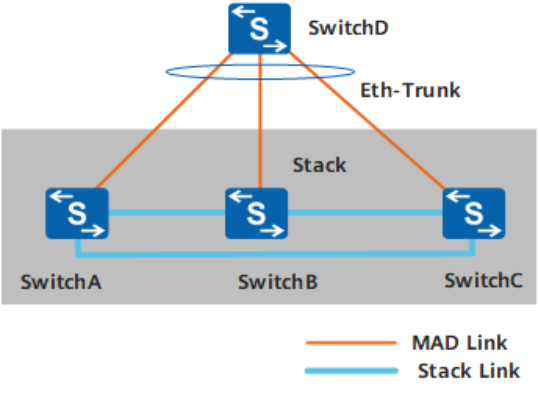
使用一台设备通过Eth-Trunk口进行代理检测
两套堆叠系统互为代理
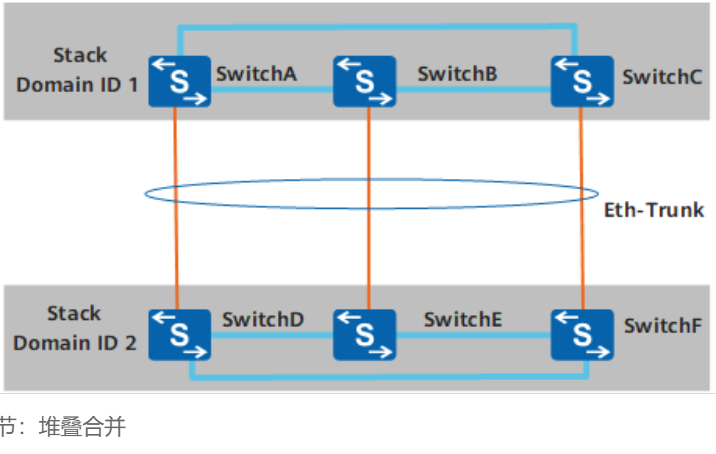
MAD多主检测原理
堆叠分裂后,MAD冲突处理机制会使分裂后的堆叠系统处于Detect状态或Recovery状态。
Detect状态表示堆叠正常工作状态,Recovery状态表示堆叠禁用状态。
MAD冲突处理机制如下:
MAD分裂检测机制会检测到网络中存在多个处于Detect状态的堆叠系统,这些堆叠系统之间相互竞争
竞争成功的堆叠系统保持Detect状态,竞争失败的堆叠系统会转入Recovery状态
在Recovery状态堆叠系统的所有成员交换机上,关闭除保留端口以外的其它所有物理端口,以保证该堆叠系统不再转发业务报文。
堆叠升级
堆叠升级主要就是平滑升级值得一提,其他的就是该咋升级就咋升级
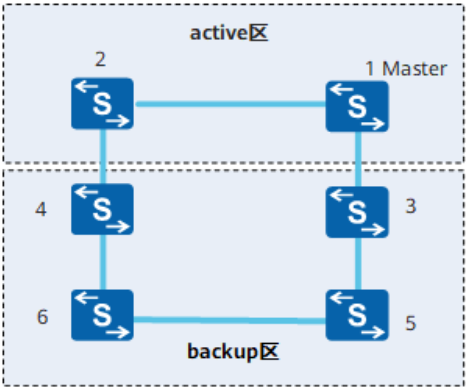
将成员交换机分为两个区域,从交换机在backup区,主交换机在active区
先升级backup,让active转发业务流量,然后升级active,让backup转发业务流量
平滑升级分三个阶段:
- 主交换机下发命令触发整个堆叠系统进入平滑升级状态,backup区各个成员交换机以新的系统软件进行启动。
- backup区以新版本建立一个独立的堆叠系统,并通知active区进入升级阶段,主控权由active区的主交换机转移到backup区的主交换机,backup区负责流量传输,active区进入升级过程。
- active区以新系统软件重新启动并加入backup区的堆叠系统,backup区的主交换机根据最终堆叠建立的结果发布升级的结果。
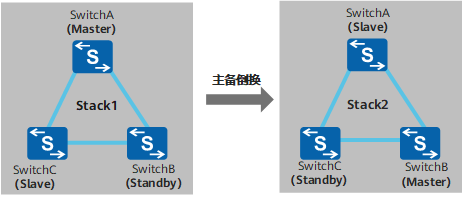
主备倒换
堆叠主备倒换包括主交换重启引起的主备倒换和通过命令行执行的主备倒换。
主备倒换后:
- 原来的备交换机升为主交换机。
- 新主交换机重新指定备交换机。
- 原来的主交换机重启后重新加入堆叠系统,并被选举为从交换机。
堆叠的配置
修改设备的堆叠id(华三默认为1)
配置设备的堆叠优先级,优先级(值)越大越优先,缺省100
配置逻辑堆叠接口(有专门的堆叠口则不用配置,堆叠口必须是1口连接2口【交叉相连】)
【配置前需要先关闭对应的物理接口】
保存配置、关闭设备
连接堆叠线缆并重启设备【配置堆叠时最好先配置完毕再连线、否则堆叠主设备可能选举不正确(堆叠选举原则)】
华三交换机配置:
# 关闭要绑定到逻辑堆叠口的物理接口
int te1/0/49
sh
int te1/0/50
sh
qui
irf member 1 renumber 2 # 设置堆叠ID
irf member 1 priority 1 # 设置堆叠优先级(因为设置的ID还没启动,所以还是修改1的优先级)
irf-port 1/1 # 创建堆叠接口1/1,第一个1是堆叠ID
# 绑定物理接口
port group interface Ten-GigabitEthernet1/0/49
irf-port 1/2 # 创建堆叠接口1/2
port group interface Ten-GigabitEthernet1/0/50
# 开启设置好的物理接口
int te1/0/49
un sh
int te1/0/50
un sh
华为交换机配置
由于华为ensp模拟器无法做堆叠,只能先把命令贴上来
大体上还是和华三一致,只不过一个叫做irf,一个叫做stack
stack slot 0 renumber 1 # 设置堆叠ID,缺省情况下,华为设备的堆叠ID为0
stack slot 0 priority 2 # 设置堆叠优先级
interface stack-port 0/1 # 创建堆叠接口
port interface g0/0/24 enable # 绑定物理接口
其他命令
slave switchover # 执行堆叠主备倒换
stack timer mac-address switch-delay 60 # 堆叠系统MAC切换时间
undostack timer mac-address switch-delay # 立即切换MAC
reset stack configuration # 清楚堆叠所有配置
配置MAD多主检测
直连检测与单设备代理检测

堆叠系统代理检测
集群的配置
集群是框式交换机的堆叠,所以其思想和堆叠一致,不过是盒式交换机换成了框式交换机
角色从主备从变为一主一备
set css [id] [new-id] # 配置集群ID,缺省情况下,交换机的集群ID都为1
set css priority 1 # 配置集群优先级,缺省集群优先级为1
interface css-port 1 # 创建集群逻辑接口
port interface g0/0/1 enable # 绑定物理接口
css enable # 交换机使能集群功能,缺省情况下,交换机的集群功能未使能
set css mode {lpu | css-card} # 设备的集群连接方式,缺省情况下设备的集群连接方式与设备型号相关
OSPF高级技术
OSPF基础
OSPF是链路状态路由协议的一种,将AS(自治系统)划分为一个或多个逻辑区域
OSPF通过在广播域内泛洪LSA(链路状态通告)的形式发布路由,为了减少LSA在广播域内的交换,广播网络中的OSPF需要确立DR/BDR
P2P链路为非广播型网络,所以不需要确定DR/BDR
OSPF协议所谓的自治系统和BGP自治系统是不同的概念
OSPF自治系统 : 使用相同路由协议来计算路由的一组路由器集合
OSPF报文结构
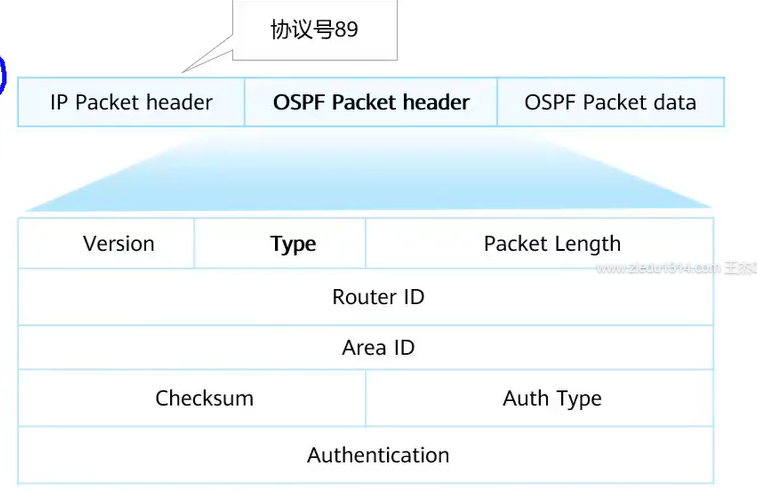
OSPF报头结构如图(OSPF Packet header)
Type:OSPF报文类型,声明OSPF Packet data携带的是什么报文Auth Type: 认证类型,置0时表示无需认证Authentication:认证密码,没有认证时全0
OSPF Packet data是具体的报文数据,如IA所学,有五种hello、DD、LSR、LSU、LSACK
OSPF网络类型(接口链路类型)
OSPF支持四种网络类型:Broadcast、P2P、P2MP、NBMA
由于P2MP、NBMA已经淘汰,不做探究
Broadcast:广播型多路访问网络- 当链路为以太网或FDDI时,默认情况下,OSPF为广播网络
- 以组播形式发送
HELLO报文,以单播形式发送DD报文和LSR报文,以组播或单播形式发送LSU、LSACK报文 HELLO报文发送间隔时间10s,邻居失效时间40s
P2P:点到点网络- 当链路为PPP或HDLC时,默认情况下,OSPF为点到点网络
- 以组播形式发送
HELLO、DD、LSR、LSU、LSACK报文 HELLO报文发送间隔时间10s,邻居失效时间40s
HELLO报文结构

Network Mask:子网掩码
Hello Interval:发送Hello报文的时间间隔
- 华为默认为10s、思科默认为15s
Options:OSPF 选项
- 共有
E、MC、N/P三种

Route-Priority:DR优先级,默认为1
RouteDeadInterval:OSPF邻居失效时间
- 如果在一个失效时间内都没有收到新的Hello,则认为邻居失效,默认为40s
Designated Router: DR接口地址
- 初始状态下,广播域中每个接口都认为自己是DR,该字段是自己的接口地址
- 华为产品文档说初始状态是自己接口地址,但模拟器抓包结果全0,应该是文档更权威些
Backup Designated Router:BDR接口地址
- 初始状态为
0.0.0.0
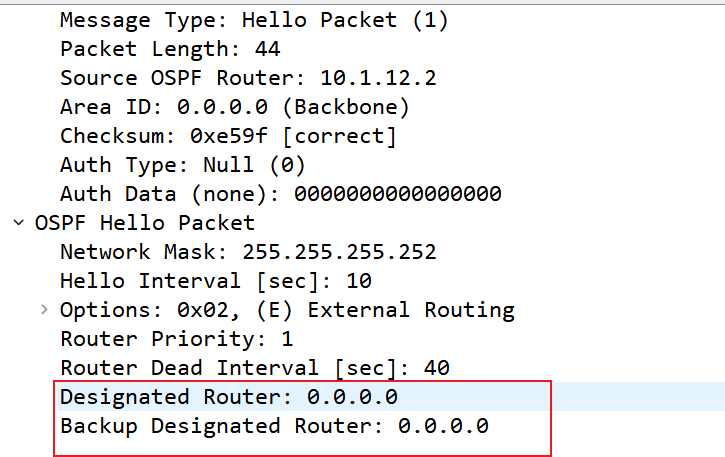
Neighbor:邻居地址
- 没有邻居时该字段为空
- OSPF 设备收到邻居
HELLO报文后,会将邻居Route-id写入Neighbor字段
OSPF报文交互过程
在广播网络中OSPF交互过程:
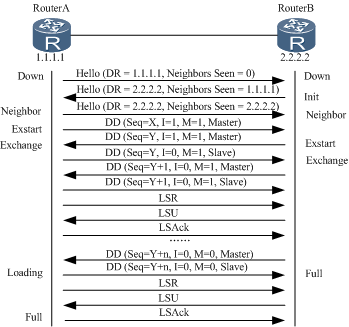
如上图,可知广播网络中DR/BDR通过
Hello报文选举并维护,LSA交换的主从通过DD选举
在点到点网络中建立OSPF邻接关系
在点到点网络中,邻接关系的建立过程和广播网络一样。
不同之处在于不需要选举DR和BDR,DD报文是组播发送的。
具体参考华为产品文档
OSPF 路由器角色
| 路由器类型 | 含义 |
|---|---|
| 区域内路由器 (Internal Router) |
该类设备的所有接口都属于同一个OSPF区域。 |
| 区域边界路由器ABR (Area Border Router) |
该类设备可以同时属于两个以上的区域,但其中一个必须是骨干区域。ABR用来连接骨干区域和非骨干区域,它与骨干区域之间既可以是物理连接,也可以是逻辑上的连接。 |
| 骨干路由器 (Backbone Router) |
该类设备至少有一个接口属于骨干区域。所有的ABR和位于Area0的内部设备都是骨干路由器。 |
| 自治系统边界路由器ASBR(AS Boundary Router) | 与其他AS交换路由信息的设备称为ASBR。ASBR并不一定位于AS的边界,它可能是区域内设备,也可能是ABR。 只要一台OSPF设备引入了外部路由的信息,它就成为ASBR。 NSSA区域执行7类转5类的ABR也是ASBR |
ASBR的自治系统非BGP所说的自治系统
邻居/邻接关系建立的条件
Router-id一致- 广播域中所有接口区域号一致
- 广播域中所有接口认证类型一致,认证密码一致
- 广播域中所有接口ip地址在同一网段,并且掩码一致
- 广播域中所有接口MTU一致(华为默认不开启MTU检测,思科开启,默认1500)
- MTU不一致,状态停留在
Exstart,邻接关系无法建立,但不影响邻居关系建立 - 收到的DD报文MTU值小于自身接口MTU,则接收
- 收到的DD报文MTU值大于自身接口MTU,则丢弃
- 不开启检测,发送的报文中MTU为0,自身不对MTU进行检查
- MTU不一致,状态停留在
- Option字段E比特和N比特置位一致
- Hello报文发送时间和Dead时间一致
- 华为Hello发送间隔10s,思科15s
- Dead【邻居死亡时间】恒为Hello发送间隔的四倍
除第5条MTU检测不影响邻居关系建立,只影响邻接关系建立,其他条目都影响邻居关系建立
与此相关的配置命令:
display ospf error interface GigabitEthernet 0/0/0 # 查看接口G0/0/0收到错误的 Hello 报文统计
reset ospf process # 重启 OSPF 进程
reset ospf counters # 在不重启 OSPF 进程的情况下清空 OSPF统计
ospf mtu-enable # 开启 OSPF 建立邻居关系 MTU 的检测
LSA与LSDB
LSA链路状态通告:描述路由器的链路状态信息(路由条目、开销、优先级、邻居信息)等LSDB链路状态数据库:设备上用于保存LSA的数据库
OSPF协议中一共有9种LSA,在HCIP阶段只学习6种,分别是:
| LSA类型 | LSA作用 |
|---|---|
| Router-LSA(Type1) | 每个设备都会产生,描述了设备的链路状态和开销,在所属的区域内传播。 |
| Network-LSA(Type2) | 由DR(Designated Router)产生,描述本网段的链路状态,在所属的区域内传播。 |
| Network-summary-LSA(Type3) | 由ABR产生,描述区域内某个网段的路由,并通告给发布或接收此LSA的非Totally STUB或NSSA区域。 每经过一个ABR都会由此ABR重新生成 |
| ASBR-summary-LSA(Type4) | 由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区域。 |
| AS-external-LSA(Type5) | 由ASBR产生,描述到AS外部的路由,通告到所有的区域(除了STUB区域和NSSA区域)。 |
| NSSA LSA(Type7) | 由ASBR产生,描述到AS外部的路由,仅在NSSA区域内传播。 |
注意:
LSA不只是传递路由,同时也传递拓扑如果将路由比作公交站牌子上的站名,那么拓扑就是地图
只看站名,没有地图,找不到去目的地的路
所以拓扑和路由在路由转发的过程中缺一不可
- 广播网络:只有一类LSA发布【拓扑信息】、二类LSA发布【路由信息】
- 点对点网络:一类LSA发布【路由信息】+【拓扑信息】、没有二类LSA
在广播网络中,二类LSA由DR发送,一类LSA所有设备均可发送。
由于广播网络
DR设备和BDR/DRother属于同一网段,所以广播网络中一类LSA无需发送路由信息,DR发送的二类LSA足以让区域内所有设备都得到对应路由由于
P2P链路不选举DR/BDR,所以路由信息和拓扑信息均由一类LSA发送
三类LSA用于跨区域发布路由信息,不发布拓扑信息
五类LSA用于发布外部网络(其他路由协议)的路由信息,由ASBR通告
四类LSA用于告诉OSPF网络“外部”路由是由谁通告的,由ABR通告
通过SPF算法计算LSDB中的LSA,就可以生成OSPF路由表,然后由设备择优写入主路由表
LSA报文
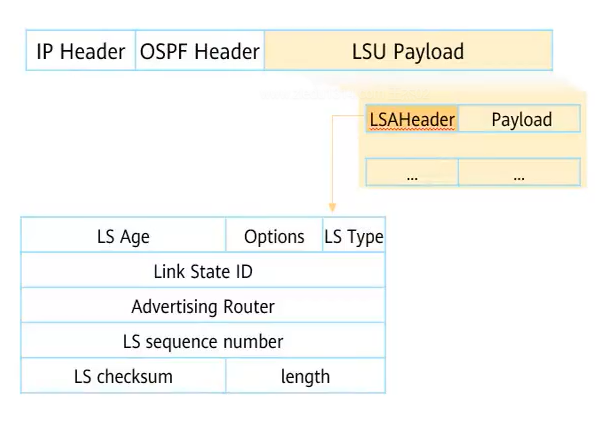
OSPF中所有的LSA报文头部都一致,如上图所示
LS Age:链路状态老化时间;默认为3600秒,老化时间到达一半时就会重新获取LSA
Options:可选项,每个bit都代表一个OSPF特性,通过置位开启
LS Type:LSA类型;表示本LSA具体是几类LSA
Link State ID:链路状态ID
- 二类及以上的LSA:链路状态ID就是具体的网段或者环回口地址(四类除外)
- 一类LSA:生成LSA的设备
Router-id - 四类LSA:通告五类LSA的ASBR设备Router-id,以便让其他设备找到ASBR
Advertising Router:通告路由器;值是通告路由器的Router id
LS sequence number:链路状态序列号;当新的LSA产生,链路状态序列号就会增加
- 如果老化时间已经过了15分钟,收到序列号大的LSA时就会替换旧的LSA
LS Checksum:校验和
Length:LSA的总长度
链路状态ID
Link State ID、链路状态类型LS Type、通告路由器Advertising Router三元组唯一标识一条LSA
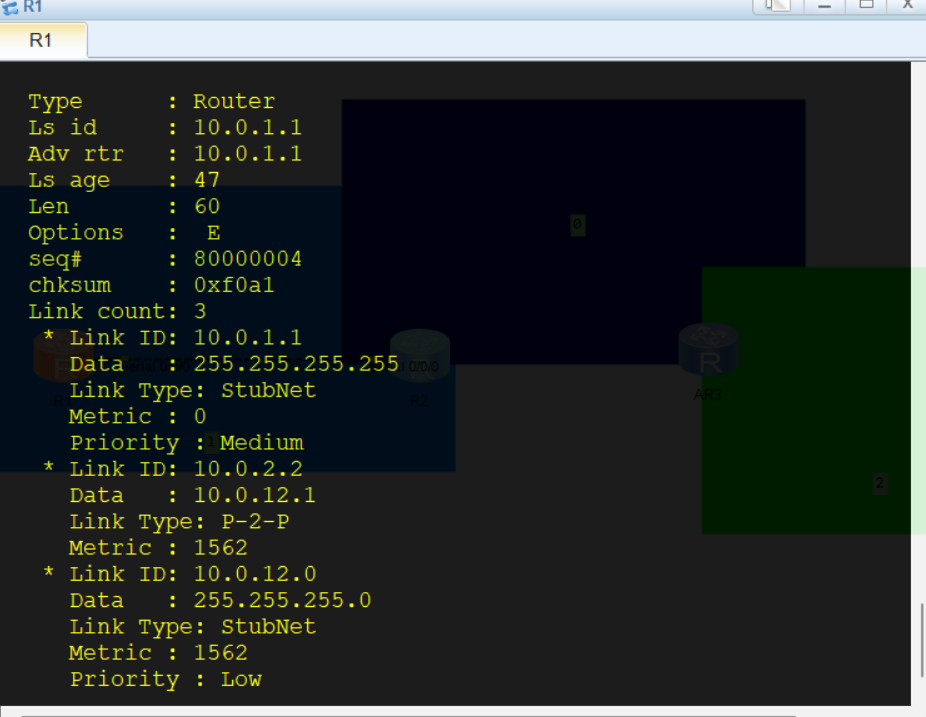
一类LSA详解
IP阶段所学的OSPF协议中,一类LSA最为特殊【只有一类LSA传递拓扑信息】
一类LSA需要分【宣告环回口】【宣告直连网段】【P2P链路】三种情况讨论,使用Link Tpye字段标识
一类LSA的
Link Tpye和LSA报文头部中标识几类LSA的LS Tpye不是一回事
广播链路一类LSA
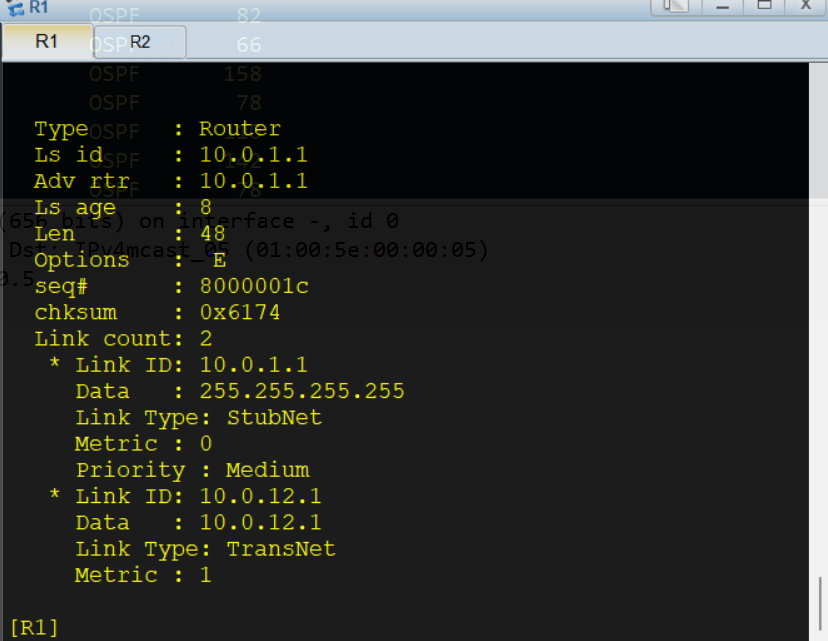
宣告环回接口:
Link Type为StubNetLink ID:环回口IP地址Data:环回口网络掩码
宣告广播网络直连网段:
Link Type为TransNetLink ID:DR的接口IP地址Data:宣告此LSA的出接口IP地址
TransNet类型的一类LSA用于给广播网络传递拓扑信息
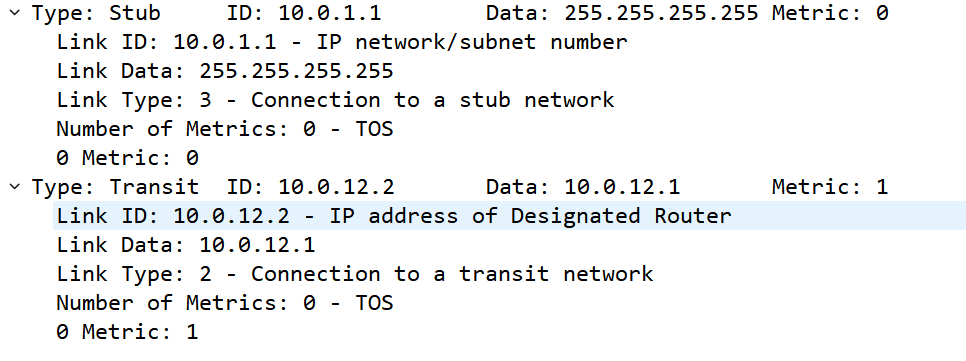
P2P链路一类LSA
P2P链路:
Link Type为StubNet和P2P两种StubNet:用于宣告直连接口(包括环回接口)路由信息Link ID:接口的网段地址Data:掩码
P2P:用于宣告网络拓扑信息Link ID:邻居Router-idData:去往邻居的出接口IP地址
对于广播网络,一类LSA通过
TransNet和StubNet发布拓扑信息,路由信息由二类LSA发布对于P2P网络,一类LSA通过
P2P发布拓扑信息、StubNet发布路由信息
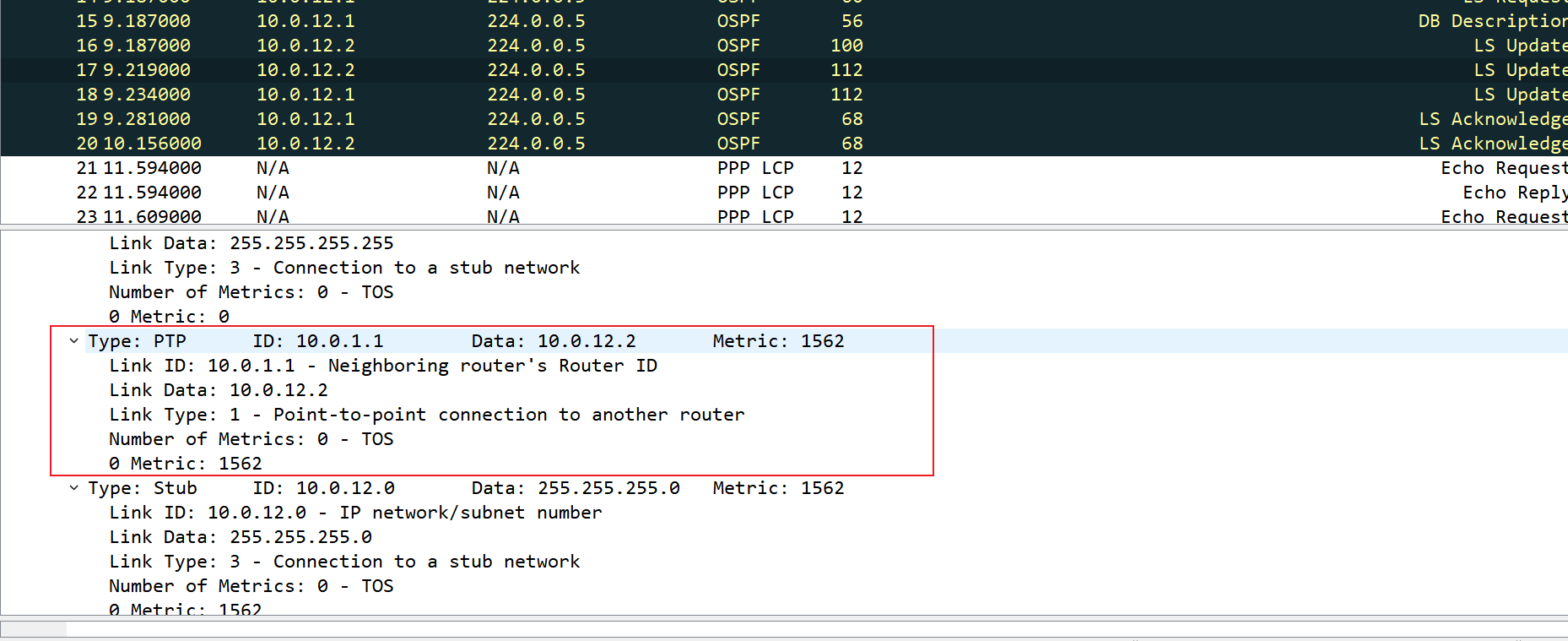
二类LSA详解
二类LSA描述该广播网络中有哪些路由器

二类LSA报文格式如上,报文头部除LS Tpye、Link State ID、Network Mask、Attached Router取值不同外,和一类LSA没有区别
- 二类LSA的
LS Tpye是Network
二类LSA报文payload是广播域中的所有OSPF路由器的Router-id
二类LSA由DR发布,所以P2P链路上没有2类LSA
二类LSA用于传递广播网络的区域内路由信息
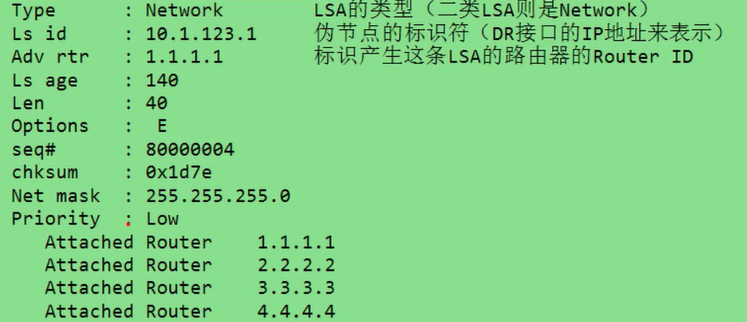
三类LSA详解
三类LSA报文及重要字段解释:

三类LSA由ABR发布,用于传递区域间路由信息
每经过一个ABR,都会由该ABR重新发布,以确保路由可达,这条原则也导致了五类LSA发布的路由无法直接通过三类LSA找到,而需要四类LSA的帮助
五类LSA详解

五类LSA由ASBR生成,用于发布引入的外部路由的路由信息
四类LSA详解
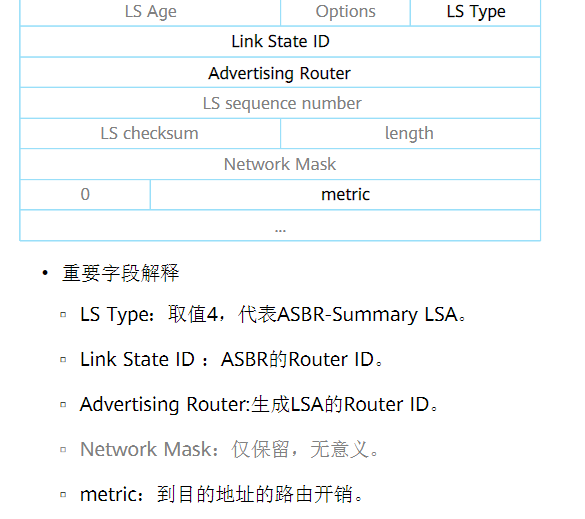
四类LSA也由ABR发布,但经过其他ABR时不会重新发布(改变通告者信息),所以三类LSA和四类LSA配合可以找到发布五类LSA的区域
OSPF外部路由引入的COST类型
OSPF引入外部路由时,开销值的设置方式又两种
- Type1类型:COST = 外部开销 + OSPF内部开销
- Type2类型:COST = OSPF内部开销(外部开销引入时归0)
SPF计算
通过SPF算法,可以让同区域内任意设备,得到一颗以自己为起点。无环,可以到达区域内其他所有设备并且路径最优的树
SPF最短路径一般是由设备自动计算的,但如果在网络维护时没有拓扑,可能需要运维人员手算拓扑
手算拓扑只需要熟记各类LSA字段的含义,以一个设备为起点,依次推导即可
通过一二类LSA得到区域内拓扑和路由,通过三类定位其他区域,然后加上四类和五类,拓扑就可以被推算出来
工作量很大
【详细略】
OSPF多区域
由于同一区域内的所有设备都维护这一个相同的LSDB,当OSPF网络中存在大量设备时,过大的LSDB会给予设备很大的负担
为了减少LSDB的规模,OSPF网络支持区域划分
不同区域之间只传递三类及以上的LSA,而不传递一、二类LSA,这样避免了不同区域学到对方的拓扑信息,同时减少了LSDB规模
由于SPF只能计算并生成同一区域内的最短路径树,无法跨区域计算(没有拓扑信息)
所以三类及以上LSA在不同区域之间传递时有环路的可能
为了避免区域间环路,OSPF有下述规定
- 区域0为骨干区域,其他区域都是非骨干区域
- ABR将区域内一类二类LSA转三类LSA发出后,不会将此三类LSA注回区域内
- 如果三类LSA由非骨干区域通告,则此LSA不参与路由计算(不传给下一区域)
- LSA传递方向不可逆(比如区域0和2相连,区域2不能将从区域0收到的LSA传回区域0)
这就表示,非骨干区域必须和骨干区域之间相连,否则无法学习到其他区域的路由信息
同时,也断绝了多区域间环路发生的可能
由于骨干区域是多区域
OSPF网络的核心并且对设备性能有很大的要求所以一般在核心层设备运行骨干区域,接入和汇聚部署在非骨干区域并进行合理的区域划分
虚链路
非骨干区域必须和骨干区域直接相连
但在一些特殊情况下,出现了非骨干区域连接了非骨干区域或者骨干区域分离的情况
一般是网络合并的时候会导致此类情况
此时重新部署网络不切实际,为了解决此类问题,提出了虚链路技术
虚链路技术的本质就是在物理链路上建立一条逻辑链路,让两个物理不直连的区域逻辑直连
虚链路本身破环了OSPF的区域间防环机制,可以作为应急手段,但非必要不要使用虚链路组网
配置:
ospf 1
area 0
vlink-peer [对端router-id] # 使能虚链路
OSPF特殊区域
OSPF网络分为骨干区域和非骨干区域,由于在绝大多数情况下,非骨干区域不承担区域间路由传递的工作,所以非骨干区域没有必要学习过多的区域间LSA
为了减少LSA在非骨干区域的条目,减轻设备压力,可以将区域外的LSA合并成一条缺省LSA。进行了该类操作的区域就是特殊区域
对于OSPF缺省路由,3类缺省LSA优先级高于五类和七类的路由
OSPF特殊区域共有四种,这四种依次演变而来:
Stub:末节区域最早的特殊区域,
Stub区域ABR将收到四类和五类LSA合并为一条缺省三类LSAospf 1 # 进入OSPF a 0 # 区域 stub # 使能StubTotally Stub:完全末节区域Stub升级版,大多数情况下所有的三类LSA同样共用一个ABR,Totally Stub在Stub的基础上,将所有的三类LSA同四类五类一起合并成了一条缺省LSAospf 1 # 进入OSPF a 0 # 区域 stub no-summary # 使能Totally StubStub区域的特点是:
不能是骨干区域、不能存在虚链路、不能存在ASBR设备
NSSA:no so stub area不那么末节的区域英译很怪,但代表了切实的意思
由于Stub区域将四类和五类合并为了缺省三类LSA,这就意味
Stub区域无法引入外部路由NSSA区域在Stub区域的基础上增加了7类LSA,外部路由可以通过七类LSA引入到NSSA,再由ABR转为五类LSA发布给骨干区域,以达成路由引入NSSA区域其他规则同Stub同stub,将stub换nssa即可Totally NSSA:不那么完全的完全末节区域对
NSSA区域而言,三类LSA同样没啥用,Totally NSSA同Totally Stub一样,将三、四、五类LSA合并为一条缺省三类LSA同Totally Stub,将stub换nssa即可NSSA区域的特点是:
不能称为骨干区域、不能存在虚链路、必须存在ASBR
所以,配置NSSA区域后,会自动生成一条指向骨干区域的缺省7类
完全NSSA生成的缺省3类LSA和NSSA的缺省7类互不影响,因为LSA优先级、默认优选缺省san’lei
划分特殊区域的本质目的就是为了减少设备压力和LSDB条目,在网络故障时可以一定程度上减少网络故障的影响
- 骨干区域不可以划分为特殊区域
- 特殊区域内所有设备都要划为此区域,比如Stub区域所有设备都需要进行Stub区域配置
- 完全特殊区域在特殊区域的基础上,只需要在ABR上配置
no summary - 虚链路不能穿越特殊区域
OSPF协议特性
OSPF路由汇总
OSPF可以进行路由汇总
和手工汇总不同,OSPF的路由汇总只汇总OSPF路由,不会汇总其他协议的路由
OSPF路由汇总有两种类型
在ABR上做路由汇总:对区域间路由汇总,处理三类LSA
abr-summary 172.17.1.0 255.255.248.0在ASBR上做路由汇总:对引入的外部路由汇总,处理五类LSA
asbr-summart 172.17.1.0 255.255.248.0
除ABR和ASBR外,其他位置的路由汇总没有意义,也没法做
OSPF路由聚合后不会像BGP一样再发布明细路由
OSPF边缘接口(Slient-Interface)
与业务广播域直连的接口不需要建立OSPF邻居,但仍然会发送Hello报文
此时Hello报文在业务网段中广播,浪费了带宽资源
可以通过设置边缘接口的方式禁止接口发送Hello报文
注:如果接口连接了其他OSPF设备,不要设为边缘端口,否则OSPF邻居将协商失败
配置:
ospf 1
silent-interface g0/0/1 # 设置g0/0/1为边缘端口
OSPF认证
为了保证安全性,OSPF协议支持认证功能,有两种方式
区域认证方式:区域中配置,同一区域认证模式和口令必须一致
area 0 authentication-mode simple cipher XXX接口认证方式:接口上配置,链路两端接口的认证模式和口令必须一致
int g0/0/1 ospf authentication-mode md5 1 cipher XXX
当两种验证方式都存在时,优先使用接口验证方式。
集成IS-IS
IS-IS:中间系统到中间系统,是ISO为OSI七层网络构建的运行在链路层的三层网络协议,是一种链路状态协议
OSI模型称路由器等负责转发的设备为中间系统(IS),数据的生成者、最终接收者称为终端系统(ES)
IS-IS就是用在中间系统的协议,中间系统到终端系统运行另一个协议:ES-IS【拓展知识】
IS-IS相比OSPF,收敛速度极快,其路由机制也极为简单。但由于TCP/IP模型以及OSPF协议更早的被广泛使用,所以IS-IS虽然优点明显,但没有人用来组网
TCP/IP为了解决OSPF的各类问题,重写了OSI模型中的ISIS协议,使之支持TCP/IP模型
支持TCP/IP的版本称为集成IS-IS,现在所谓的IS-IS也多指集成IS-IS
OSI模型和TCP模型完全就是两码事
- TCP/IP使用IP地址寻址、每个接口都需要一个IP地址;网络协议为IP协议
- OSI使用NSAP地址寻址、每个设备只需要一个NSAP地址;网络协议为CLNP
所以OSI和TCP/IP完全就是两种不同的网络,两者之间不能互通
华为、思科、华三等厂商均只生产TCP/IP模型的设备,以前ISO组织有生产OSI设备,但现在也已经停产
集成IS-IS常用于组建广域网
集成IS-IS同IS-IS,虽然是三层的网络协议,但是封装在数据帧头部之后(二层)
NSAP地址
NSAP地址是OSI模型的寻址基础,地位同等与TCP/IP模型的IP地址,集成IS-IS也基于NSAP地址建立邻居关系
NSAP地址结构
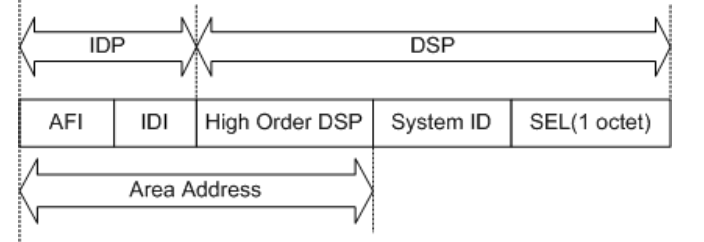
对OSI模型而言,NSAP地址分为IDP和DSP,这不是学TCP的关注的点
对TCP而言,NSAP地址分为Area、System ID、SEL
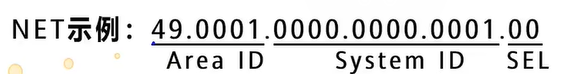
Area:同OSPF的Area,都表示区域IS-IS是否骨干区域和area无关(和路由等级有关),Area只是区分区域- 对集成IS-IS而言,有且只有
49.xxxx和47.xxxx两个区域,约定俗成的:49用在私网,47用在公网 - 注意,ISIS的
Area ID长度是可变的,最小1字节,最多13字节
System ID:同OSPF的Router-id,唯一标识一个设备,并以此建立邻接关系- IS-IS没有邻居关系,是从Down开始,直到到建立邻接关系
SEL:对TCP模型没啥意义,写00就行
由于
Area ID长度最小一字节,最多13字节,System ID固定6字节,SEL固定0字节且在集成ISIS中只能是00所以NSAP地址最短8字节,最长20字节
当NSAP地址标识路由器时(SEL为00时),将该NSAP称为NET。所以集成ISIS中的NSAP地址均可称为NET地址
NSAP地址(NET地址)配置方式:
isis 1 # 进入集成IS-IS进程1
network-entity 49.0001.0000.0000.0001.00 # 配置NSAP地址
IS-IS区域与路由器分类
IS-IS区域
不同于OSPF一个接口一个IP地址,区域以接口为单位
IS-IS一个设备一个NSAP地址,区域以设备为单位,一个设备属于一个区域
IS-IS单个区域没有骨干和非骨干的概念,定义骨干区域和非骨干区域的是路由器等级
华为ISIS一个设备最多创建三个区域,目的是方便平滑的进行区域合并、分割、转换用
IS-IS路由器分类
根据路由器等级,ISIS路由器分类三类
- Level-1路由器:只运行Level-1等级的路由器
- Level-2路由器:只运行Level-2等级的路由器
- Level-1-2路由器:同时运行了Level-1和Level-2等级的路由器,相当于OSPF的ABR
运行L2等级的路由器,属于骨干区域(L2 / L1-2);运行L1等级的路由器,属于非骨干区域(L1)
同OSPF一样,骨干区域有整个网络的LSP(链路状态通告,ISIS叫LSP,OSPF叫LSA),非骨干区域只有本区域内的LSP
ISIS非骨干区域就等同OSPF的Totally NSSA区域,自带OSPF特殊区域的功能
L2路由域必须物理连续
当L1路由器连接其他区域(L1-2设备)时,连接其他区域的边界设备(L1-2设备)会向L1区域内发送ATT置位的报文,表示可以由自己去往其他区域
ISIS组网拓扑:
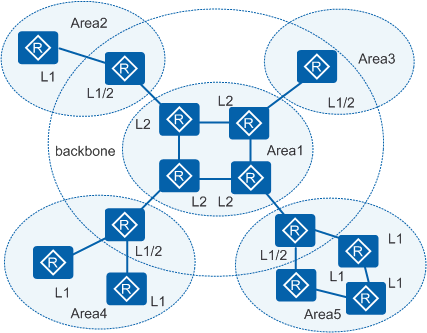
L1和L2的本质是维护的LSDB不一样,L1维护L1-lsdb,L2维护L2-lsdb,L1-2同时维护L1-lsdb和L2-lsdb
所以非骨干区域L1想通告LSP到骨干区域L2,就必须经过L1-2路由器,由L1-2路由器通告
- 可以这样说:L1-2路由器连接骨干区域和非骨干区域
IS-IS报文
首先是ISIS的报文结构


IS-IS可以说有4种报文,也可以说有9种报文
IIH报文:
IS-IS Hello,isis的Hello报文,又称Hello PDU,作用和OSPF的Hello一样,但不选举DR/BDR,而是选举DIS缺省发送时间同OSPF的HELLO,为10s,其中DIS快三倍,也就是3.3s发送一次
DIS等同于OSPF的DR,但DR是具体的物理接口,DIS是逻辑的虚拟设备
- L1网络使用 L1 LAN IIH
- L2网络使用 L2 LAN IIH
- P2P网络使用 P2P IIH
所以IIH可以说是一种报文,也可以说是三种报文
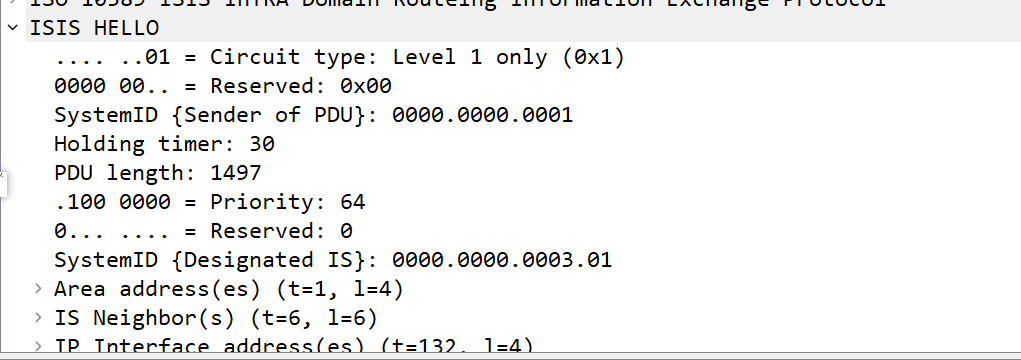
LSP:链路状态报文(Link State PDUs),同OSPF的LSA,用于交换路由信息和拓扑信息
其中L1 LSP中有几个重要字段
ATT字段:当Level-1-2 IS-IS在Level-1区域内传送Level-1 LSP时,如果Level-1 LSP中设置了ATT位,则表示该区域中的Level-1 IS-IS可以通过此Level-1-2 IS-IS通往外部区域。
OL:过载位标识
设置了过载标志位的LSP虽然还会在网络中扩散,但是在计算通过过载路由器的路由时不会被采用。
即设置过载位后,其它路由器在进行SPF计算时不会使用这台路由器做转发,只计算该节点上的直连路由。
L2 LSP和L1 LSP的区别是L2有L1区域内的路由信息,ATT永远为0,其他的都一样
同理,LSP可以说是一种报文,也可以说是L1 LSP和L2 LSP两种报文
SNP:序列号报文,相当于OSPF的DD或LSR,在ISIS中有两种SNP
CSNP:全序列号报文
- CSNP包括LSDB中所有LSP的摘要信息,从而可以在相邻路由器间保持LSDB的同步。
- 相当于OSPF的DD报文,由DIS定期发送(缺省的发送周期为10秒)
- 在点到点链路上,CSNP只在第一次建立邻接关系时发送。
- 可分为L1 CSNP和L2 CSNP报文
PSNP:部分序列号报文
- PSNP只列举最近收到的一个或多个LSP的序号,用于请求自己缺少的LSP
- 相当于OSPF的LSR报文
- 可分为L1 PSNP和L2 PSNP报文
所以SNP报文可以说两种也可以说四种
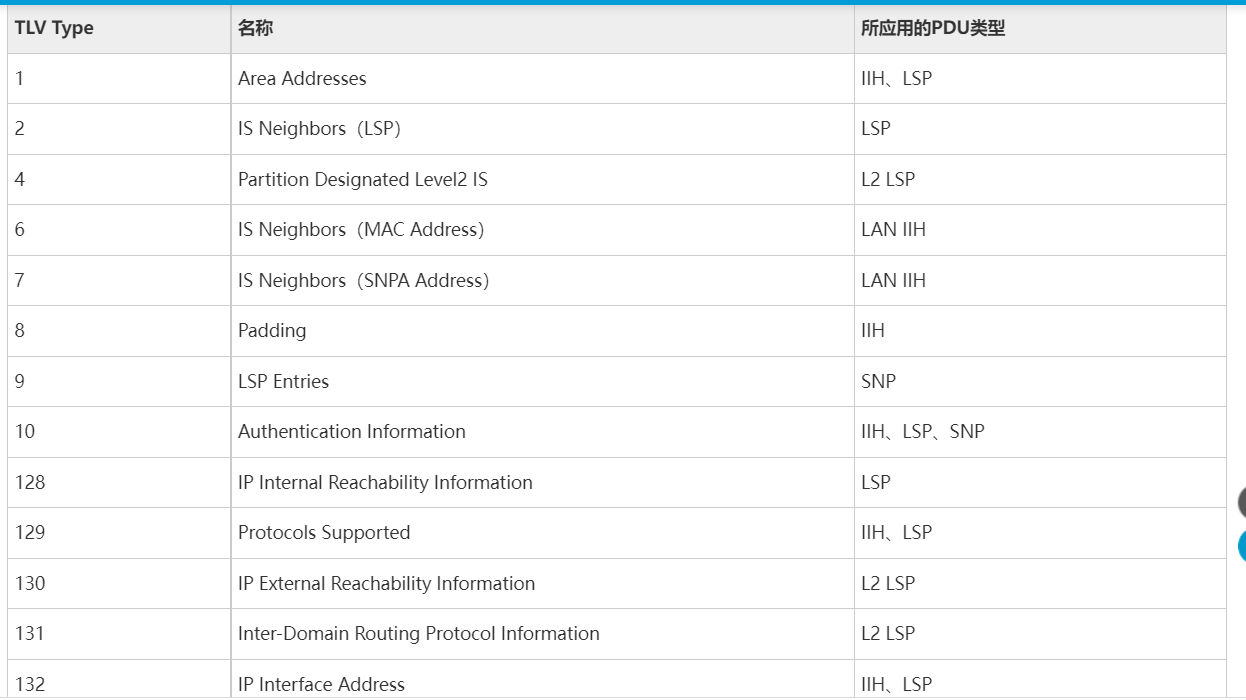
为了让IS-IS可以自动跟上时代,IS-IS报文中有个可变长的TLV字段

TLV字段相当于一个热插拔接口,需要处理IPV4插IPV4,需要IPV6插IPV6,从而使IS-IS可以快速迭代
而不是像OSPF一样,IPV4只能用OSPFv2、IPV6只能用OSPFv3
TLV对应表如下:
邻接关系的建立
Level-1路由器负责区域内的路由,它只与属于同一区域的Level-1和Level-1-2路由器形成邻接关系,属于不同区域的Level-1路由器不能形成邻接关系。
Level-1路由器只负责维护Level-1的链路状态数据库LSDB(Link State Database),该LSDB包含本区域的路由信息,到本区域外的报文转发给最近的Level-1-2路由器。
Level-2路由器负责区域间的路由,它可以与同一或者不同区域的Level-2路由器或者其它区域的Level-1-2路由器形成邻接关系。
Level-2路由器维护一个Level-2的LSDB,该LSDB包含区域间的路由信息
集成IS-IS只支持广播网络和点到点网络,不支持NBMA网络和点到多点网络
IS-IS只有三种状态
Down:接口没启动/还没有收到IIH报文Init:收到了一个邻居为Null的IIH报文UP:收到了一个邻居为自己的IIH报文
UP就是ISIS的邻居状态,ISIS状态不是依次改变的,而是只要满足了条件,可以直接从Down到UP
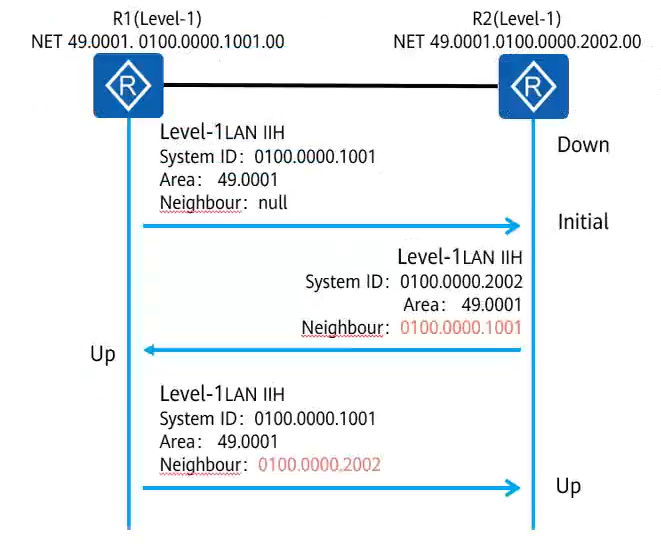
广播网络还需要选举DIS,邻接关系建立后路由器会等待两个IIH报文时间间隔(20s),再进行DIS选举
IS-IS开销值
IS-IS的初始开销值和带宽无关,默认P2P链路和广播链路都是10
L1区域只能学到L1的开销值
有三种设置方式:
设置接口开销值:只改变某一接口的开销值
[AR1-Serial1/0/0]isis cost 63 # 设置isis接口开销为63设置全局开销值:修改IS-IS的默认开销(cost=10)
[AR1-isis-1]circuit-cost 20 # 设置isis全局开销为20根据带宽计算
IS-IS开销值有两种类型
- wide:大开销,开销最大为16777215
- narrow:缺省、开销最大为63
修改开销类型命令:
[AR1-isis-1]cost-style [wide|narrow] # 全局修改
不同的开销值类型之间不能建立ISIS邻接关系
DIS详解
一个广播域内的所有设备都需要交换LSP,如果有三个设备,那么一台设备可能要将同一条LSP发三次,这无疑浪费了链路资源
为了解决这个问题,IS-IS在每个广播域都逻辑了一台虚拟设备DIS,广播域中的设备将全部的LSP交给DIS,由DIS分发给其他设备
注:不同于DR/BDR,ISIS协议中,广播域内所有设备都两两形成邻接关系,DIS和其他所有设备也形成邻接关系,DIS只是负责统合交换LSP
DIS发送Hello报文的时间是普通设备的1/3,以确保DIS故障时能够更快被发现
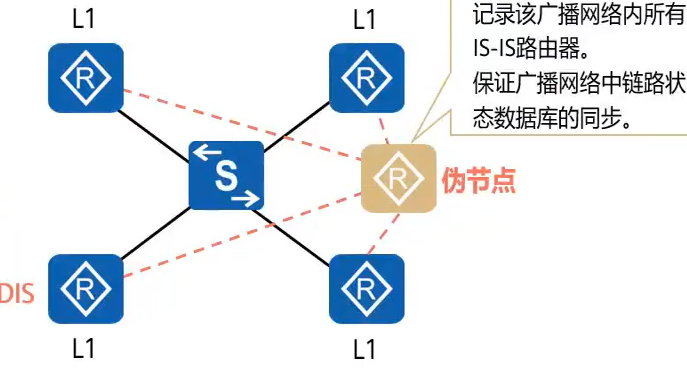
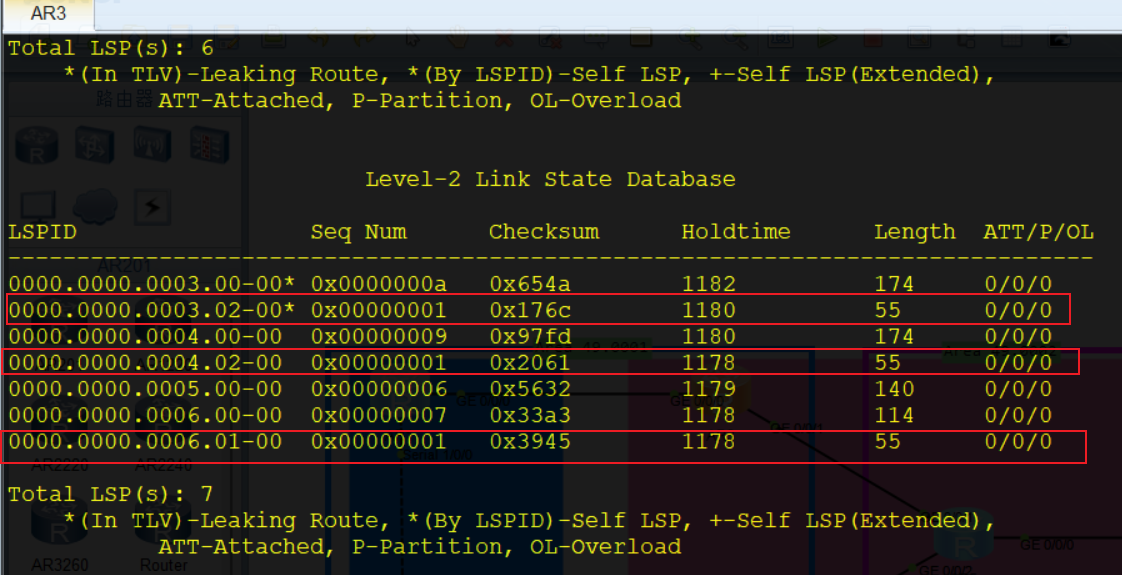
真实设备到DIS的开销默认都是10,DIS到真实设备的开销是0
DIS在ISIS网络中使用设备的
System ID和Circuit ID(非0值)共同标识
以
0000.0000.0003.02-00为例,前三段0000.0000.0003是System ID,后一段02-00是说Circuit ID为02,SEL为00
Circuit ID的值随真实设备创建的伪节点数增加,创建的第一个伪节点就是01,第二个就是02
DIS选举原则:
同一广播域内:
- 优先级越大越优先(不同于OSPF优先级为0自动成Dother,ISIS中优先级为0仍然参与DIS选举)
- 如果优先级一样,则MAC地址越大越优先(看连接广播域的接口MAC)
- DIS支持抢占
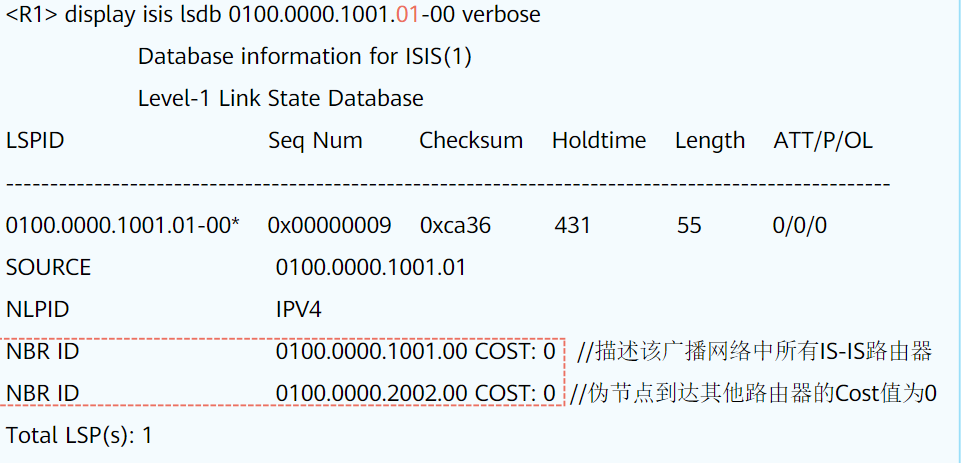
伪节点LSP中只包含邻接信息(拓扑信息)不包含路由信息
路由渗透
由于L1区域不能得知L2区域的路由和具体的开销值信息
所以当有如下组网时,可能会产生次优路径问题
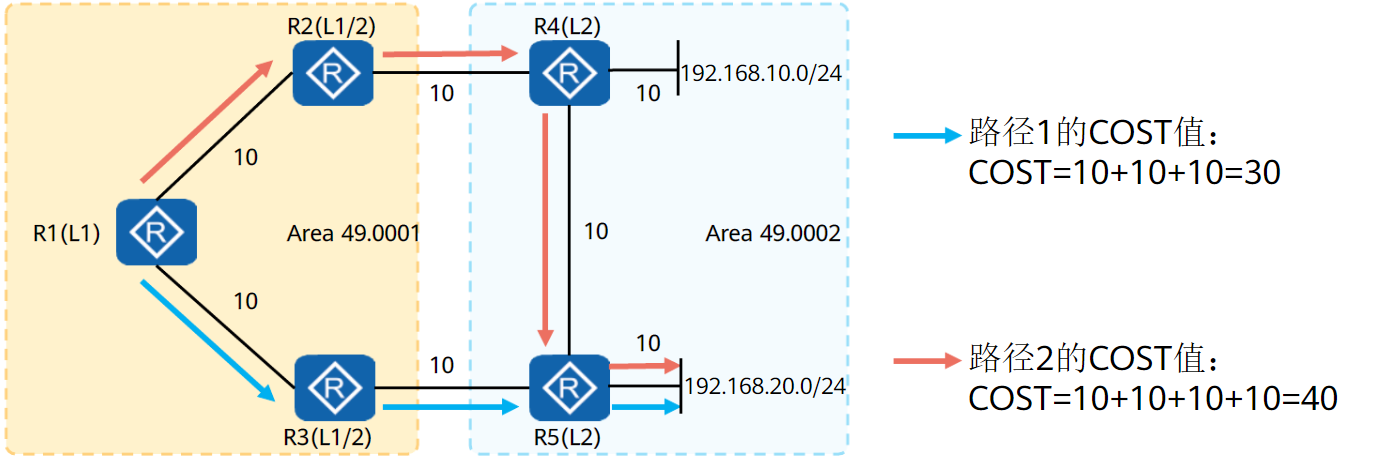
路由渗透的目的,就是将L2区域的部分路由信息渗透到L1区域,从而让L1区域可以计算其他区域的详细路由,以此计算最优路径
配置
ip ip-prefix 1 index 10 permit 10.0.5.5 32 # 创建ip-prefix抓取路由
isis 1 # 进入isis协议视图
import-route isis level-2 into level-1 filter-policy ip-prefix 1
# 引入isis L2的路由到L1区域,具体的路由由ip-prefix 1抓取
acl、ip-prefix、route-policy都可以抓取路由
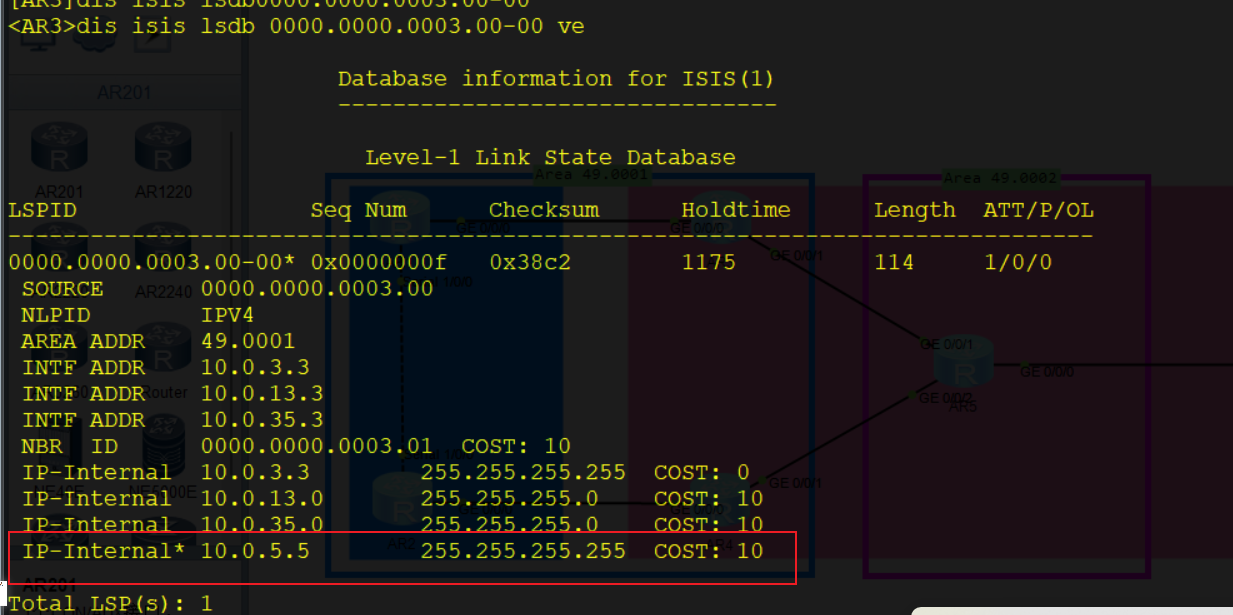
L2区域5.5的路由信息被引入进AR3的L1 LSDB中
集成ISIS配置
拓扑还是路由渗透的图
isis 1 # 进入isis协议视图
is-level level-1 # 配置路由器级别(缺省为level-1-2)
network-entity 49.0001.0000.0000.0003.00 # 配置NSAP地址
interface LoopBack0
ip address 10.0.3.3 255.255.255.255 # 配置接口IP地址
isis enable 1 # 使能isis进程1
其他配置命令:
display isis lsdb # 查看isis的lsdb数据库
[AR1-GigabitEthernet0/0/0]isis dis-priority 120 # 配置接口dis优先级
[AR1-GigabitEthernet0/0/0]isis circuit-type p2p # 设置链路的网络类型,缺省为链路本身类型
[AR1-GigabitEthernet0/0/0]undo isis circuit-type # 恢复缺省网络类型
虽然集成ISIS以NSAP地址建立邻居关系,但毕竟还是TCP模型,所以需要配置接口IP地址
ISIS认证
为了保证安全性,ISIS协议同样支持认证功能
ISIS认证的实现本质是报文携带认证TLV
根据报文的种类,可分为三类认证
接口认证:在接口视图下配置,对L1和L2的IIH报文进行认证
Hello使用的密码保存在接口下
区域认证:在IS-IS协议视图下配置,对L1的SNP、LSP报文进行认证
区域内每台
L1路由器都必须使用相同的认证模式和密码路由域认证:在IS-IS协议视图下配置,对L2的SNP、LSP报文进行认证
区域内每台
L2/L1-2路由器都必须使用相同的认证模式和密码
对于区域和路由域的认证,可以设置SNP和LSP分开认证
根据认证方式,可分为四类:
- 简单认证:将密码直接加入报文中,安全性低
- MD5认证:将配置的密码进行MD5加密之后再加入报文中,提高密码安全性
- KeyChian认证:通过配置随时间变化的密码链表来进一步提高安全性
- HMAC-SH256认证:将配置的密码进行HMAC-SH256算法加密之后再加入报文中,提高密码安全性
配置命令:
# 接口认证
interface GigabitEthernet0/0/0 # 进入接口
isis authentication-mode md5 cipher 123 [level-1] [ip] [send-only]
# 配置IsIs认证模式MD5,密码123,作用于L1等级,属于TCP/IP模型
- send-only:可选,仅仅对发送的IHH检查。不检查接收的IIH
- IP:可选,表示这是IP模型的认证
- level-1:可选,表示认证L1路由器
# 区域认证
isis 1 # 进入isis视图
area-authentication-mode md5 cipher 123 # 配置认证
选项:
- all-send-only 验证发送的PDU,不检查接收的PDU
- ip IP认证
- osi OSI认证
- snp-packet SNP报文认证设置
- authentication-avoid 只认证LSP报文,不认证SNP报文
- send-only 仅发送验证发送的SNP,不检查接收的SNP
# 路由域认证
isis 1
domain-authentication-mode md5 cipher 123
路由域认证的选项和含义和区域认证一致,无法是区域认证针对L1,路由域针对L2
路由策略与路由控制
所谓路由策略,就是对路由的策略。
从技术角度而言,就是使用一系列工具对路由进行抓取并进行处理(过滤、放行、打标签等)
路由控制由路由策略(Route-Policy)或者过滤策略(Filter-Policy)实现,有三种方式:
- 控制路由的发布:在路由发布前对路由进行过滤
- 控制路由的接收:在路由接收前对路由进行过滤
- 控制路由的引入:在路由引入前对路由进行过滤
路由控制中入方向为
import,出方向为export流量控制中入方向为
inbound,出方向为outbound路由控制一般在协议视图配置,流量控制一般在接口配置
路由匹配工具
路由匹配工具只抓取路由,抓取后的操作由策略工具实现
IP阶段有ACL和ip-prefix两种
ACL
ACL:访问控制列表
在IA阶段已经学习过,即可以抓路由,也可以抓流量
抓取流程:
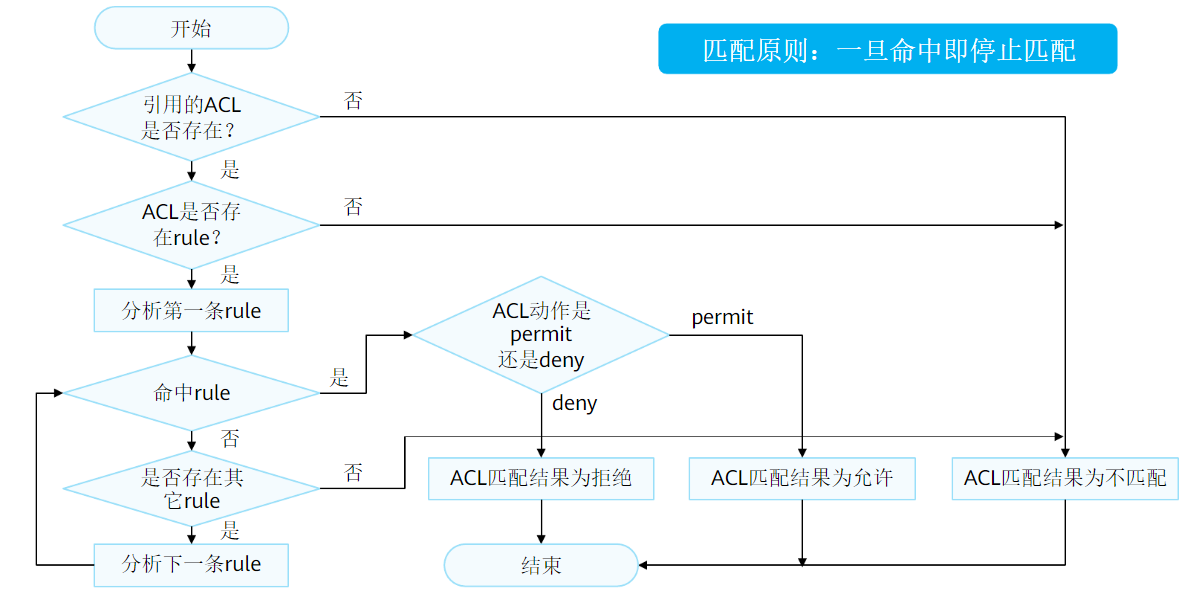
可以理解为:匹配到且动作为permit就是抓取,匹配到且动作为deny就是不抓取,没有匹配到就是不匹配
deny不抓取和不匹配在路由匹配层面来看毫无意思,都是没抓到路由,但对于后续的路由控制工具而言是不同的
一个是匹配到了但没有抓,一个是没匹配到,两者在路由控制工具的处理中有可能产生完全不同的结果
ACL配置解释:
acl 2000 # 创建一条基本acl
rule 5 deny source 192.168.1.1 0.0.0.0
rule 10 permit source 192.168.1.0 0.0.0.255
在上述配置种,deny/permit不应被理解为拒绝和允许,而是不抓取/抓取
所以acl 2000在这里的作用是,抓取前缀为192.168.1.0的所有路由,但是不抓取192.168.1.1这条路由
也就是抓取192.168.1.0、192.168.1.2-255这个范围内的路由
在ACL种,0.0.0.255不是反掩码,而是通配符,0代表严格匹配,1代表任意
所以
192.168.1.0 0.0.0.255这条规则,匹配的是所有以192.168.1开头的路由包括
192.168.1.0/25、192.168.1.0/8等,不是匹配192.168.1.0/24这一个网段
ACL有两种匹配模式:
- 配置顺序-config模式:按编号从小到大匹配,缺省为config模式
- 自动排序-auto模式:系统使用“深度优先”的原则,将规则按照精确度从高到低进行排序,并按照精确度从高到低的顺序进行报文匹配。限制越严格,精确度越高
auto模式对管理员不可控,所以一般均使用config模式
ip-prefix
ACL即可以抓路由,也可以抓流量,抓的到底是路由还是流量,取决于后续是什么工具调用的ACL
而ip-prefix只能抓路由、不能抓流量,所以流量控制不能使用ip-prefix
ip-perfix从结果来看更像是ACL的路由匹配升级版
配置命令:
ip ip-prefix text index 10 permit 192.168.1.0 24 greater-equal 24 less-equal 32
ip-prefix名称 节点编号 动作 网段地址 前缀长度 掩码范围
匹配前缀为192.168.1的路由,掩码在24到32之间
相比于ACL的192.168.1.0 0.0.0.255可以匹配前缀一样的所有网段,ip-prefix在后面规定了掩码的范围,对ACL不能匹配具体网段的缺点做了限制
所以可以将ip-prefix看在专为路由服务的升级版ACL
ip-prefix按序号从小到大进行匹配,名称唯一标识一个ip-prefix
匹配机制:
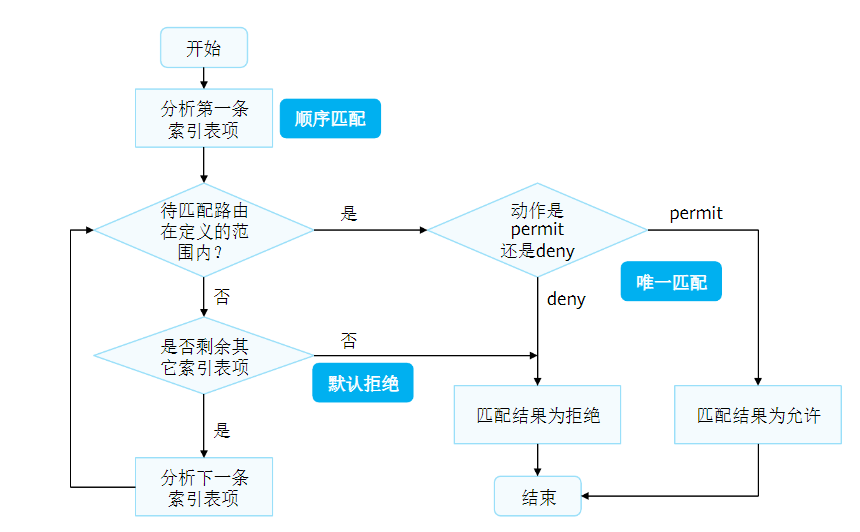
如果所有节点都没有匹配,ip-prefix默认匹配deny
Filter-Policy
Filter-Policy:过滤策略,是路由控制工具的一种,能够对接收、发布、引入的路由进行过滤
对于除链路状态协议外的其他协议,出方向和入方向都是路由传递路径
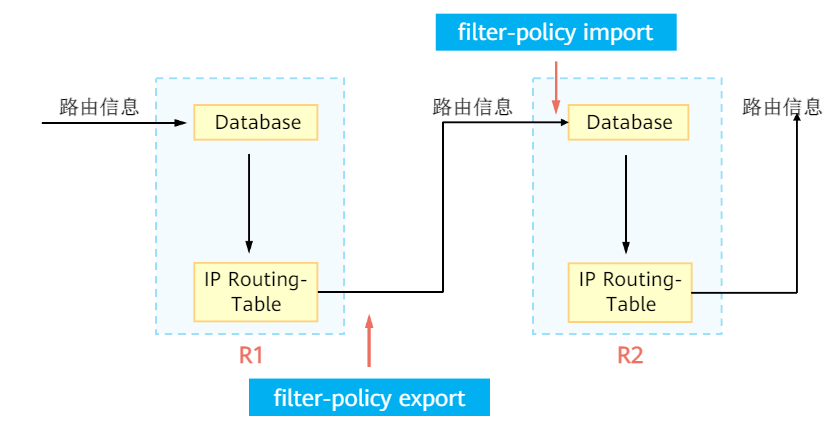
对于链路协议协议而言,由于链路状态通告路由是通过LSA/LSP,而抓取工具抓不到LSA/LSP,所以
- 入方向指LSA/LSP生成路由的过程,
import - 出方向只针对从其他协议引入路由(设备生成LSA)的过程
export
因为抓不到LSA,所以路由控制工具只能阻断LSA/LSP生成路由的过程
配置命令:
filter-policy在协议视图配置、
filter-policy {acl编号|ip-prefix名称|route-policy名称} {import|export}
例如:
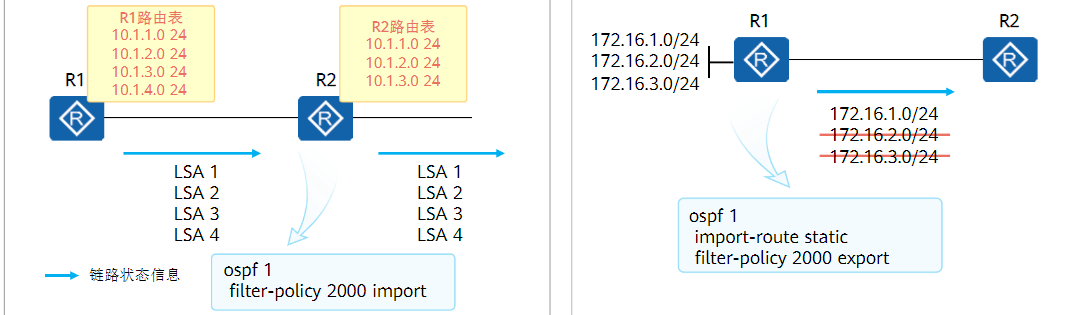
acl number 2000
rule 5 deny source 10.1.5.5 0 # 不抓取10.1.5.5
rule 10 permit # 抓取其他所有路由
ospf 1
filter-policy 2000 import # 在OSPF 1中设置Filter-Policy
对于Filter-Policy而言,是否过滤路由取决于抓取工具的动作
比如上面的配置,
acl 2000中动作是deny的,Filter-Policy动作就是过滤
acl 2000中动作是permit的,Filter-Policy动作就是放行由于
Filter-Policy默认动作为过滤,所以deny需要过滤的路由后,还需要手动permit其他的所有路由
Route-Policy
Route-Policy:路由策略,同样是路由控制工具的一种
不同于Filter-Policy只能做过滤,Route-Policy不但可以做过滤,还可以修改路由的属性
链路状态路由协议内部过滤路由只能用
Filter-Policy,因为传的是LSA/LSP所以并不是
Filter-Policy不如Route-Policy

Route-Policy节点间是或关系,只要匹配一个就不继续匹配,节点内的条件语句是与关系,只有满足节点内所有条件才算是匹配了这个节点
配置命令:
route-policy cy permit node 10
if-match acl 2000
apply preference 14
route-policy cy permit node 20
Route-policy没有匹配到节点,默认拒绝
Route-policy 过滤器
路由策略中If-match子句中匹配的6种过滤器,分别是访问控制列表ACL、地址前缀列表、AS路径过滤器、团体属性过滤器、扩展团体属性过滤器和RD属性过滤器。
- ACL:访问控制列表
- 将报文中的入接口、源或目的地址、协议类型、源或目的端口号作为匹配条件的过滤器,在各路由协议发布、接收路由时单独使用。
- 在Route-Policy的If-match子句中只支持基本ACL。
- IP-Prefix:地址前缀列表
- 地址前缀列表将源地址、目的地址和下一跳的地址前缀作为匹配条件的过滤器,可在各路由协议发布和接收路由时单独使用。
- AS_Path Filter:AS路径过滤器
- AS路径过滤器是将BGP中的AS_Path属性作为匹配条件的过滤器,在BGP发布、接收路由时单独使用。
- AS_Path属性记录了BGP路由所经过的所有AS编号。
- Community Filter:团体属性过滤器
- 团体属性过滤器是将BGP中的团体属性作为匹配条件的过滤器,在BGP发布、接收路由时单独使用。
- BGP的团体属性是用来标识一组具有共同性质的路由。
- Extcommunity Filter:扩展团体属性过滤器
- 扩展团体属性过滤器是将BGP中的扩展团体属性作为匹配条件的过滤器,可在VPN配置中利用VPN Target区分路由时单独使用。
- 目前,扩展团体属性过滤器仅应用于对VPN中的VPN Target属性的匹配。
- RD Filter:RD属性过滤器
- RD团体属性过滤器是将VPN中的RD属性作为匹配条件的过滤器,可在VPN配置中利用RD属性区分路由时单独使用。
- VPN实例通过路由标识符RD实现地址空间独立,区分使用相同地址空间的前缀。
除此之外的过滤器,route-policy的if-match无法匹配,但仍然可以匹配诸如TAG的属性
当IP地址为0.0.0.0时表示通配地址,表示掩码长度范围内的所有路由都被Permit或Deny。
BGP to IGP功能使IGP能够识别BGP路由的Community、Extcommunity、AS-Path等私有属性。
在IGP引入BGP路由时,可以应用路由策略。只有当设备支持BGP to IGP功能时,路由策略中才可以使用BGP私有属性作为匹配条件。如果设备不支持BGP to IGP功能,那么IGP就不能够识别BGP路由的私有属性,将导致匹配条件失效。
路由回馈和次优路径问题
在两个协议之间做双点双向路由引入时,会产生路由回馈和次优路径问题
可以使用路由控制解决
路由回馈问题
又称路由环路问题
如果存在两个网络双点双向引入路由,如下图,ospf路由引入isis后又由isis发回ospf,导致路由环路
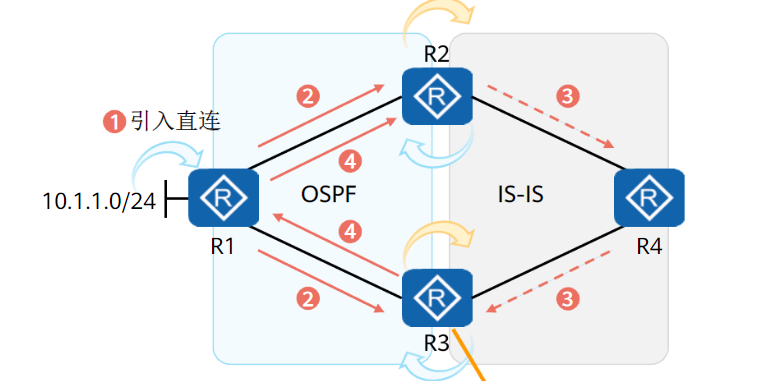
解决方案:
ASBR引入路由时进行判断
- 如果外部路由没有携带TAG,则打上一个TAG
- 如果外部路由携带TAG,则过滤
# 路由策略
route-policy hk deny node 10
if-match tag 100 # 有tag则过滤
route-policy hk permit node 20
apply tag 100 # 没有tag则打上tag 100
# 路由协议引用
isis 1
cost-style wide
import-route ospf 1 route-policy hk
ospf 1
import-route isis 1 route-policy hk
注意:isis开销值默认为
narrow模式,在此模式下,无法给路由打tag,所以需要将isis网络开销值模式改为wide
次优路径问题
次优路径只有OSPF网络和其他协议网络双点双向重定向时存在
归根揭底是OSPF引入外部路由的优先级问题
以OSPF和ISIS为例,OSPF引入外部路由优先级150,ISIS引入外部路由优先级15
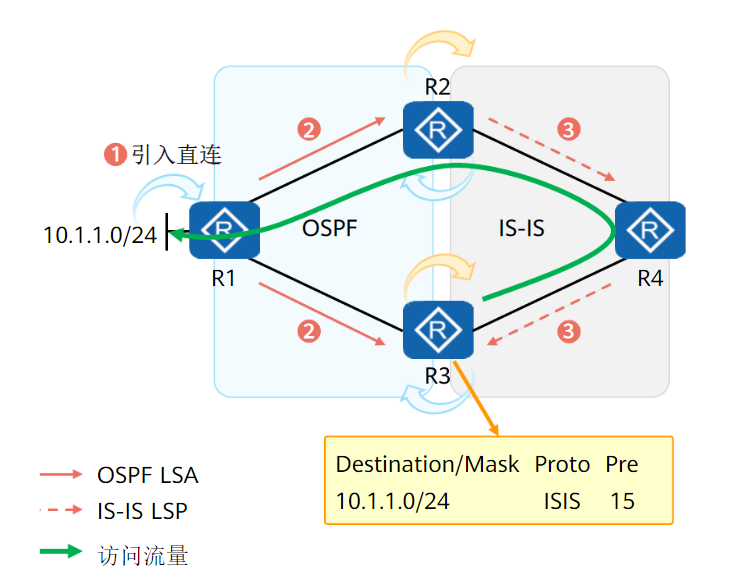
若有如上网络,R3访问10.1.1.0网段,此时对于R3而言,直接去R1优先级150,去R4优先级15,自然选择R4,就造成了次优路径问题
解决方案:降低OSPF引入外部路由的优先级
# 设置acl
acl number 2000
rule 5 permit source 10.0.5.5 0.3.0.0
# 设置route-policy,修改目的路由开销为14
route-policy cy permit node 10
if-match acl 2000
apply preference 14
route-policy cy permit node 20
# ospf中使用route-policy
ospf 1
preference ase route-policy cy 150
策略路由与流量控制
策略路由的目的就是为了控制流量,如果说路由策略对于路由的地位等同于红绿灯对于十字路口,那么策略路由于流量控制的地位就等同于十字路口堵车时的交警
前者总领性的指导路由的转发,后者针对一些特殊场景做特殊处理
就好像有交警看交警手势,没交警看红绿灯一样,流量控制的优先级高于路由表
在IP阶段,流量控制相关的技术需要学习三种:策略路由PBR、MQC、流量过滤
策略路由PBR
策略路由PBR(Policy-Based Routing)是一种依据用户制定的策略进行路由选择的机制,分为本地策略路由、接口策略路由和智能策略路由SPR(Smart Policy Routing)【智能策略路由不在IP学习范围内】。
PBR和路由策略相似,由多个节点组成,每个节点都由匹配条件if-match和执行动作apply组成
语法、匹配原则均和Route-Policy相同

与路由策略Route-Policy不同的是,路由策略的操作对象是路由信息。路由策略主要实现了路由过滤和路由属性设置等功能,它通过改变路由属性(包括可达性)来改变网络流量所经过的路径。
而策略路由的操作对象是数据包,在路由表已经产生的情况下,不按照路由表进行转发,而是根据需要,依照某种策略改变数据包转发路径。
策略路由又分为本地PBR和接口PBR
本地PBR
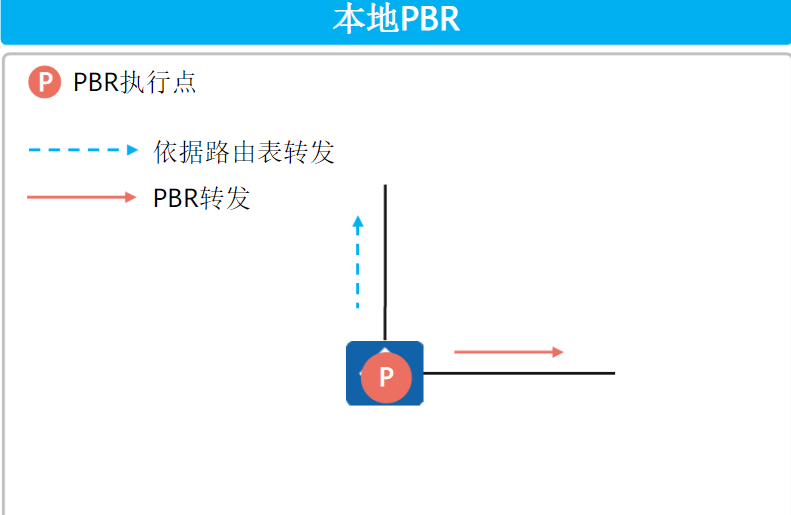
本地PBR对本地始发的流量生效,在系统视图中调用
命令配置:
# 创建策略路由
acl 2000 # 创建acl
rule 5 permit
policy-based-route local # 创建策略路由
if-match acl 2000
apply ip-address next-hop 10.1.1.1 # 指定匹配到的报文的下一跳
# 本地调用
ip local policy-based-route local
接口PBR
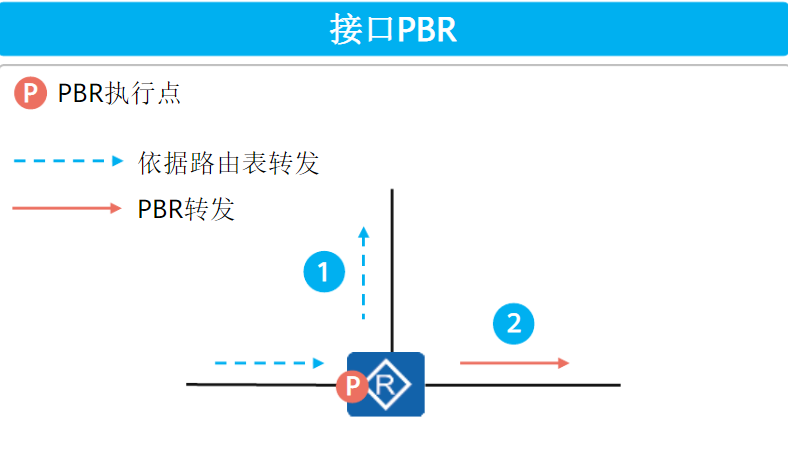
接口PBR只对转发的报文(经过本设备的报文)有效,对本地始发的报文无效
接口PBR只对接口入方向的报文生效
命令配置
# 创建策略路由
acl 2000 # 创建acl
rule 5 permit
policy-based-route inter # 创建策略路由inter
if-match acl 2000
apply ip-address next-hop 10.1.1.1 # 指定匹配到的报文的下一跳
# 接口调用
int g0/0/1
ip policy-based-route inter # 在g0/0/1口调用策略路由
MQC
MQC即模块化QoS命令行MQC,是属于IE级别QOS差分服务的知识点,只是由于MQC中的流行为支持重定向报文,所以可以使用MQC实现单播策略路由
分为四部分:流分类、流行为、流策略、应用流策略
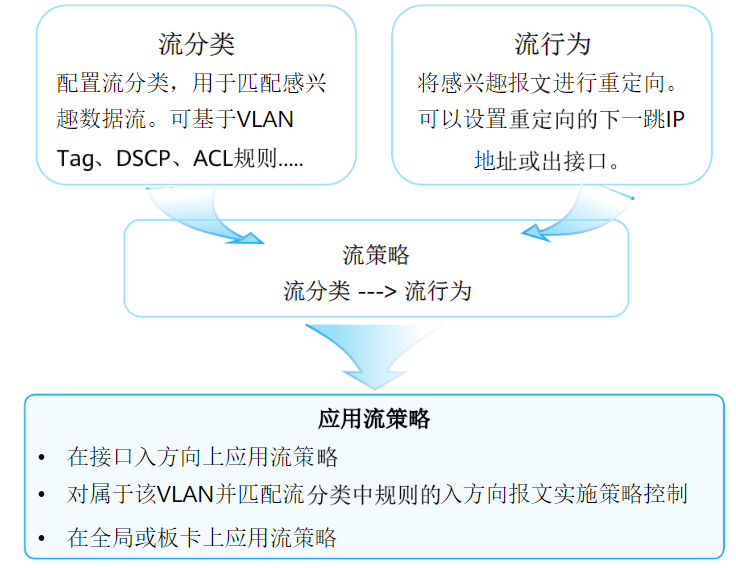
流分类
来定义一组流量匹配规则,以对报文进行分类。(流分类支持大量的匹配规则,这里不一一列举,有需要自行查询文档)
一条流分类中可以存在多个
if-match规则,各规则之间的关系分为:and或or,缺省情况下的关系为or。
命令配置:
traffic classifier fl operator or # 创建名为fl的流分类,各规则之间的关系为or
if-match vlan-id 1 # 匹配vlan
if-match acl 2000 # 匹配acl 2000
流行为
流行为用来定义针对某类报文所做的动作。
命令配置:
traffic behavior xw # 创建名为xw的流行为
redirect ip-nexthop 10.1.1.1 # 动作为重定向到10.1.1.1
一个流行为可以配置多个动作,但需要注意不能冲突
流策略
流策略用来将指定的流分类和流行为绑定,对分类后的报文执行对应流行为中定义的动作。
一个流策略可以绑定多个流分类和流行为。
不同于接口PBR只能处理入方向的流量,MQC流策略出入方向的流量都可以处理
策略中流行为匹配出入方向的报文,对匹配的报文执行相应的流动作
流策略在出口使用还是入口使用由具体的需求决定,比如流量重定向要在入口使用,而给报文加VLAN TAG在出口使用
命令配置:
traffic policy cl # 创建名为cl的流策略
classifier fl behavior xw # 将流分类"fl"和流行为"xw"绑定
流策略中一个流分类可以绑定给多个流行为,一个流行为也可以绑定给多个流分类
原则只有一个:不能冲突
应用流策略与配置检查
# 应用流策略
int g0/0/1 # 进入接口视图
traffic-policy policy-name { inbound | outbound } # 在出接口或者入接口应用流策略
# 配置检查
display traffic classifier [流分类名] 查看已配置的流分类信息
display traffic behavior [behavior-name] 查看已配置的流行为信息
display traffic policy user-defined [policy-name] 查看流策略的配置信息
display traffic-policy applied-record [policy-name] 查看指定流策略的应用记录
流量过滤:Traffic-Filter
traffic-filter用来在接口上配置基于ACL对报文进行过滤。出入方向均可使用,但建议在入方向使用
Traffic-Filter是否允许报文通过取决于acl的匹配结果,只有acl为【匹配、允许通过(permit)】时,报文才会被放行,deny和未匹配的报文均不放行
命令配置:
acl 2000
rule 5 permit
int g0/0/1
traffic-filter outbound acl 2000 # 按acl 2000的规则过滤接口出方向报文
BGP协议
BGP:边界网关路由协议(Border Gateway Protocol)
是一种实现自治系统AS之间路由可达的距离矢量路由协议
2006年之后单播IPV4网络使用的版本是BGP-4,其他网络(如IPV6)都使用MP-BGP(在BGP-4的基础上进行了扩展,在IPV6单播网络上称为BGP4+,在IPV4组播网络上称为MBGP [Multcast BGP])
IGP协议,如OSPF、ISIS,虽然可以很方便的传递路由,但是面对广域网动辄几十万的数据流量,还是不太够看
BGP基于TCP协议(端口号179),只传递路由信息,不传递拓扑信息,并且使用触发式更新而非周期式更新
BGP基本概念
自治系统AS
AS是指在一个实体管辖下的拥有相同选路策略的IP网络。
BGP网络中的每个AS都被分配一个唯一的AS号,用于区分不同的AS。
AS号分为2字节AS号和4字节AS号,其中2字节AS号的范围为1至65535,4字节AS号的范围为1至4294967295。支持4字节AS号的设备能够与支持2字节AS号的设备兼容。
BGP邻居类型
BGP邻居根据对端AS的不同分为IBGP和EBGP
EBGP:运行于不同AS之间的BGP称为EBGP。
为了防止AS间产生环路,当BGP设备接收EBGP对等体发送的路由时,会将带有本地AS号的路由丢弃。
IBGP:运行于同一AS内部的BGP称为IBGP。
为了防止AS内产生环路,BGP设备不将从IBGP对等体学到的路由通告给其他IBGP对等体。这个特点称为水平分割
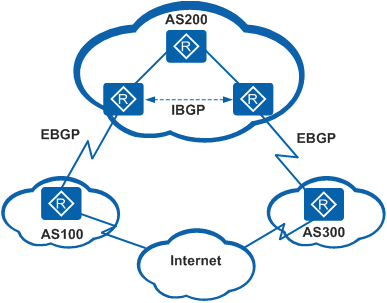
BGP报文交互的角色
BGP报文交互中将设备分为两种角色,Speaker和Peer
Speaker:发言者;发送BGP报文的设备Peer:对等体;相互交互报文的Speaker之间互称对等体。若干相同的对等体可以构成对等体组(Peer Group)
BGP 路由器号(Router ID)
和OSPF一样,BGP也用Router id唯一标识一台BGP设备,通常是IPv4地址的形式。
Router id在BGP会话建立时发送的Open报文中携带,每个BGP设备都必须有唯一的Router ID,否则对等体之间不能建立BGP连接。
Router id选举:
- 如果手工配置了Router id,则使用手工配置的
Router ID - 没有手工配置,BGP选择设备上的Loopback接口的IPv4地址作为BGP的Router ID。
- 如果设备上没有配置Loopback接口,系统会选择接口中最大的IPv4地址作为BGP的Router ID。
一旦选出Router ID,除非发生接口地址删除等事件,否则即使配置了更大的地址,也保持原来的Router ID。
BGP工作原理
BGP对等体的建立,更新和删除主要有5种报文,6个状态,5个原则
BGP报文
- OPEN:用于建立BGP对等体连接;
- Update:用于在对等体之间交换路由信息
- Notification:用于中断BGP连接
- Keepalive:用于保持BGP连接
- Route-refresh:用于在改变路由策略后请求对等体重新发送路由信息
- 只有支持路由刷新(Route-refresh)能力的BGP设备会发送和响应此报文。
BGP报文中除了Keepalive报文是周期发送,其他报文都是触发式发送
缺省情况,Keepalive报文每60s发送一次,如果180s内没有收到新的Keepalive报文,则认为邻居失效
BGP状态机
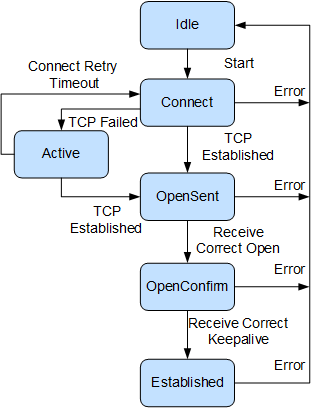
BGP状态机有6种:Idle、Connect、Active、OpenSent、OpenConfirm、Established
- Idle:设备没有开启BGP(管理员没有配置BGP)时设备处于Idle状态
- Connect:收到设备的Start事件后(配置BGP后),BGP开始尝试和其他对等体进行TCP连接,并转至Connect状态,在Connect状态下,BGP启动连接重传定时器(Connect Retry),等待TCP完成连接。
- Active:TCP连接失败,BGP转到Active状态
- OpenSent:TCP连接成功,BGP向对端发送Open报文,转至OpenSent状态
- OpenConfirm:在OpenSent状态下,BGP收到对等体的Open报文,在检查报文无误后,发送Keepalive报文,进入OpenConfirm状态
- Established:在OpenConfirm状态下,BGP收到Keepalive报文,转到Established状态
进入Establish状态标识着BGP对等体关系建立成功,可以交换Update、Keepalive、Route-refresh报文和Notification报文。
注意:
任何状态中收到Notification报文或TCP拆链通知等Error事件后,BGP都会转至Idle状态。
在Connect状态下,如果连接重传定时器超时,BGP仍没有收到BGP对等体的响应,那么BGP继续尝试和其它BGP对等体进行TCP连接,停留在Connect状态。
在Active状态下,如果TCP连接失败,那么BGP停留在Active状态,如果连接重传定时器超时,BGP仍没有收到BGP对等体的响应,那么BGP转至Connect状态。
如果收到错误的Update或Keepalive报文,那么BGP发送Notification报文通知对端,并转至Idle状态。
Route-refresh报文不会改变BGP状态。
BGP交互原则
- 从IBGP学习的路由,BGP设备只会发布给EBGP对等体【水平分割原则】
- 从EBGP学习的路由,BGP设备会发送给所有对等体
- 当存在多条到达同一目的地址的有效路由时,BGP设备只将最优路由发布给对等体。
- 路由更新时,BGP设备只发送更新的BGP路由。
- 所有对等体发送的路由,BGP设备都会接收。
BGP引入路由
BGP协议本身不生成路由,所有的BGP路由都从其他IGP引入
有两种引入方式:
- network:管理员手动逐条将IGP路由表中的路由引入BGP。引入是可以使用路由策略或进行路由过滤
- import:按协议批量将路由引入BGP。可以使用策略过滤
引入路由后,本端BGP设备会通过Update报文按BGP交互原则将变更的路由传递给对等体
早期文档认为聚合路由也是一种引入方式,但最新的文档上取消了这种说法
BGP基本配置
bgp 200 # 开启bgp,指定本设备属于AS 200
router-id [ipv4-address] # 可选,指定route-id
peer 10.1.45.5 as 300 # 和位于AS300,ip地址10.1.45.5的设备建立EBGP对等体关系
peer 10.1.45.5 connect-interface g0/0/1 # 指定发送BGP报文的源接口
peer 10.1.1.1 as 200 # 和位于AS 200,ip地址10.1.1.1的设备建立IBGP对等体关系
peer 10.1.45.5 connect-interface loop0 # 指定发送BGP报文的源接口
华为设备EBGP的最大跳数(TTL)默认为1,也就是只能经过一跳
如果使用环回口建立EBGP邻居关系,就需要更改EBGP最大跳数
peer x.x.x.x ebgp 255 # 更改到对等体x.x.x.x的最大跳数为255否则从环回口到发送者为一跳,发送者到EBGP对等体又为一跳,报文经过跳数>1,BGP报文被丢弃
引入路由:
import-route ospf 10 # 引入进程号为10的ospf路由
network 10.1.1.1 32 # 将路由表中10.1.1.1/32的路由条目宣告入BGP
BGP支持多种协议,包括IPV4、IPV6、VPNv4等等
根据网络类型,BGP将不同协议的对等体划入了不同的簇(集群),IPv4是
ipv4-family、IPv6是ipv6-family在BGP中配置的任何不与BGP本身相关的命令,都需要在对应的簇中配置,如
ipv4应该配置为:
- peer宣告对等体、指定源接口不区分簇,但需要在对应簇中开启对等体
bgp 200 peer 10.1.2.2 as-number 200 peer 10.1.2.2 ebgp-max-hop 2 peer 10.1.2.2 connect-interface LoopBack0 ipv4-family unicast # 进入ipv4单播簇 peer 10.1.2.2 enable network 100.100.100.100 32但这里华为为IPv4单播配置了“快捷方式”,在BGP视图做的属于簇的配置,默认划入
ipv4-family uncast簇。同时宣告的对等体会自动在ipv4单播簇开启所以才可以进行如下配置:
bgp 200 # 开启bgp,指定本设备属于AS 200 peer 10.1.2.2 as-number 200 peer 10.1.2.2 ebgp-max-hop 2 peer 10.1.2.2 connect-interface LoopBack0 network 100.100.100.100 32除ipv4单播簇外,其他簇必须进入对应的视图配置
注:这个特点华为特有,如华三的设备必须去对应簇配置,同时对等体也不会在ipv4单播簇开启
BGP检查命令:
display bgp peer [ verbose ] # 查看所有BGP对等体的信息
display bgp peer ipv4-address { log-info | verbose } # 查看指定BGP对等体的信息
display bgp routing-table # 查看BGP路由表
display bgp group [ group-name ] # 查看对等体组信息。
BGP路由优选规则
BGP只会向对等体传递最优且有效的路由,BGP为了选出最佳路由,会根据BGP的路由优选规则依次比较路由的BGP属性
当NextHop可达,就认为该路由有效,否则路由无效。
对于无效路由,BGP会将其写入BGP路由表,但不会传递给其他对等体
BGP路由属性
BGP属性分为四种:

- 公认必遵(Well-known mandatory):所有BGP设备都可以识别此类属性,且必须存在于Update报文中。如果缺少这类属性,路由信息就会出错。
- 公认任意(Well-known discretionary):所有BGP设备都可以识别此类属性,但不要求必须存在于Update报文中,即就算缺少这类属性,路由信息也不会出错。
- 可选过渡(Optional transitive):BGP设备可以不识别此类属性,如果BGP设备不识别此类属性,但它仍然会接收这类属性,并通告给其他对等体。
- 可选非过渡(Optional non-transitive):BGP设备可以不识别此类属性,如果BGP设备不识别此类属性,则会被忽略该属性,且不会通告给其他对等体。
公认必遵属性
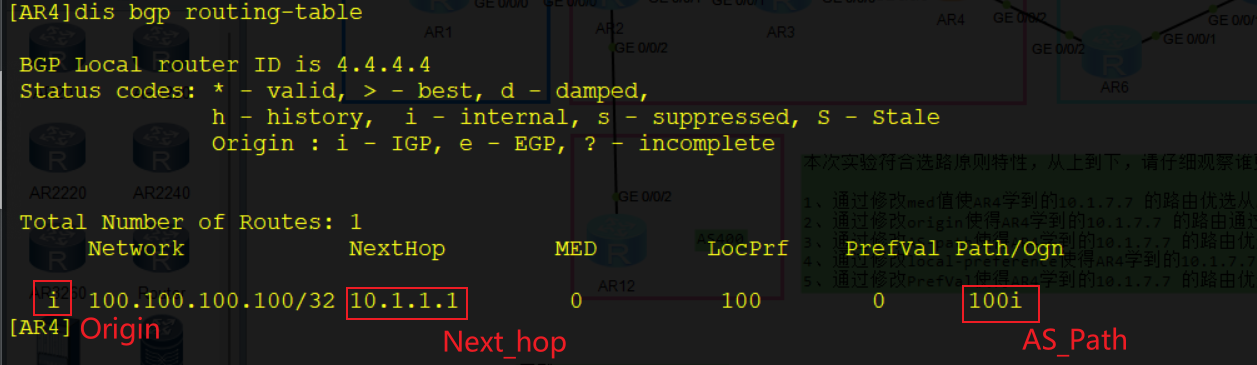
Origin:路由源;定义路径信息的来源,标记一条路由是怎么成为BGP路由的。有三种类型:
- IGP:具有最高的优先级。通过network命令注入到BGP路由表的路由,其Origin属性为IGP
- EGP:优先级次之。通过EGP协议得到的路由信息,其Origin属性为EGP。(EGP协议已经弃用)
- Incomplete:优先级最低。通过其他方式学习到的路由信息。比如通过import-route引入的路由和聚合的路由
Origin属性只能通过修改引入路由的方式更改
AS_PATH:AS路径;按矢量顺序记录了某条路由从本地到目的地址所要经过的所有AS编号
- 在接收路由时,设备如果发现AS_Path列表中有本AS号,则不接收该路由,从而避免了AS间的路由环路
- BGP将路由通告给对等体时,就会在Update报文的AS_PATH列表中携带本地AS号(添加在AS_Path列表最左端)
- AS_PATH越短越优
AS_PATH分为两种类型: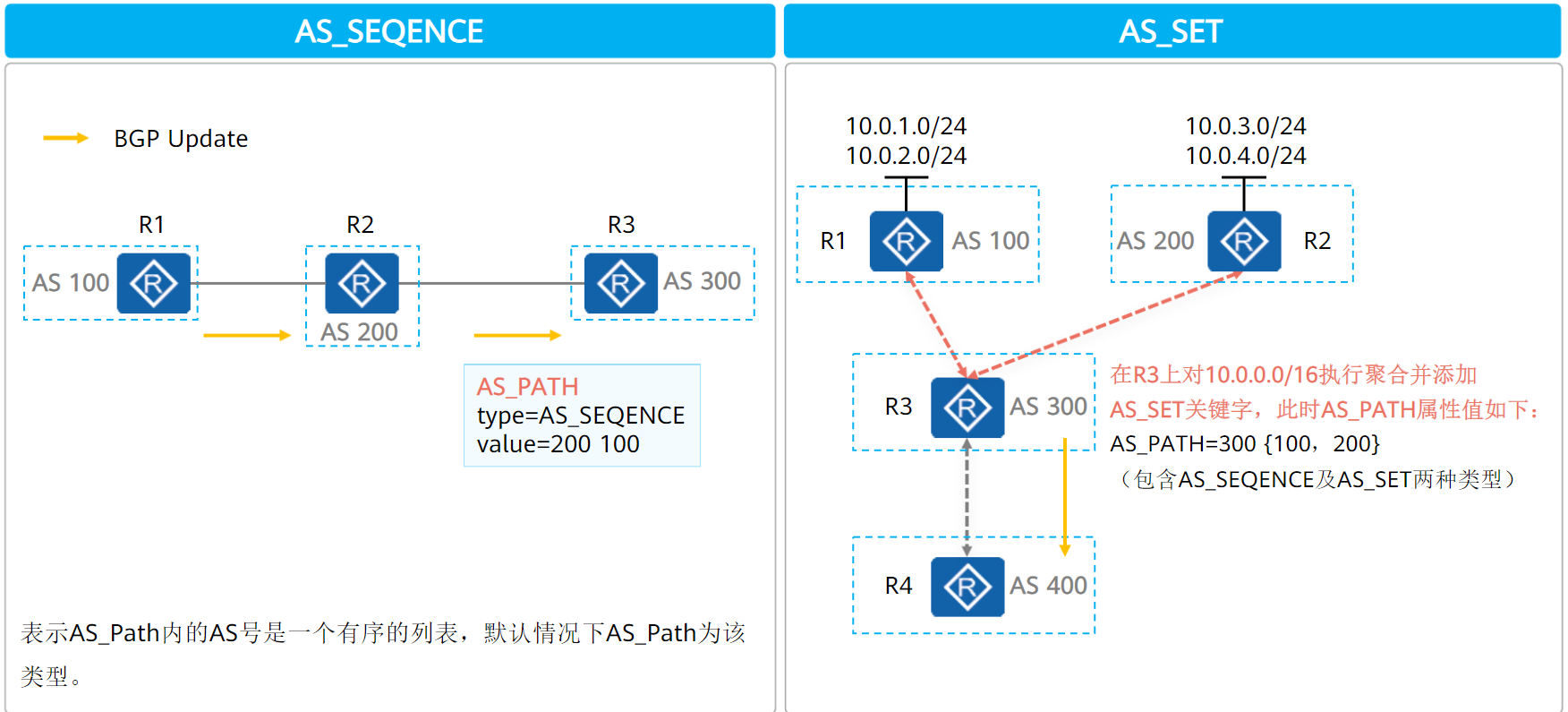
一般情况下,AS_PATH都是AS_SEQENCE类型
只有在路由从两个等价的AS都可以学到时,BGP会将两个AS号都写入AS_PATH,并且为了表示这两条路由等价,使用集合({AS1,AS2})表示这个AS_PATH
这种使用了集合的AS_PATH是AS_SET类型,一般常见于路由聚合的位置
BGP允许通过修改AS_PATH来影响路由选路,有三种修改方式:
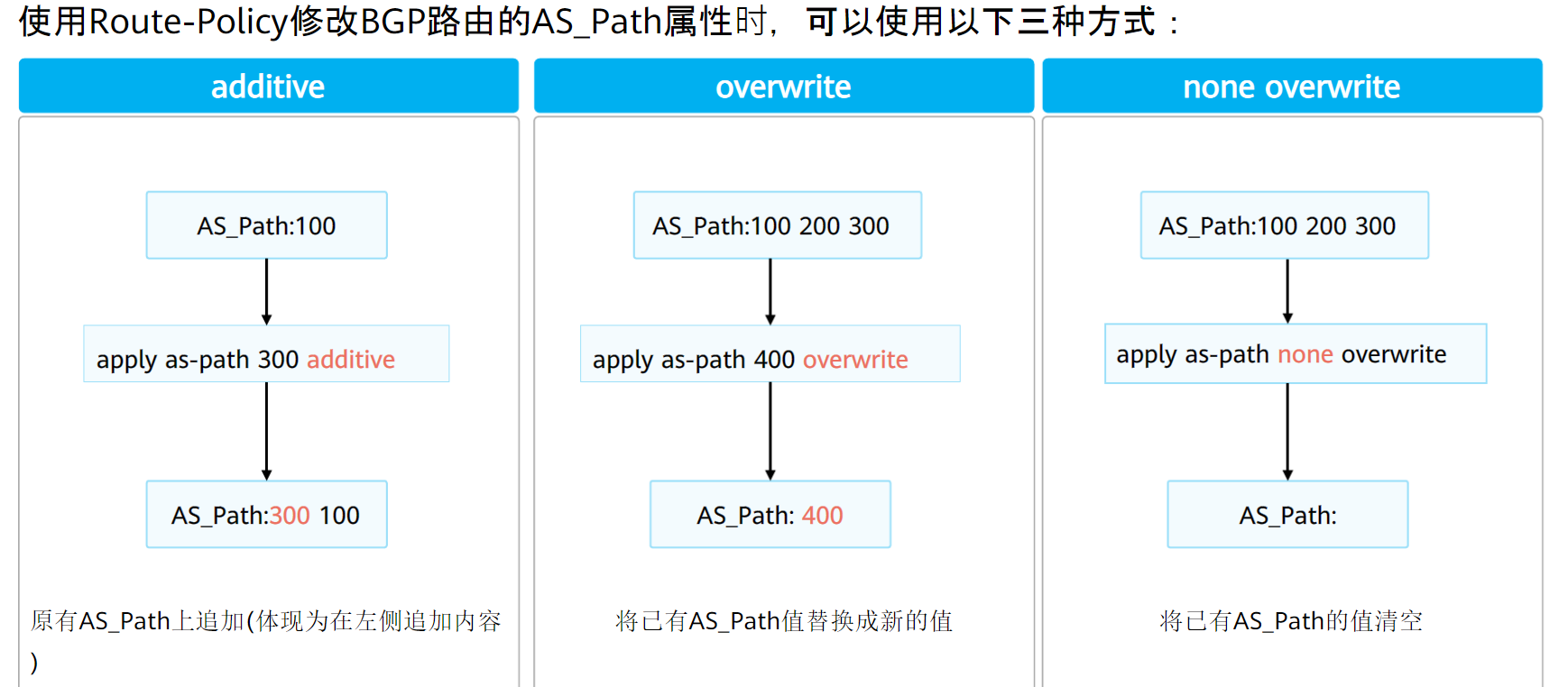
由于公网路由不好控制,为避免影响路由在其他AS的传递,一般只会在接收AS中修改AS_PATH属性
也可以在EBGP宣告时使用策略多加几个上一跳AS的AS号,这样也不会影响到其他AS
# AS 100的路由传递到AS 200时 route-policy as permit node 10 apply as-path 100 100 100 100 additive # 加上4个AS 100 bgp 100 ipv4-family unicast peer 10.1.2.2 route-policy as export # 使用策略
Next_hop:下一跳;记录了路由的下一跳信息
BGP路由不会像IGP一样每次都更新下一跳,而是遵循以下原则:
- 向EBGP对等体发布路由时,下一跳属性为本地与对端建立BGP邻居关系的接口地址。
- 将本地始发路由发布给IBGP对等体时,下一跳属性为本地与对端建立BGP邻居关系的接口地址。
- 向IBGP对等体发布从EBGP对等体学来的路由时,不改变该路由信息的下一跳属性。
收到下一跳不可达的路由,BGP会将其写入BGP路由表,但不会传递给其他对等体
通过命令可以更改下一跳:
bgp 100
ipv4-family unicast
peer 10.1.2.2 next-hop-local # 向对等体10.1.2.2传递路由时将下一跳设为自已
———— 本地与对端建立BGP邻居关系的接口地址。
peer 10.1.2.2 next-hop-invariable # 向对等体10.1.2.2传递路由时不改变下一跳
这两个配置前者用于给IBG传递路由的场景,后者用于MPLS VPN C方案旁挂RR反射器的场景
公认任意属性
Local_Preference:本地优先级;表明路由器的BGP优先级,用于判断流量离开AS时的最佳路由
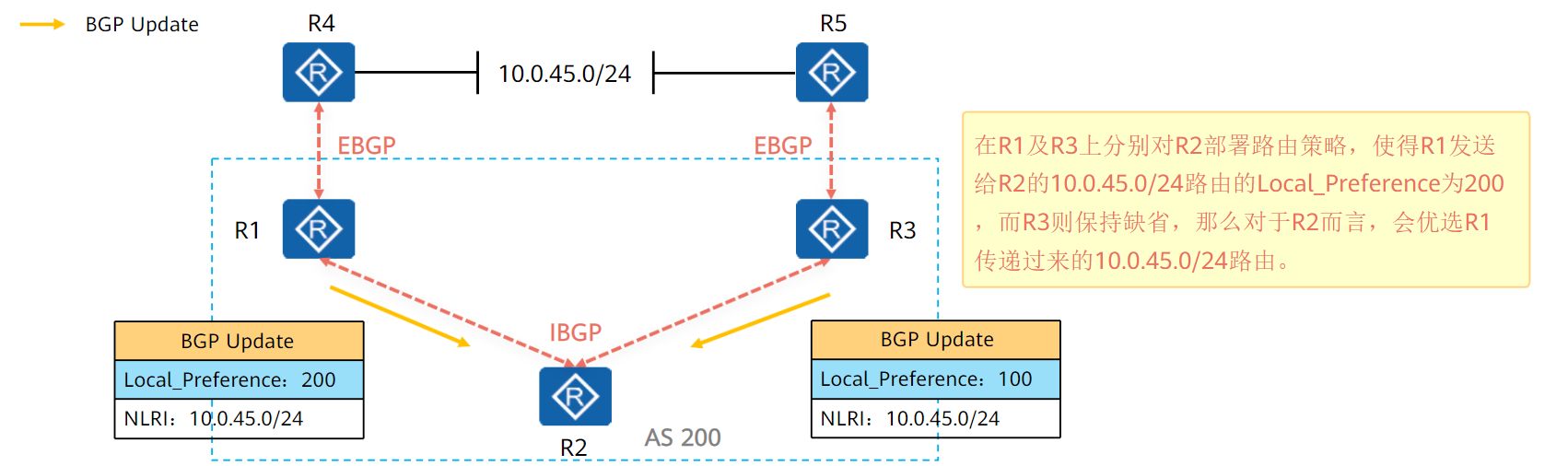
当BGP的设备通过不同的IBGP对等体得到目的地址相同但下一跳不同的多条路由时,将优先选择Local_Pref属性值较高的路由。
Local_Pref属性仅在IBGP对等体之间有效,不通告给其他AS。
Local_Pref属性可以手动配置,如果路由没有配置Local_Pref属性,BGP选路时将该路由的Local_Pref值按缺省值100来处理。
配置命令:
route-policy local_pre permit node 10
apply local-preference 200 # 修改本地优先级为200
bgp 300
ipv4-family unicast
peer 10.1.7.7 route-policy local_pre export
Atomic_aggregate:自动聚合
同可选任意属性aggregate一样,用于聚合路由,不直接影响选路
配置自动聚合后,生成的聚合路由会被打上Atomic_aggregate属性,标识这是通过自动聚合得到的路由
命令配置:
bgp 200
ipv4-family uncast
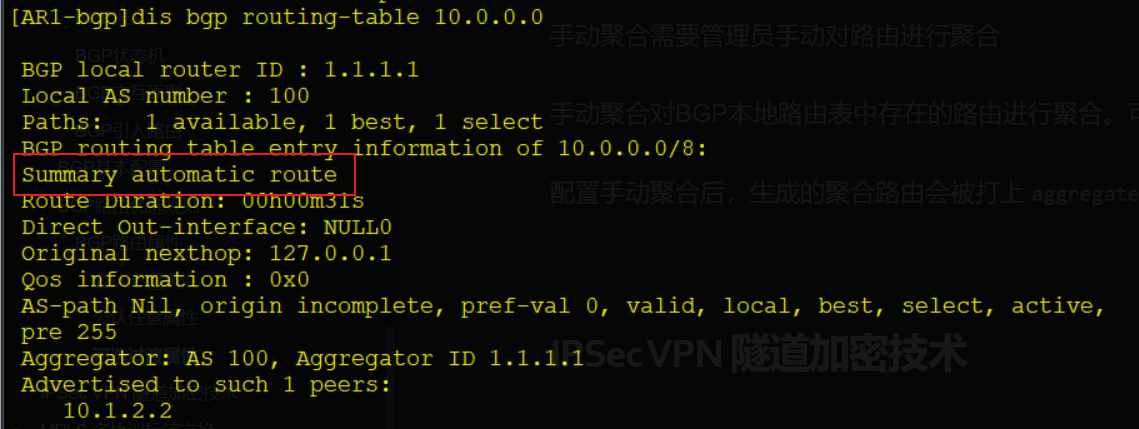
summary automatic # 自动对BGP引入的路由进行聚合,对network和其他对等体通告的无效
一般在BGP中不考虑使用自动聚合,因为自动聚合不受控制并且只能聚合为标准掩码的路由条目(/0 /8 /16 /24 掩码即为标准掩码)
自动聚合会自动抑制明细路由,优先级低于手动聚合

聚合生成的路由条目Next_Hop变为自身
IPv4网络中支持自动聚合和手动聚合两种方式,而IPv6网络中仅支持手动聚合方式
可选过渡属性
aggregate:手动聚合
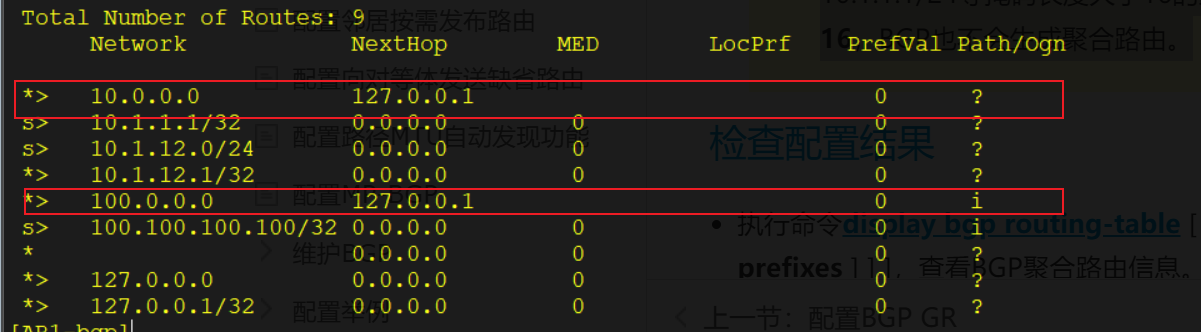
手动聚合需要管理员手动对路由进行聚合
手动聚合对BGP本地路由表中存在的路由进行聚合。可以控制聚合路由的属性,以及决定是否发布明细路由。
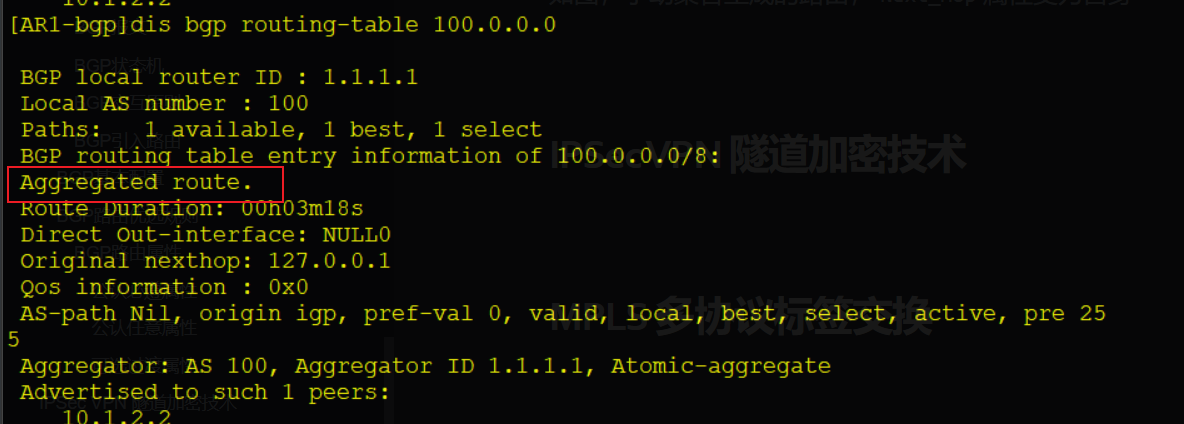
配置手动聚合后,生成的聚合路由会被打上aggregate属性,标识这个通过手动聚合得到的路由条目
手动聚合对BGP本地路由表中已经存在的路由表项有效,例如BGP路由表中不存在10.1.1.1/24等掩码长度大于16的路由,即使配置了命令aggregate 10.1.1.1 16,BGP也不会生成聚合路由。
bgp 100
ipv4-family unicast
aggregate 100.0.0.0 8 detail-suppressed # 手动聚合路由并且抑制明细
如图,手动聚合生成的路由,Next_Hop属性会变为自身
Community:团体属性;用于标识具有相同特征的BGP路由,使路由策略的应用更加灵活,同时降低了维护管理的难度。
团体属性是一种路由标记,不影响路由选路,只用来简化路由策略的执行
通过给特定路由打上团体属性的方式,使后续做策略时只需要匹配拥有相同属性的路由。而不是一条一条去抓
团体属性分为自定义团体属性和公认团体属性:
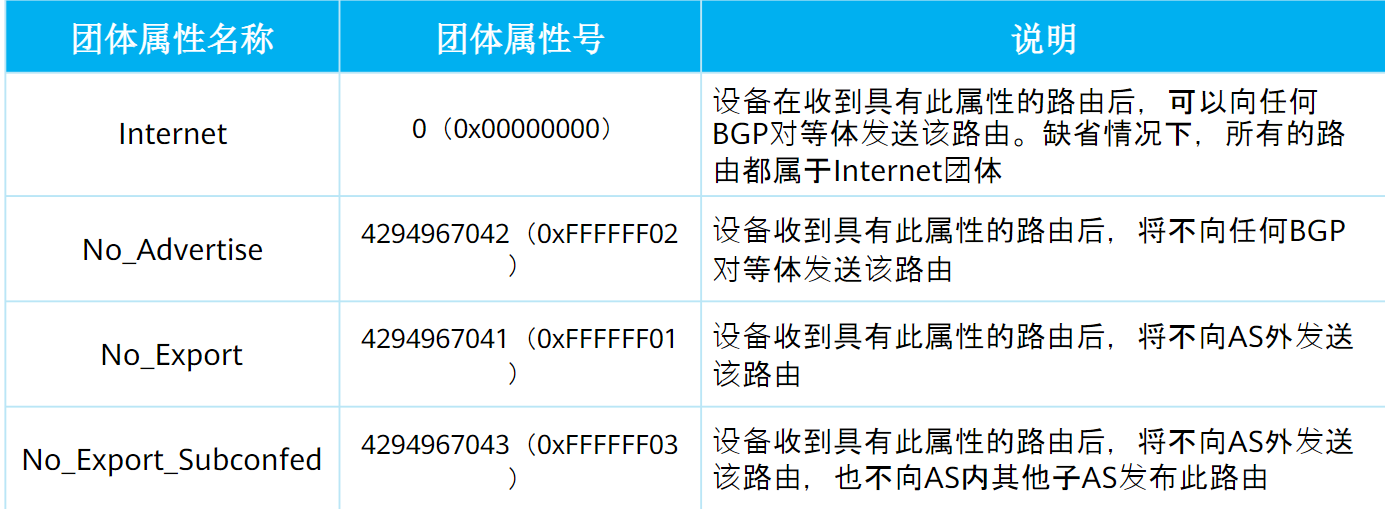
公认团体属性:BGP提供的,并且做了默认策略的属性,有四种:
自定义团体属性:BGP没有做默认策略,由管理员自己命名,手动配置策略的属性
自定义团体属性有两种命名方式:
- 十进制整数形式
AA:NN格式,AA表示AS号,NN是自定义编号
常用
AA:NN的格式创建自定义团体属性团体属性总长
4byte,对于AA:NN格式,AA和NN分别占2byte,对于十进制整数随意
可选非过渡属性
MED:(Multi-Exit Discriminator)多出口鉴别器;用于判断流量进入AS时的最佳路由
当一个AS收到对端同一AS不同EBGP传递的目的地址相同但是下一跳不通的路由时,在其他条件相同的情况下,优选MED值小的路由
注意:必须是同一AS的不同EBGP,不同AS的开销策略可能不同,所以不同AS的MED没有可比性
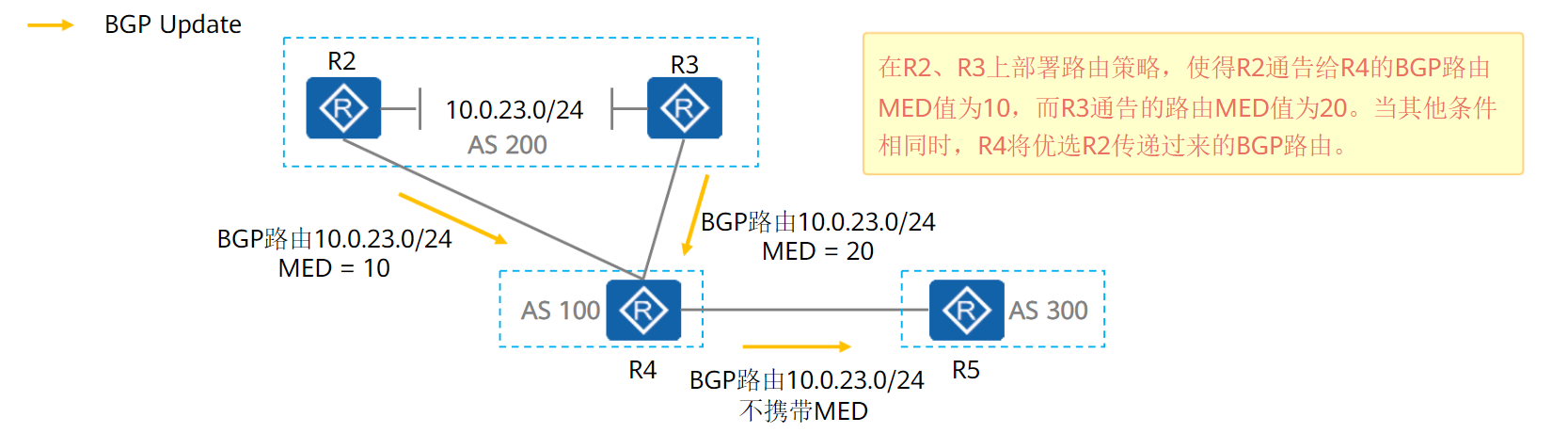
MED属性传递原则:
- 如果BGP路由是本地始发的,则携带MED属性发送给EBGP对等体
- 如果路由是从其他BGP学到的,则不会向EBGP发送MED属性
- IBGP对等体之间传递路由,MED会被保留,除非部署了策略,否则MED传递过程中不发生改变
总结就是:MED属性仅在相邻两个AS之间传递,收到此属性的AS一方不会再将其通告给任何其他第三方AS
可以在出口通过策略加上MED
简单理解:路由器只会处理经过本路由器的MED,并且不会将经过本路由器的MED发给EGBP对等体
第一条之所以可以发给EBGP,本质是因为MED是路由出路由器时由策略加上的,路由器本身并没有对MED进行检查,MED没有“经过”这台路由器
缺省情况下,BGP路由生成时(将IGP路由宣告进BGP),MED值为该路由在IGP路由表中的开销
缺省MED可以通过命令修改
配置命令:
# 配置策略将一个EBGP路由条目10.1.7.7的开销改为100,另一个改成200
// 另一个略
acl number 2000
rule 5 permit source 10.1.7.7 0
route-policy med permit node 10
if-match acl 2000
apply cost 100
route-policy med permit node 20
# 在BGP中引入策略,另一个EBGP略
bgp 300
ipv4-family unicast
peer 10.1.45.4 route-policy med export

其他命令:
bgp 200
default med [value] # 修改生成路由条目时med缺省值,只对import有效
Cluster-List:簇列表
Cluster List和Originator ID只用于存在路由反射器的场景中
BGP中,路由反射器和反射器的客户组成一个集群(Cluster)或者称为反射簇,每一个反射簇都有唯一的一个Cluster-id
由于反射器传递路由本质上打破了BGP水平分割原则,为了避免环路,BGP用Cluster-List属性记录路由经过的反射簇
Cluster-List不影响路由选路
- 当一条路由被反射器反射时,RR会把本地的Cluster-id加在Cluster-List前面。如果路由还没有Cluster-List属性,RR会创建一个
- 当RR接收一条路由时,检查Cluster-List。如果本地的Cluster-ID在列表中,丢弃该路由
Originator ID:发布源ID
Originator ID由RR产生,使用的Router ID的值标识路由的始发者,用于防止反射簇内产生路由环路。
Originator ID防止反射簇内环路,Cluster List防止反射簇间环路
当一条路由被反射器反射时,RR会将
Originator_ID属性加入这条路由,值为通告该路由的BGP路由器router id[不是反射器router id];如果路由中存在
Originator_ID,RR不会创建新的Originator_ID其他设备接收这条路由时,会比较收到的Originator ID和本地的Router ID,如果两个ID相同,则不接收此路由。
BGP路由优选规则

BGP路由优选规则如图所示
华为和思科有所不同,华为是11条,思科是13条
这是由于华为将【丢弃下一跳不可达路由】和【当前8条属性全部相同时可以形成路由负载分担】视为默认条件,而不是具体规则
规则优先级越往上越优先,其中前两条规则对应属性取值越大越优先,后9条对应属性取值越小越优先(如果存在取值)
Preference-value:
第一条规则的
preference-value(协议首选值)属性华为私有,默认值为0且不是BGP属性,所以没有传递给其他BGP对等体一说,只能在配置该属性的设备本身生效
当BGP路由表中存在目的地址相同的路由时,优先选择
Prefrenece-value值高的路由,取值范围0-65535思科中存在相似的属性,叫做 “权值”
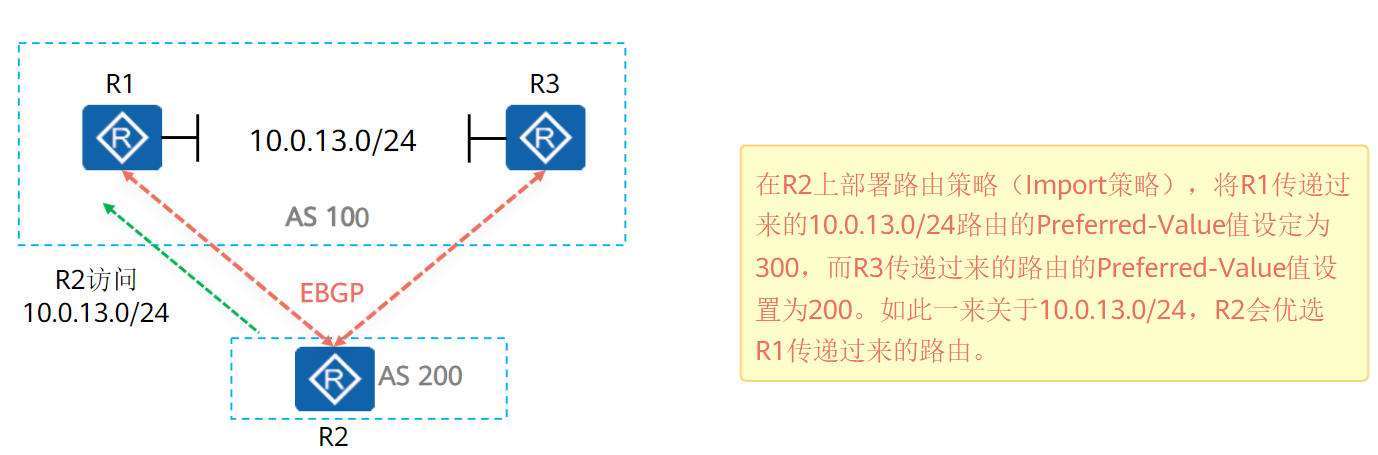
Preference-value属性配置:
bgp 300
ipv4-family unicast
peer 10.1.5.5 preferred-value 100 # 设置从5.5学到的路由协议首选值为100
peer 10.1.6.6 preferred-value 200 # 设置从6.6学到的路由协议首选值为200
由于Preference-value不传递给其他对等体,所以对BGP网络影响最低
路由负载分担:
当前8条属性相同时可以负载分担,但默认不会进行负载,而且继续9、10、11条选路规则
如果想要进行负载分担,在前8条属性相同的基础上,还需要开启如下配置
bgp 300
maximum load-balancing ibgp 2 # 指定最大等价路由数目,范围1-8
最大等价路由数目为2,就是支持将两条等价路由进行负载

如果实现了BGP负载分担,则不论是否配置了
peer next-hop-local命令,本地设备向IBGP对等体组发布路由时都先将下一跳地址改变为自身地址。实现了负载分担的设备将路由发送给邻居时,仍然会继续比较后续的选路规则,发送最优的路由
公网中到达同一目的地的IBGP路由和EBGP路由不能形成负载分担
路由反射器——RR
为保证IBGP对等体之间的连通性,需要在IBGP对等体之间建立全连接关系。
当设备数目很多时,设备配置将十分复杂,而且配置后网络资源和CPU资源的消耗都很大。在IBGP对等体间使用路由反射器可以解决以上问题。
路由反射器将一个AS的BGP设备分为以下角色:
- 路由反射器RR(Route Reflector):把从IBGP对等体学到的路由反射到其他IBGP对等体的BGP设备
- 客户机(Client):与RR形成反射邻居关系的IBGP设备。在AS内部客户机只需要与RR直连。
- 非客户机(Non-Client):既不是RR也不是客户机的IBGP设备。
- 始发者(Originator):在AS内部始发路由的设备。Originator_ID属性用于防止集群内产生路由环路。
- 集群(Cluster):路由反射器及其客户机的集合。Cluster_List属性用于防止集群间产生路由环路。
路由反射器破坏了水平分割原则,为避免环路,引用了可选非过渡属性中的
Cluster ID属性和Originator ID属性除RR外的其他设备无需任何特殊配置,这些设备并不知道网络中存在RR
路由反射器遵从以下规则进行路由反射:
- 从客户机学到的路由,发布给所有非客户机和客户机(发起此路由的客户机除外)
- 从非客户机学到的路由,发布给所有客户机
- 从EBGP对等体学到的路由,发布给所有的IBGP对等体
路由反射器配置:
bgp 300
peer 10.1.2.2 as-number 200
peer 10.1.2.2 connect-interface LoopBack0
ipv4-family unicast
peer 10.1.2.2 enable
peer 10.1.2.2 reflect-client # 将10.1.2.2设置为Client
路由反射器除了会将从IBGP学到的路由传递给其他IBGP之外,和普通的IBGP没有区别
IPv4 组播
基本概念
在传统的IP网络中,单播路由在处理点到多点问题(直播、游戏)时,会向不同的终端发送大量相同的数据,这导致了网络带宽的浪费
而可以将数据发送给多个终端的广播又有很多问题,包括不安全、会将报文发送给本不需要该报文的主机等等
为了处理点到多点场景,提出了组播网络的概念
组播是基于UDP的技术
组播IP与组播MAC
以太网链路传输组播数据时,目的IP和目的MAC地址都不在指一个具体的接口或者终端,而是一个成员不确定的组
为此,以太网定义了组播IP地址和组播MAC地址
- 组播IP地址:IPv4地址划分的D类地址既是组播IP地址,范围从
224.0.0.0-239.255.255.255,没有掩码 - 组播MAC地址:IANA规定,IPv4组播MAC地址高24位为
0x01005e,第25位为0。低23位和组播IP地址映射
组播IP地址范围如下:
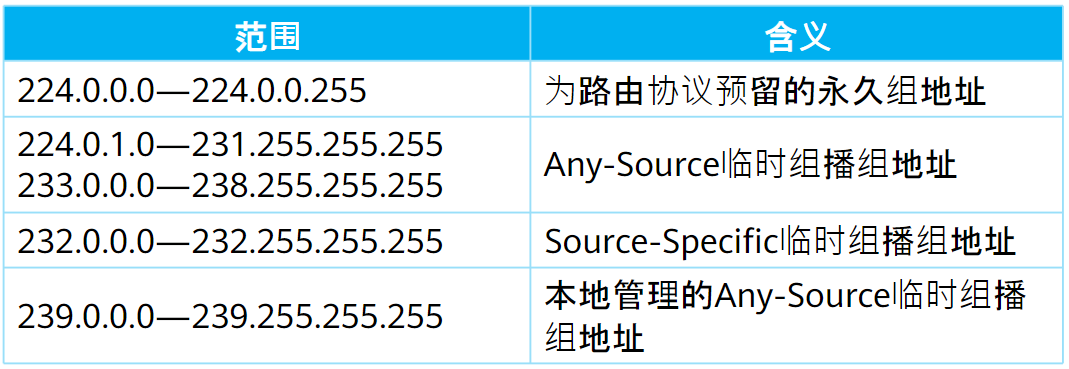
常见的永久组地址:
224.0.0.0:不分配224.0.0.1:组播专用,网段内所有主机和路由器(等效于广播地址)224.0.0.2:所有组播路由器默认加入该组224.0.0.5:OSPF路由器224.0.0.6:OSPF DR专用224.0.0.9:RIPv2路由器224.0.0.12:DHCP服务器/中继224.0.0.13:所有PIM路由器224.0.0.18:VRRP224.0.0.22:使能IGMPv3的路由器
之所以组播MAC很奇怪,涉及到组播研发时的历史小故事,如下图。

由于这个历史原因,组播IP向组播MAC映射时会存在5个bit的信息丢失
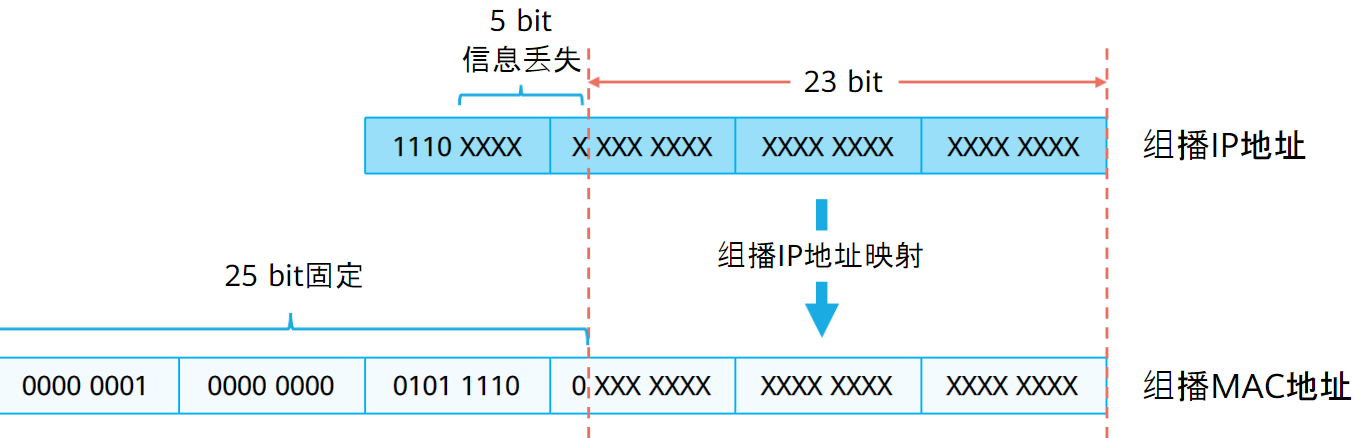
IP地址第2个字节此时只有7个bit可以映射,所以地址范围只能从0-127
这也就意味着224.0.1.1和224.128.1.1、225.0.1.1….共用一个MAC
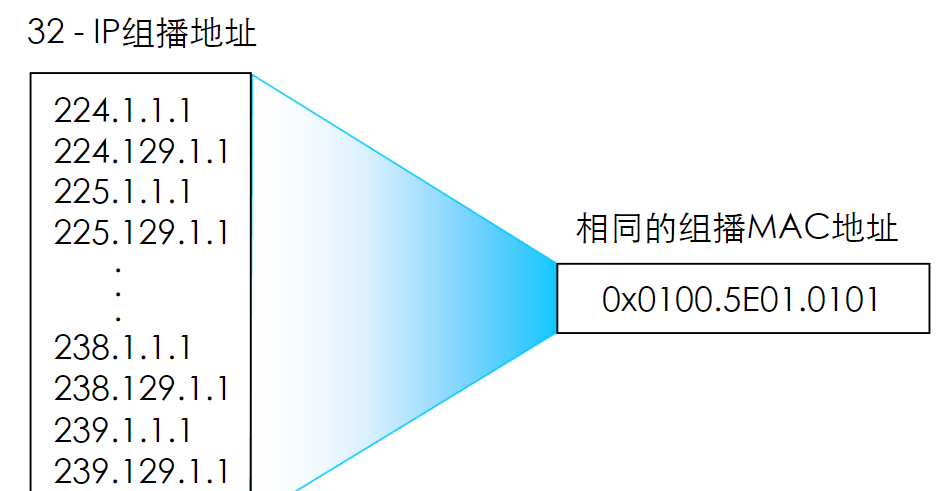
也就是32个组播IP对应一个组播MAC,为了避免MAC地址冲突,配置组播时要避免在同一二层网络中配置MAC冲突的IP地址
组播网络架构
组播传输的特点是单点发送,多点接收。一个完整的组播网络可以分为三个部分:
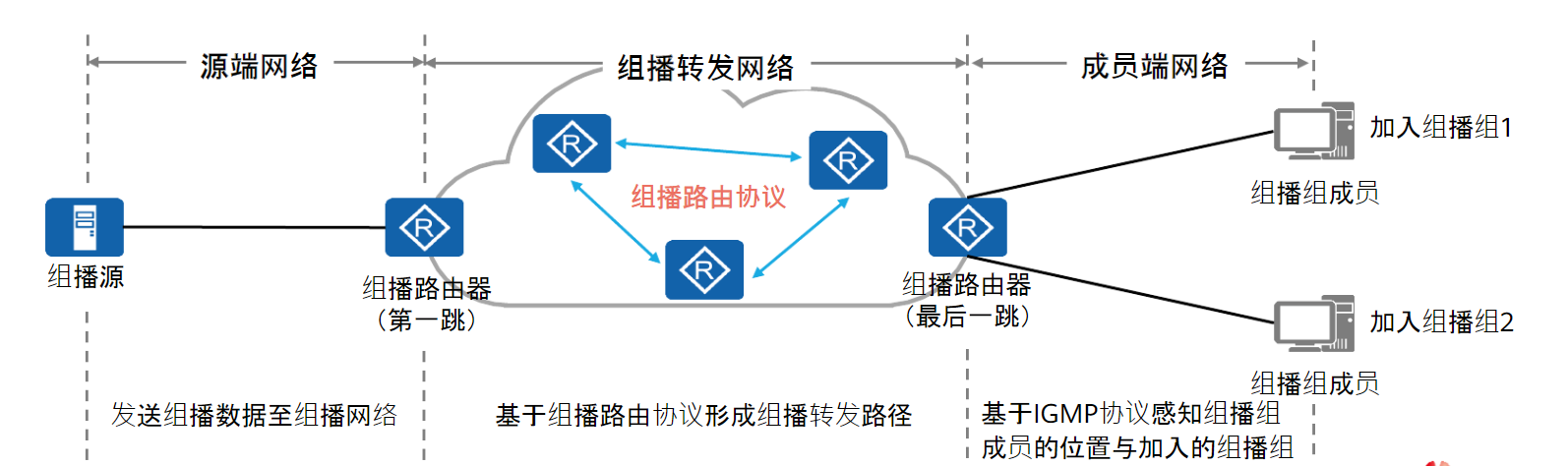
- 源端网络:组播数据的发送者,一般不需要特殊配置
- 组播转发网络:通过组播协议,形成组播路由的转发路径,这个转发路径有也称为组播分发树
- 成员端网络:让组播转发网络感知到组播组成员的位置
名词解释:
- 组播组:用IP组播地址进行标识的一个集合。任何用户主机(或其他接收设备),加入一个组播组,就成为了该组成员,可以识别并接收发往该组播组的组播数据。
- 组播源:组播信息的发送者称为“组播源”。
- 组播组成员:所有加入某组播组的主机便成为该组播组的成员
- 组播路由器:支持三层组播功能的路由器或交换机
组播服务模型
由于一个组播源可以同时向多个组播组发送数据,多个组播源也可以同时向一个组播组发送报文
根据组播组成员是否可以指定组播组内的一个或多个组播源,将组播网络分为ASM和SSM两种服务模型
- ASM:组成员不可指定接收组播源,任意组播源发送到该组的数据都会被接收。
- 组
224.1.1.1中有源A和源B,那么加入224.1.1.1的组成员会同时收到来自两个源的数据
- 组
- SSM:组成员可以指定只接收哪些源的数据或指定拒绝接收来自哪些源的数据。
- 组
224.1.1.1中有源A和源B,加入224.1.1.1的组成员可以选择只接收A或者只接收B或两个都接收
- 组

相比之下,ASM模型会导致网络流量拥塞,另一方面也会给接收者主机造成困扰,所以现网组播一般使用SSM服务模型
组播转发原理
组播协议
组播网路分为源端网络、组播转发网络和成员端网络
源端网络由组播路由器自主判断,无需多余的配置
组播转发网络常用三种协议:
- PIM-协议无关组播:用于生成AS域内的组播分发树
- MSDP-组播源发现协议:用于帮助生成AS域间的组播分发树
- MBGP-组播BGP:帮助跨域组播流量进行RPF校验
成员端网络使用IGMP(因特网组管理协议),用于告知组播网络组播组成员的位置和加组信息
组播路由表和RPF检查
组播数据转发需要依靠组播路由表
由于组播网络点到多点的特点,组播报文转发很容易出现环路、次优路径、重复报文等问题
为了在组播转发网络中得到一个无环无次优的组播分发树(组播转发路径),组播使用了RPF检查机制
PRF(反向路径转发)检查:
组播路由器收到组播数据时,路由器根据组播报文中组播源的单播IP地址反向从本设备的单播路由表中查找去往该组播源的出接口
接着对比查到的出接口是否和组播数据入接口一致
- 一致:说明接收组播数据的接口是最优的接口,接收组播数据并写入组播路由表
- 不一致:说明接收组播数据的接口非最优,丢弃组播报文
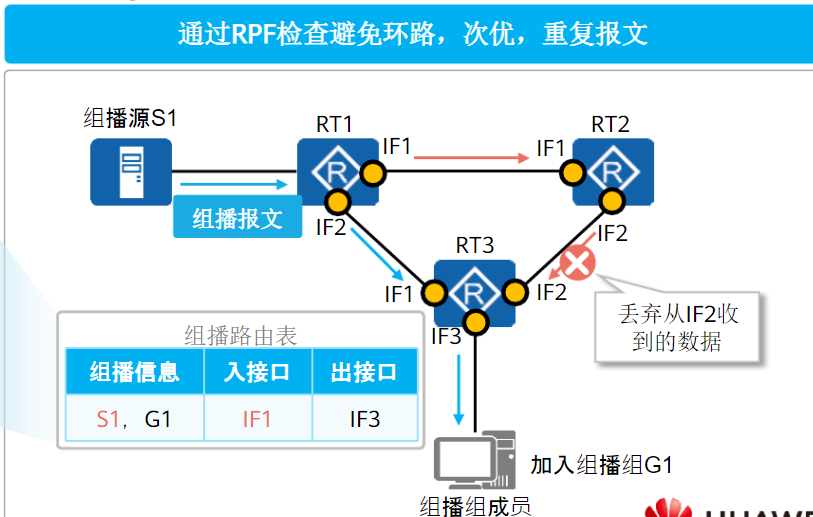

所以组播组网的前提是单播可达
RPF选举时遵循如下规则:
RPF会通过报文源地址,分别从单播路由表、MBGP路由表和组播静态路由表中各选出一条最优路由,然后按下列顺序选最优的一条路由
- 遵循掩码最长匹配原则
- 掩码长度相同时,选路由优先级最高的路由
- 优先级也一致,按组播静态路由、MBGP路由、单播路由的顺序进行选择。
最优路由的出接口就是要和组播数据入接口对比的RPF接口
IGMP协议
IGMP-因特网组管理协议,是用于组播路由成员端网络的三层协议。同IGMP Snooping一起共同维护成员端网络的组播数据转发
目前为止,IGMP有三个版本:IGMPv1,IGMPv2,IGMPv3
三个版本是逐步更新的结果,尽管各个版本的协议报文格式不同,但是运行IGMP高版本的路由器可以识别低版本的IGMP报文。
所有的IGMP都支持ASM(任意源组播)服务模型,但只有IGMPv3支持SSM(指定源组播)服务模型,如果想让v1和v2使用SSM模型,则需要配合IGMP SSM Mapping技术使用
组播网络感知组播组成员有两种方法:
- 手工静态配置:在组播路由器上静态指定连接组播组成员的接口【麻烦,而且不适用】
- 动态感知:通过IGMP协议通知组播网络,组播网络通过IGMP消息感知组成员所在接口
除非设备不支持IGMP且没有任何代替的方法,否则不建议静态配置
IGMPv1
v1版本是最初的IGMP,只有两种类型的报文:
- 普遍组查询报文(General Query):查询器向网络上所有主机和路由器发送的查询报文,用于了解哪些组播组存在成员。
- 成员报告报文(Report):主机向查询器发送的报告报文,用于申请加入某个组播组或者应答查询报文。
IGMP工作机制流程如下:
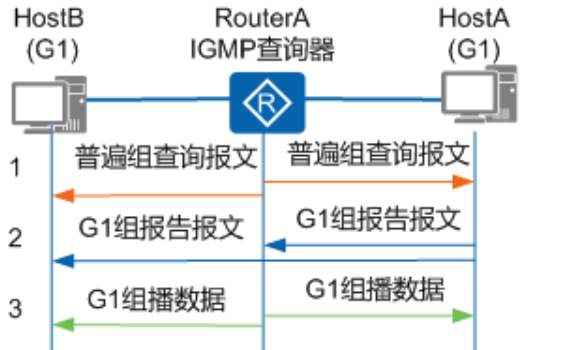
- 查询器发送普遍组查询报文,目的IP
224.0.0.1(相当于在整个网络中广播)- 普遍组查询报文周期性发送,缺省为60s
- 组成员收到该查询报文,启动一个定时器,范围是0-10s的随机值
- 定时器超时后,组成员发送针对该组的报告报文。
- 想加入该组但定时器还没有超时的组成员收到此报告报文,则停止定时器,并且不再发送针对该组的报告报文。【报告报文抑制机制】
- 查询器收到报告报文后,创建IGMP组表项,如果启用了PIM协议,则同时创建一个(*,G)组播表项
*代表任意组播源。网络中一旦有组播组G的数据到达路由器,将向该网段转发。
IGMPv1没有定义组成员离组机制,默认130s内没有收到组成员报告报文则认为组成员离组,删除对应的IGMP组表项和PIM产生的(*,G)表项
对于组播而言,知道接口下有几个成员是没有意义的,IGMP查询器只需要知道接口下有起码一个组成员就可以
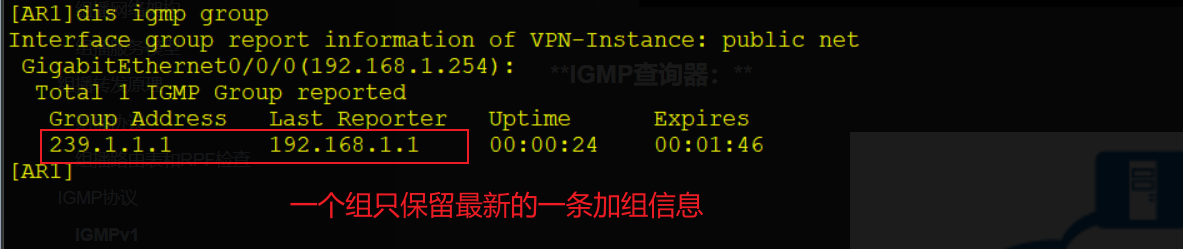
所以对于IGMP组表项而言,只记录一条最新收到的报告报文包含的地址,收到更新的报告报文,刷新该表项
IGMP查询器:
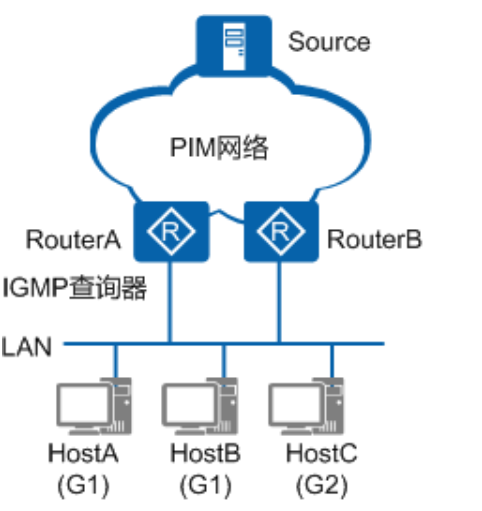
如图,当一个网段内有多个组播路由器时,由于它们都可以接收到主机发送的成员报告报文,因此只需要选取其中一台发送查询报文就可以了
这台发送查询报文的组播路由器就是IGMP查询器
IGMPv1没有查询器选举机制,以PIM协议的组播信息转发者(Assert Winner或DR)作为IGMPv1的查询器
IGMPv1配置命令:
multicast routing-enable # 开启组播路由功能
interface GigabitEthernet0/0/0 # 进入g0/0/0口
igmp enable # 使能IGMP
igmp version 1 # 设置版本为v1
其他命令:
dis igmp group # 查看IGMP组表项
注意:如果接口同时使能pim和IGMP,则需要先使能PIM,然后使能IGMP
IGMPv2
v2相比v1,增加了组成员离组机制和查询器选举机制
组成员离组机制:
IGMPv2的组成员离组机制通过新增的成员离开报文(Leave)和特定组查询报文(Group-Specific Query)实现chen
- 成员离开报文(Leave):成员离开组播组时主动向查询器发送的报文,用于宣告自己离开了某个组播组。
- 特定组查询报文(Group-Specific Query):查询器向共享网段内指定组播组发送的查询报文,用于查询该组播组是否存在成员。
组成员离组机制如下:
- 要离组的成员发送成员离开报文
- 查询器收到该离开报文,先检查成员地址是否IGMP组表项唯一记录的成员地址
- 如果不是,不予理会。如果是,查询器向网络中发送以该组为目的地址的特定组查询报文,并且启动一个计时器(计时器时间=特定组查询报文发送间隔x发送次数)
- 缺省时,特定组查询报文每隔1秒发送一次,共发送两次
- 如果网段内还存在其他成员,则这些成员立即发送报告报文,查询器收到后更新IGMP组表项。否则查询器删除该IGMP组表项条目并清理对应的PIM组播路由表项
查询器选举机制:
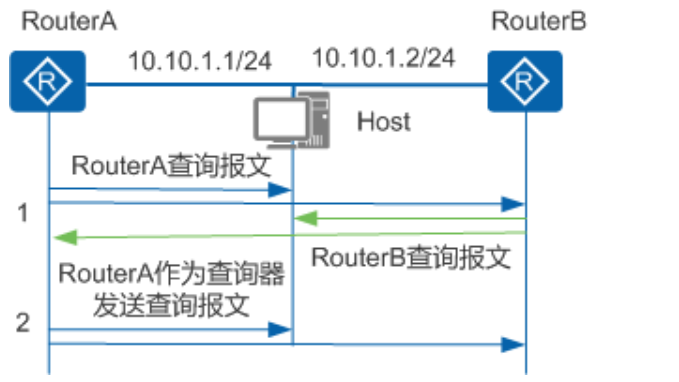
如图,假设本网段存在A和B两台组播路由器
- 最初,A和B都认为自己时查询器,都发送普遍组查询报文
- A和B收到对方发的查询报文后,将报文源IP和自己接口的IP比较,IP地址小的成为查询器
- 此后,查询器向网段中发送查询报文,非查询器不再发送普遍组查询报文(也不维护IGMP组表项)
非查询器会启动一个定时器,定时器超时前,如果收到了来自查询器的查询报文,则重置该定时器;否则,就认为原查询器失效,并发起新的查询器选举过程。
IGMPv2配置命令:
multicast routing-enable # 开启组播路由功能
interface GigabitEthernet0/0/0 # 进入g0/0/0口
igmp enable # 使IGMP
igmp version 2 # 设置版本为v2【可以不配置,缺省为v2】
其他命令:
dis igmp group # 查看IGMP组表项
IGMPv3
在不进行其他配置的情况下,v1和v2都只支持ASM模型,而v3支持SSM(指定源组播)模型
IGMPv3取消了成员离开报文和报告报文抑制机制,成员离组时,向查询器发送S和G记录的溢出位设置为1的IGMP组成员报告
查询器将接收到这个组成员报告,更新其IGMP组表项,将该成员从相应的组成员列表中删除。
IGMPv3同时兼容ASM和SSM,处理ASM组播时,除了离组机制,其他大体和v2一致,SSM通过成员报告报文和新增的特定源组查询报文实现
组播IP地址提前划好了范围
232.0.0.0-232.255.255.255用于SSM模型
224.0.1.0-231.255.255.255和233.0.0.0-238.255.255.255用户ASM模型只能处理ASM的设备收到SSM地址会丢弃该报文
SSM模型成员加组机制:
IGMPv3有两种成员关系报告报文,旧的报告报文同v2,用于ASM模型,新的报告报文用于SSM模型
新成员报告报文不仅包含主机想要加入的组播组,而且包含主机想要接收来自哪些组播源的数据。
IGMPv3中新成员关系报告报文中包含了两个字段:(include/exclude)字段。
- include字段指定要接收的源地址(如果指定源地址列表为空,该报文无效)
- exclude字段指定不需要的源地址 (如果不需要排除任何源地址,则可以在exclude字段中设置为全零)
IGMP查询器接收到组成员发送的改变组播组与源列表的对应关系的报告时,发送特定源组查询报文。
如果组成员希望接收其中任意一个源的组播数据,将反馈报告报文。IGMP查询器根据反馈的组成员报告更新该组对应的源列表。
IGMPv3配置命令:
multicast routing-enable # 开启组播路由功能
interface GigabitEthernet0/0/0 # 进入g0/0/0口
igmp enable # 使能IGMP
igmp version 3 # 设置版本为v3
其他命令:
dis igmp group # 查看IGMP组表项
IGMP SSM Mapping
IGMP SSM Mapping是使能IGMPv1和IGMPv2使用SSM模型的技术
通过在路由器上静态配置SSM地址的映射规则,将IGMPv1和IGMPv2报告报文中的(*, G)信息转化为对应的(G, INCLUDE, (S1, S2…))信息,以提供SSM组播服务。
配置了SSM Mapping规则后,当IGMP查询器收到来自成员主机的IGMPv1或IGMPv2报告报文时,首先检查该报文中所携带的组播组地址G,然后根据检查结果的不同分别进行处理。
- 如果组播地址G在ASM范围内,直接提供ASM服务
- 如果组播地址G在SSM范围内,提供SSM服务
IGMP SSM Mapping 配置命令:
interface GigabitEthernet0/0/0 # 进入接口
igmp enable
igmp version 3 # 使能ssm mapping的接口最好运行v3
igmp ssm-mapping enable # 使能ssm mapping
igmp # 进入IGMP视图
ssm-mapping 232.1.1.2 32 10.1.1.3 # 将232.1.1.2映射到10.1.1.3
ssm-mapping 232.1.1.2 32 10.1.1.4 # 将232.1.1.2映射到10.1.1.4
-- 一个组播IP可以映射多个组播源,通过配置多条ssm-mapping实现
-- 32不是掩码,是匹配前缀长度
dis igmp group ssm-mapping # 查看ssm-mapping映射表项
IGMP Proxy
为了减轻IGMP查询器的压力,可以在接入组播路由器和组成员主机之间的三层设备上配置IGMP Proxy功能
IGMP Proxy设备可以收集下游成员主机的IGMP报告/离开报文,将报告/离开报文汇聚后代理下游成员主机统一上送给接入设备;
IGMP Proxy设备也可以代理IGMP查询器向下游成员主机发送查询报文,维护组成员关系,基于组成员关系进行组播转发。
在接入路由器看来,使能IGMP Proxy的设备就是一台主机;在下游成员主机看来,就是IGMP查询器。
- 上游接口:指IGMP代理设备上配置IGMP Proxy功能的接口,该接口执行IGMP代理设备的主机行为,因此也称为主机接口(Host Interface)
- 下游接口:指IGMP代理设备上配置IGMP功能的接口,该接口执行IGMP代理设备的路由器行为,因此也称为路由器接口(Router Interface)
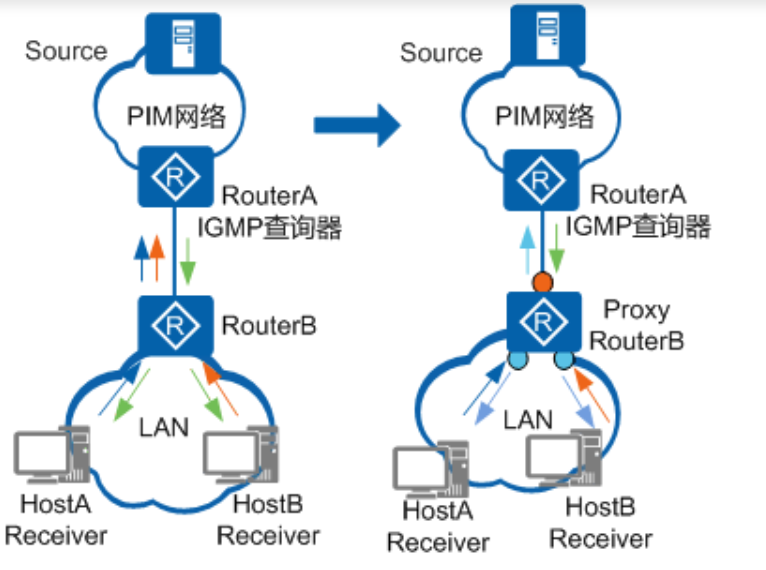
配置IGMP Proxy后,接入组播路由器和成员主机均无变化
- Proxy设备本身在查询器发来查询报文时响应报告保文
- 收到某组播组的报告报文后,会在组播转发表中查找该组播组
- 如果没有找到相应的组播组,IGMP代理设备会向接入设备发送针对该组播组的报告报文,并在组播转发表中添加该组播组
- 如果找到相应的组播组,IGMP代理设备就不需要向接入设备发送报告报文
- IGMP代理设备收到某组播组G的离开报文后,会向接收到该离开报文的接口发送一个特定组查询报文,检查该接口下是否还存在组播组G的其他成员
- 如果没有其他成员,在组播转发表中将该接口删除,然后判断组播组G是否还有其他接口。如果没有,IGMP代理设备再会向接入设备发送针对该组播组的离开报文
- 如果有其他接口,IGMP代理设备不向接入设备发送针对该组播组的离开报文
- 如果有其他成员,IGMP代理设备会继续向该接口转发组播数据。
IGMP Proxy配置命令:
int g0/0/0
igmp proxy # 使能IGMP Proxy功能
IGMP Proxy 在与用户网段直接相邻的组播路由器上配置即可
IGMP Snooping
由于组播MAC只封装在目的MAC中,而交换机MAC学习是根据源MAC,所以交换机不能根据MAC表项转发组播数据,只能广播发送
IGMP Snooping是一种IPv4二层组播协议,通过侦听组播协议报文维护组播报文,分析报文中携带的信息(报文类型、组播组地址、接收报文的接口等),建立和维护二层组播转发表,从而指导组播数据在数据链路层按需转发。
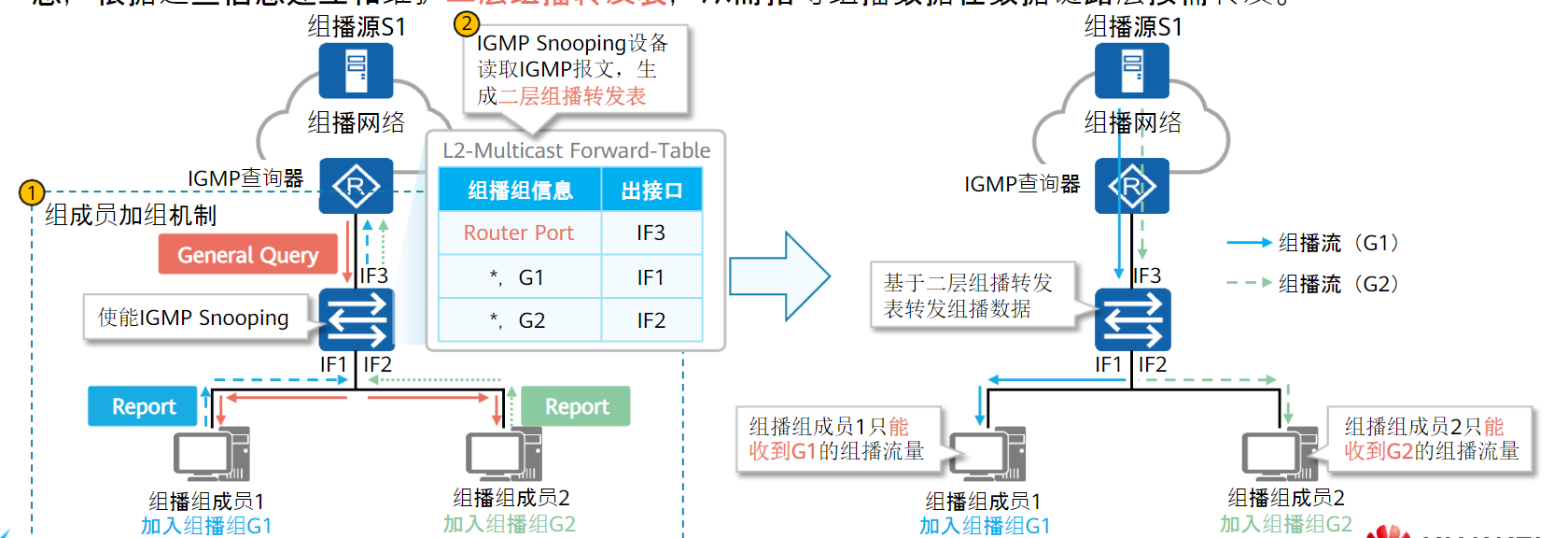
IGMP Snooping端口和转发表
二层组播转发表存在两类接口:
- 路由器端口:二层组播设备朝向三层设备的接口,从此接口接收组播报文
- 成员端口:二层组播设备朝向组播组成员的端口,从此接口发送组播报文
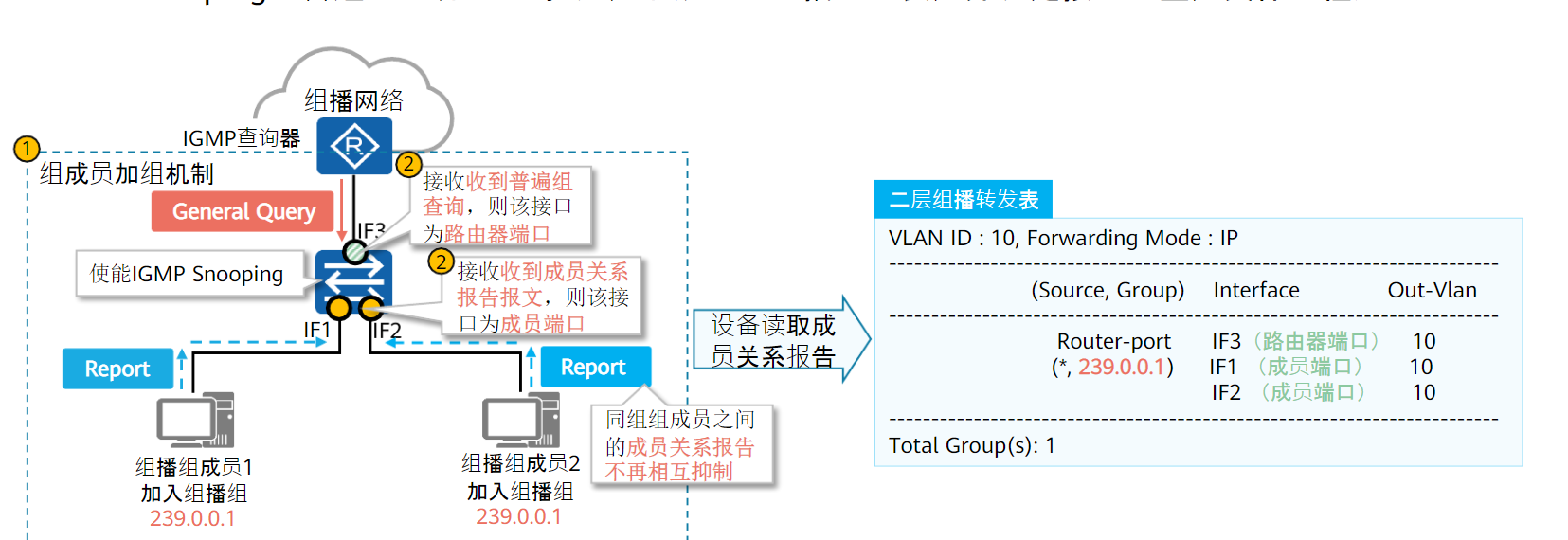
IGMP Snooping配置命令:
igmp-snooping enable # 全局使能IGMP-Snooping
vlan 10 # 进入vlan视图
igmp-snooping enable # vlan使能IGMP-Snooping
igmp-snooping version 2 # 指定igmp-snooping版本,与三层IGMP版本一致
必须使能全局IGMP Snooping功能,才能进行其他的IGMP Snooping配置
PIM协议
PIM协议是组播转发网络中负责建立组播分发树的三个协议之一,用于生成AS域内的组播分发树(MDT)
PIM协议报文直接采用IP封装,目的地址224.0.0.13,IP协议号103
组播分发树有两种:
- 以组播源为根,组播组成员为叶子的组播分发树称为SPT(Shortest Path Tree)
- 以RP(Rendezvous Point)为根,组播组成员为叶子的组播分发树称为RPT(RP Tree)
PIM协议按工作原理分为PIM-DM和PIM-SM两个模式
邻居发现:
PIM路由器上每个使能了PIM协议的接口都会对外发送Hello报文。目的地址224.0.0.13,源地址为接口的IP地址、TTL数值为1。
Hello报文的作用:发现PIM邻居、协调各项PIM协议报文参数、维持邻居关系。
同一网段中的PIM路由器都必须接收目的地址为224.0.0.13的组播报文。这样直接相连的PIM路由器之间通过交互Hello报文以后,就可以彼此知道自己的邻居信息,建立邻居关系。
只有邻居关系建立成功后,PIM路由器才能接收其他PIM协议报文,从而创建组播路由表项。
PIM路由器之间周期性地发送Hello报文(默认30s),如果在超时时间内收不到邻居发来的Hello报文,则删除邻居关系
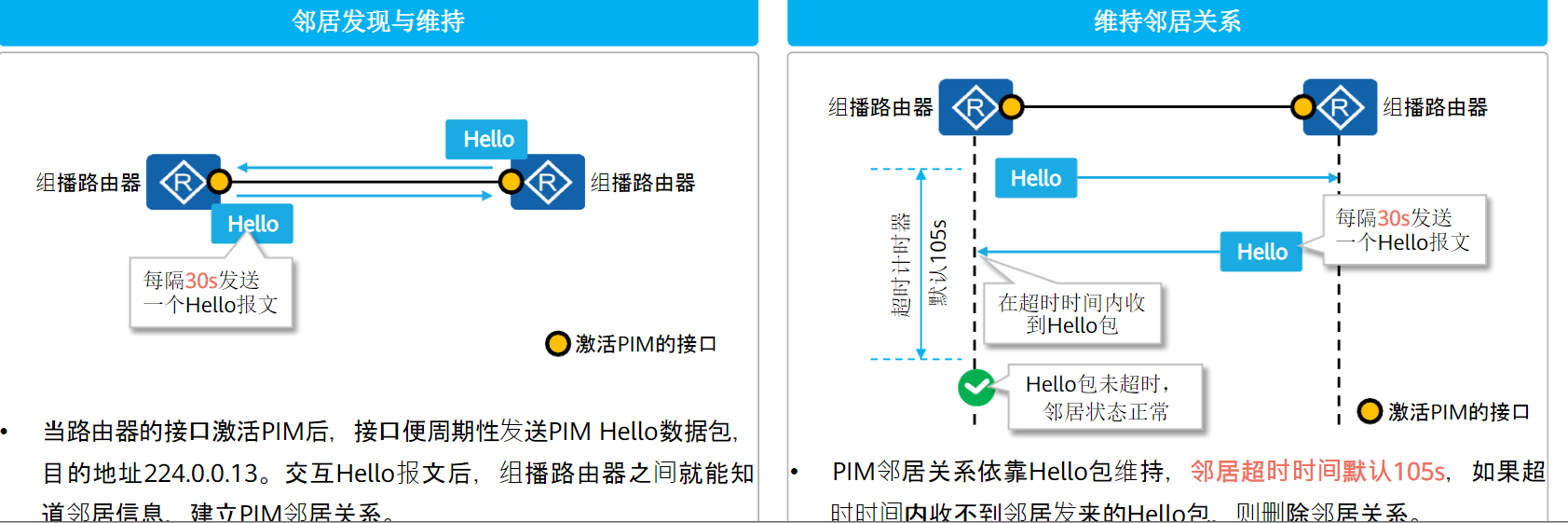
DR选举:
在组播源或组成员所在的网段,通常同时连接着多台PIM路由器。为了避免报文重复问题,需要对组播源或组成员所在网段的PIM路由器进行DR选举
PIM协议DR选举在交互Hello报文时实现,Hello中携带DR优先级和该网段接口地址。PIM路由器将自身条件与对方报文中携带的信息进行比较,选举出DR来负责源端或组成员端组播报文的收发。
选举规则:
- DR优先级较高者获胜(网段中所有PIM路由器都支持DR优先级)。
- 如果DR优先级相同或者网段存在不支持在Hello报文中携带DR优先级的路由器,则IP地址较大者获胜。
DR出现故障,将导致PIM邻居关系超时,其他PIM邻居之间会触发新一轮的DR竞选
网段内PIM组播报文均由DR发送
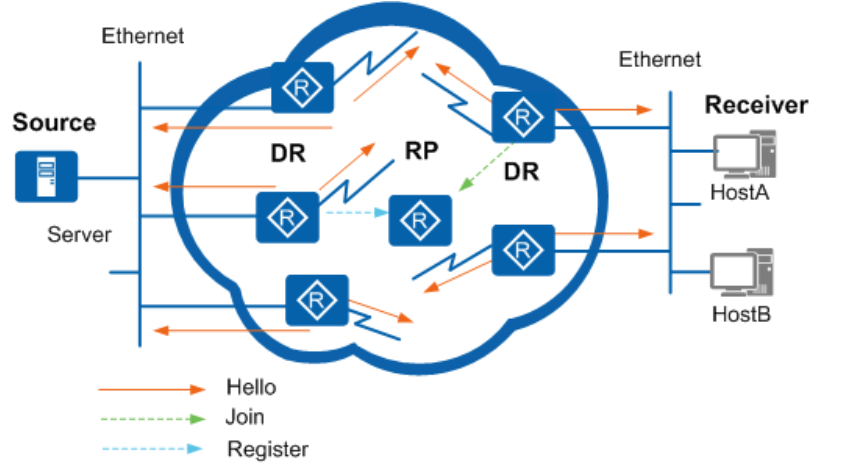
其中,由于IGMPv1没有查询器选举机制,所以以PIM选出的DR为查询器
PIM-DM (PIM密集模式)
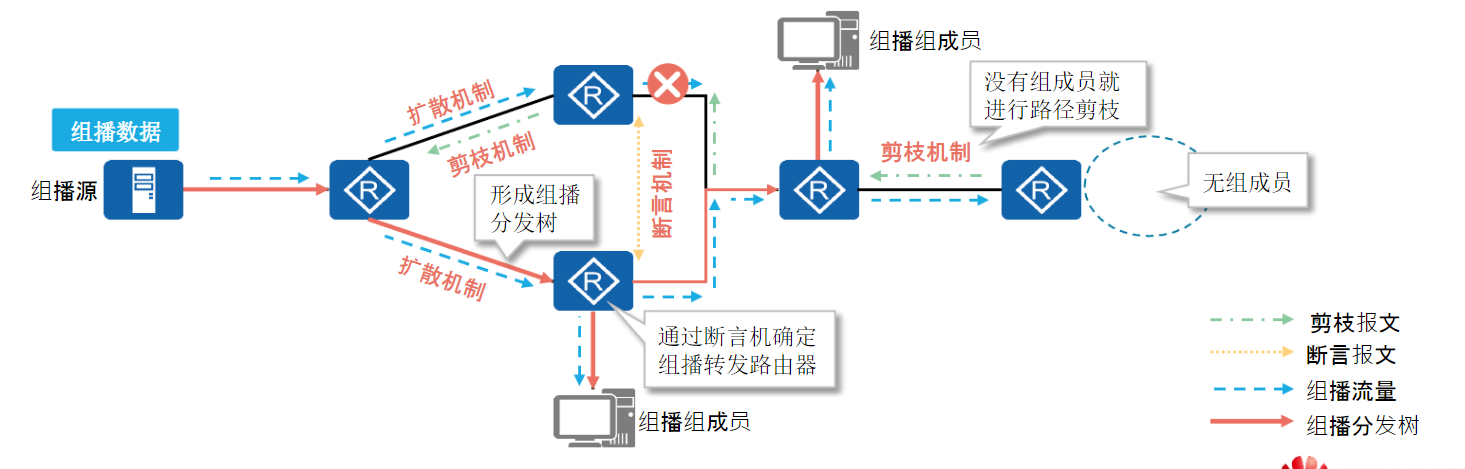
PIM-DM协议主要用在组成员密集的网络中,通过把数据从源推下去,有人不要再剪掉的方式组成组播分发树。
由于是以源为根,所以形成的组播分发树是SPT
PIM-DM只支持ASM模型
PIM-DM的关键工作机制包括邻居发现、扩散、剪枝、嫁接、断言和状态刷新。

组播分发树建立过程:
邻居关系建立后,如果有路由器收到了组播数据,并且收到报文的接口并没有PIM邻居。则认为自己是组播源第一跳路由器,向整个组播网络发送该数据
- 扩散机制:收到组播数据的路由器会将组播数据包向所有PIM邻居泛洪,同时产生组播路由表项
- 剪枝机制:收到组播数据的路由器发现自己下联接口没有该组成员,则向上发送剪枝报文,告知上联路由器不需要继续发送该组的报文
- 断言机制:同时从两个邻居收到相同的组播报文,则需要选举出一个转发路由器,避免重复报文
扩散机制:
组播源发送的报文会在全网扩散,当PIM路由器接收到组播报文,根据单播路由表进行RPF检查通过后,就会在该路由器上创建(S,G)表项,然后将后续组播报文将从各个下游接口转发出去。
PIM-DM形成的(S,G)表项老化时间默认210s,如果老化前还没有收到新的组播报文,则删除(S,G)表项
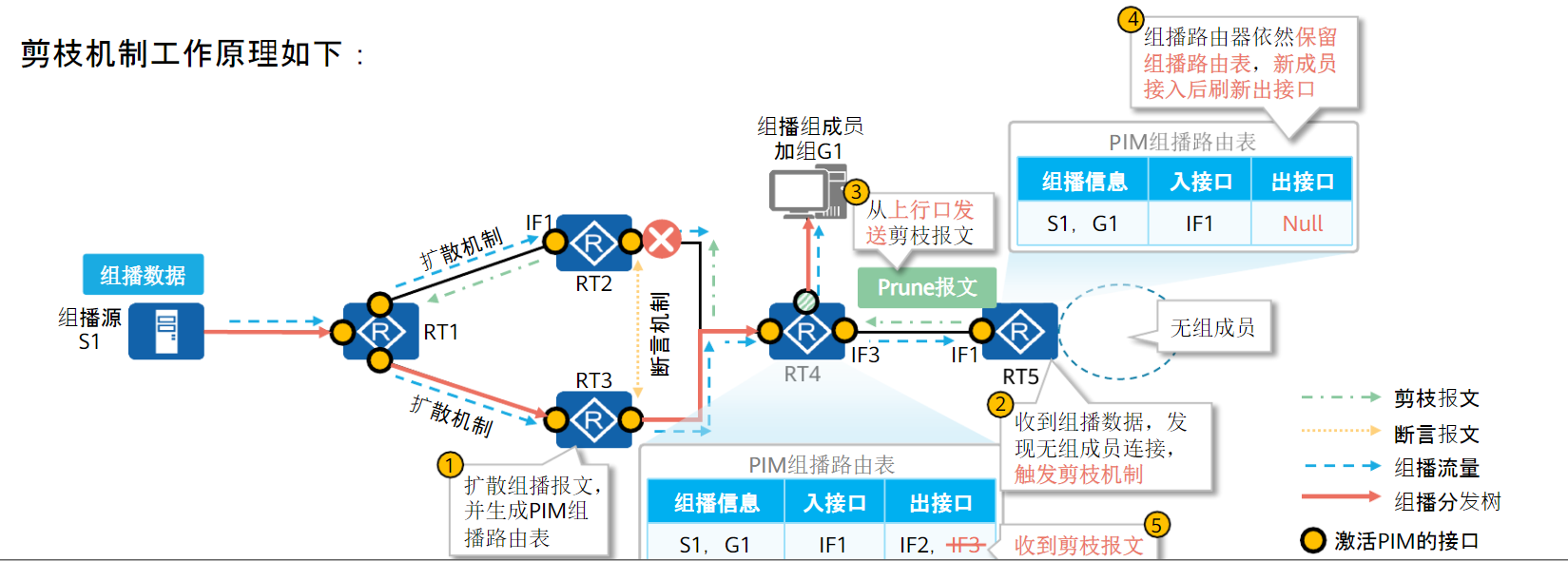
剪枝机制:
当PIM路由器接收到组播报文后,RPF检查通过,但是下游网段没有组播报文需求。
此时PIM路由器会向上游发送剪枝报文,通知上游路由器禁止向相应的下游接口转发,将其从(S,G)表项的下游接口列表中删除。
剪枝操作由叶子路由器发起,逐跳向上,最终组播转发路径上只存在与组成员相连的分支。
路由器为被裁剪的下游接口启动一个剪枝定时器,定时器超时后接口恢复转发。
断言机制:
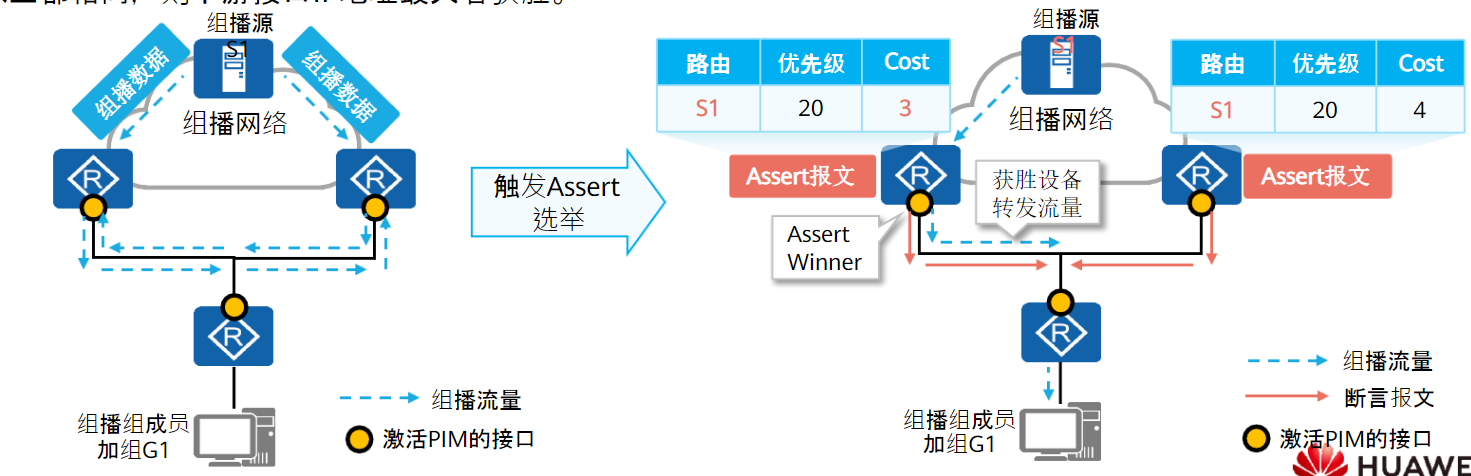
PIM路由器在接收到邻居路由器发送的相同组播报文后,会以组播的方式向本网段的所有PIM路由器发送Assert报文,目的地址为224.0.0.13。
其它PIM路由器在接收到Assert报文后,将自身参数与对方报文中携带的参数做比较,进行Assert竞选。
竞选规则如下:
- 单播路由协议优先级较高者获胜。
- 如果优先级相同,则到组播源的开销较小者获胜。
- 如果以上都相同,则下游接口IP地址最大者获胜。
根据竞选结果,获胜一方的下游接口称为Assert Winner,将负责后续对该网段组播报文的转发。
落败一方的下游接口称为Assert Loser,后续不会对该网段转发组播报文,PIM路由器也会将其从(S,G)表项下游接口列表中删除。
状态刷新机制:
为了避免被剪枝的接口因为剪枝定时器超时回复转发,组播源第一跳路由器会周期性的发送State Refresh报文
收到State Refresh报文的PIM路由器会刷新定时器状态,使被剪枝的下游接口如果一直没有成员加入,就一直处于抑制状态
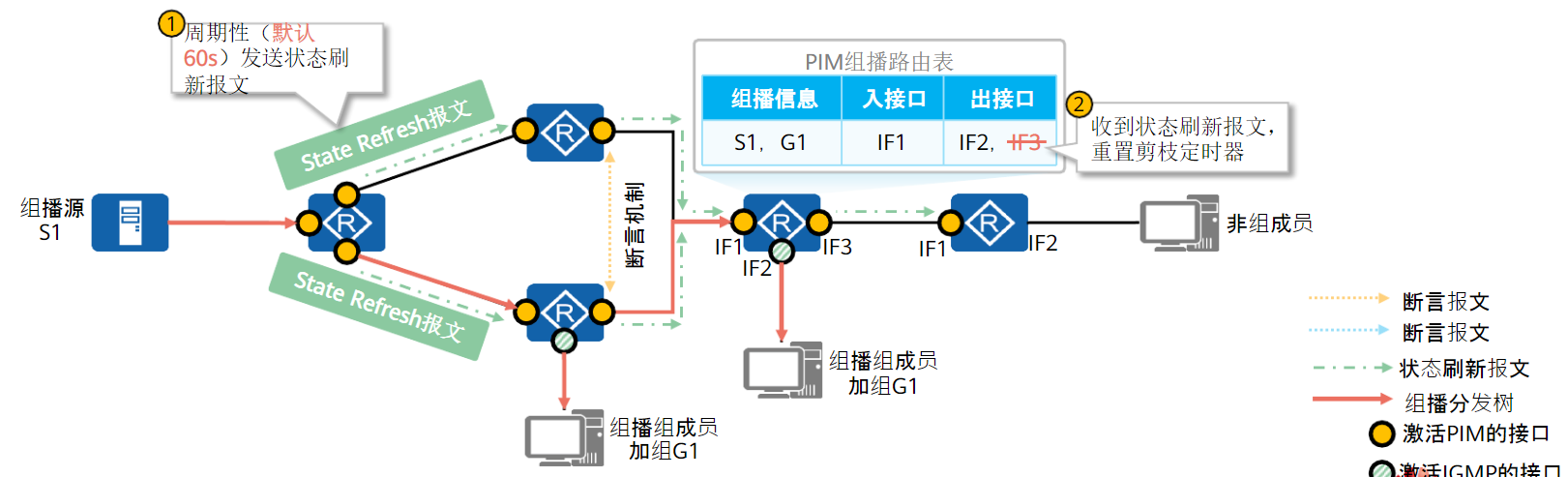
嫁接机制:
如果被剪枝接口下有成员加组,由于状态刷新机制的存在,被剪枝接口下游不可能等到剪枝定时器超时,所以就需要通过嫁接机制向上游设备宣告自己的存在
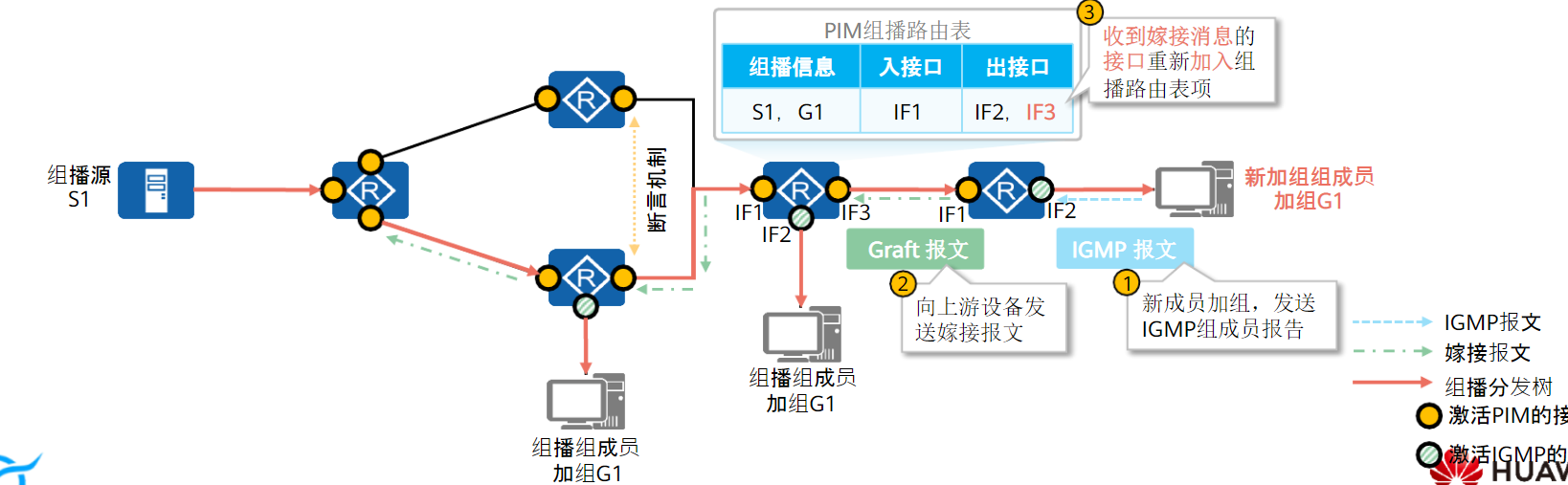
新成员加组后,叶子路由器会向上游转发Graft报文,请求上游接口恢复出接口转发
同剪枝一样,嫁接也会一直传递,直到收到的接口不在抑制状态
PIM-DM配置命令:
multicast routing-enable # 使能组播功能
interface GigabitEthernet0/0/2
pim dm # 使能pim dm
PIM-SM (PIM稀疏模式)【ASM模型】
PIM-SM使用“拉(Pull)模式”转发组播报文,一般应用于组播组成员规模相对较大、相对稀疏的网络。
PIM-DM模型只能用于ASM模型,而PIM-SM可以应用在ASM和SSM中,所以需要分别讨论
对于ASM而言,实现方法是:
- 在网络中维护一个路由器作为汇聚点,称为RP。这个汇聚点可以随时为组成员和组播源提供服务,网络中所有PIM路由器都知道汇聚点的位置
- 当出现组成员加组时,最后一跳路由器向RP发送Join报文,逐跳建立(*,G)表项,生成一颗以RP为根的RPT树
- 当出现新组播源时,第一跳路由器向RP发送封装在单播中的Register报文,在RP上创建(S,G)表项,注册源信息
组播数据从源到RP,再从RP到组成员,形成一个完整的组播网络
PIM-SM【ASM模型报文类型】:

RP发现:
PIM网络中的路由器有两种方式可以发现RP
静态配置RP:通过手工静态的方式告知所有PIM路由器RP的位置
# PIM-SM的配置可以简单的分为两步:使能PIM-SM,配置RP multicast routing-enable # 使能组播功能 interface GigabitEthernet0/0/2 pim sm # 使能sm pim # 进入pin视图 static-rp 10.1.5.5 # 指定rp地址PIM网络所有路由器都需要配置
动态选举RP:通过选举机制在多个C-RP(候选RP)之间选举RP
在动态选举RP的场景中,PIM路由器的角色分为三类:
- C-BSR:候选BSR,用来收集C-RP的信息,并向整个组播网络发送
- C-RP:候选RP
- 普通PIM成员:除C-BSR和C-RP以外的所有PIM路由器
C-BSR和C-RP都需要管理员手动指定,RP选举过程如下:
- 管理员手动指定一个或者多个C-BSR和C-RP
- 开始时,每个C-BSR都认为自己时BSR,均向全网发送Bootstrap报文(自举),每台PIM均可收到,并进行比较
- BSR优先级较高者获胜(值越大越优)
- 优先级相同,IP地址较大的获胜
- BSR选举后,C-RP向BSR发送Advertisement报文(候选RP通告),报文中携带C-RP地址、服务的组范围和C-RP优先级。
- BSR将收到的信息汇总为RP-Set,通过Bootstarp报文发送给所有PIM路由器
- PIM路由器收到后使用相同的规则进行比较,选举出RP
- 与用户加入组地址匹配的C-RP掩码最长者获胜。
- 如果相同,C-RP优先级较高者获胜(优先级数值越小优先级越高)
- 如果相同,则执行Hash函数,计算结果较大者获胜
- 如果相同,则C-RP的IP地址较大者获胜
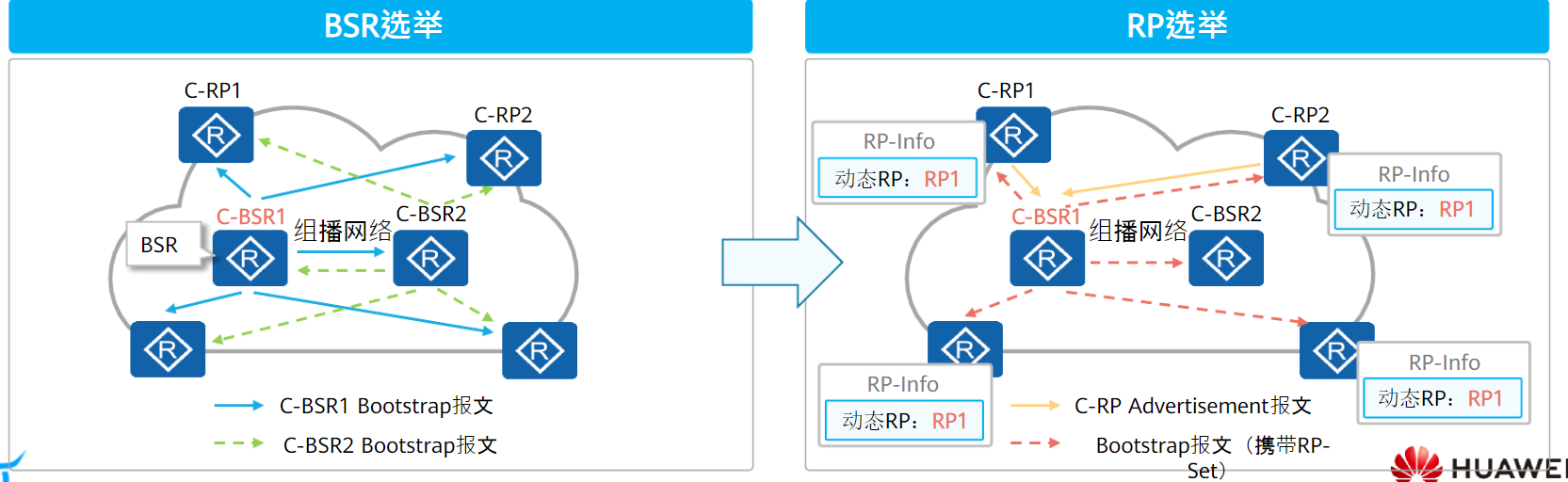
RP选举成功后,PIM-SM(ASM)开始构建组播分发树
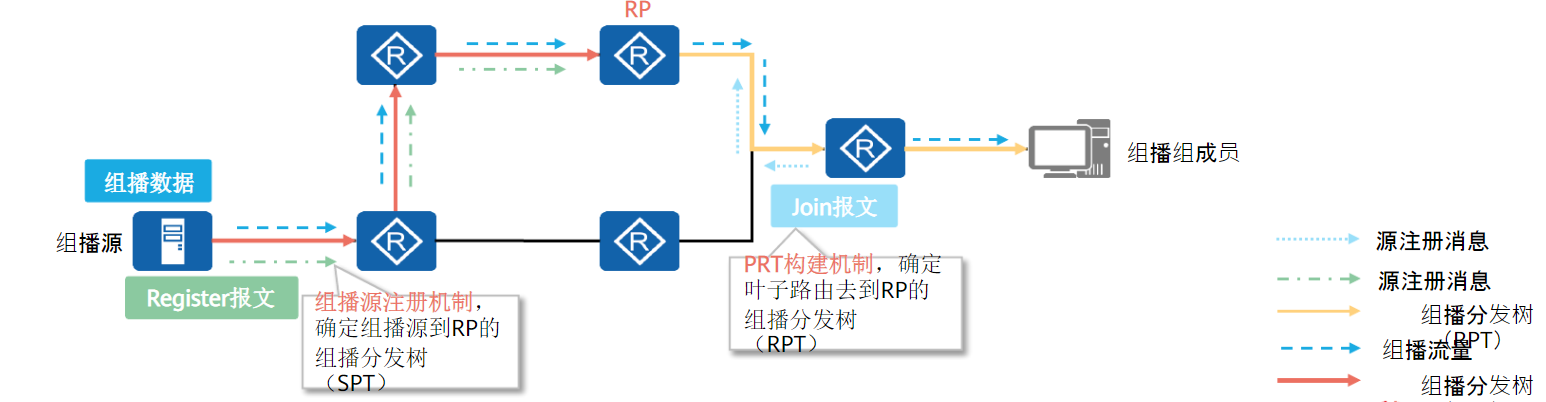
以RP为根到组成员的RPT树构建(RPT构建机制):
当网络中出现组成员(用户主机通过IGMP加入某组播组G)时,组成员端DR向RP发送Join报文,在通向RP的路径上逐跳创建(*,G)表项,生成一棵以RP为根的RPT。
在RPT构建过程中,PIM路由器在发送Join报文时,会进行RPF检查:查找到达RP的单播路由,单播路由的出接口为上游接口,下一跳为RPF邻居。Join报文从组成员端DR开始逐跳发送,直至到RP。
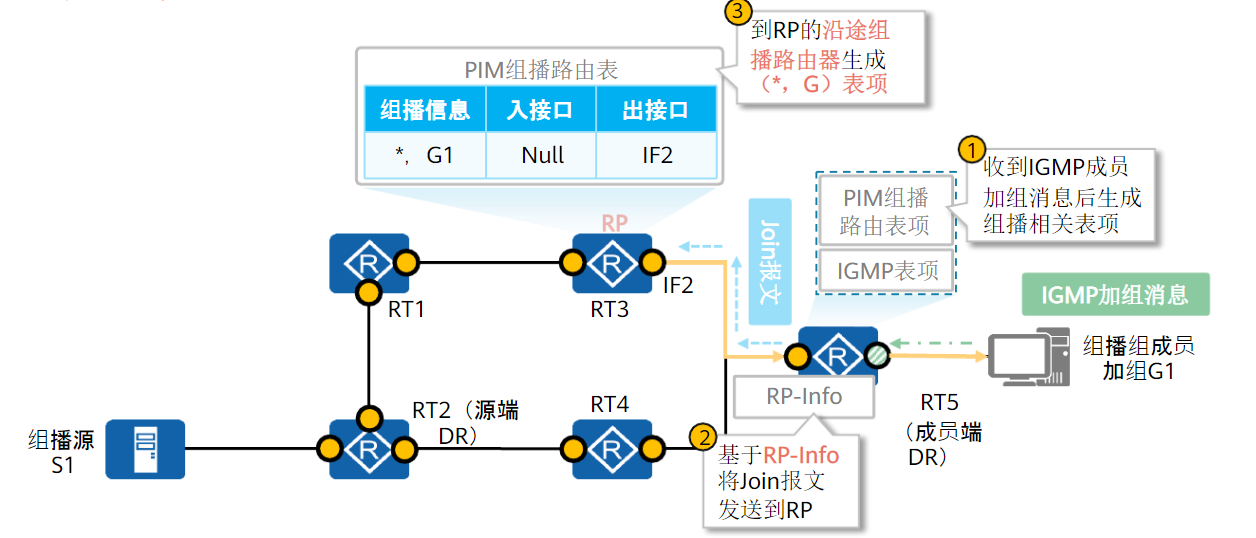
以组播源为根到RP的SPT树构建(组播源注册机制):
由于远端组播源只有RP的地址,并没有到达RP的路由表项,所以组播源注册报文Register封装在单播中发送给RP
RP收到注册报文后,会进行两个操作:
- 单播发送注册停止报文
Register-Stop-Ack,告知组播源RP已经收到注册报文,无需继续发送注册报文 - 通过RPF检查机制得到的上游接口向组播源发送组播
join报文,沿途逐跳构建(S,G)表项和SPT树
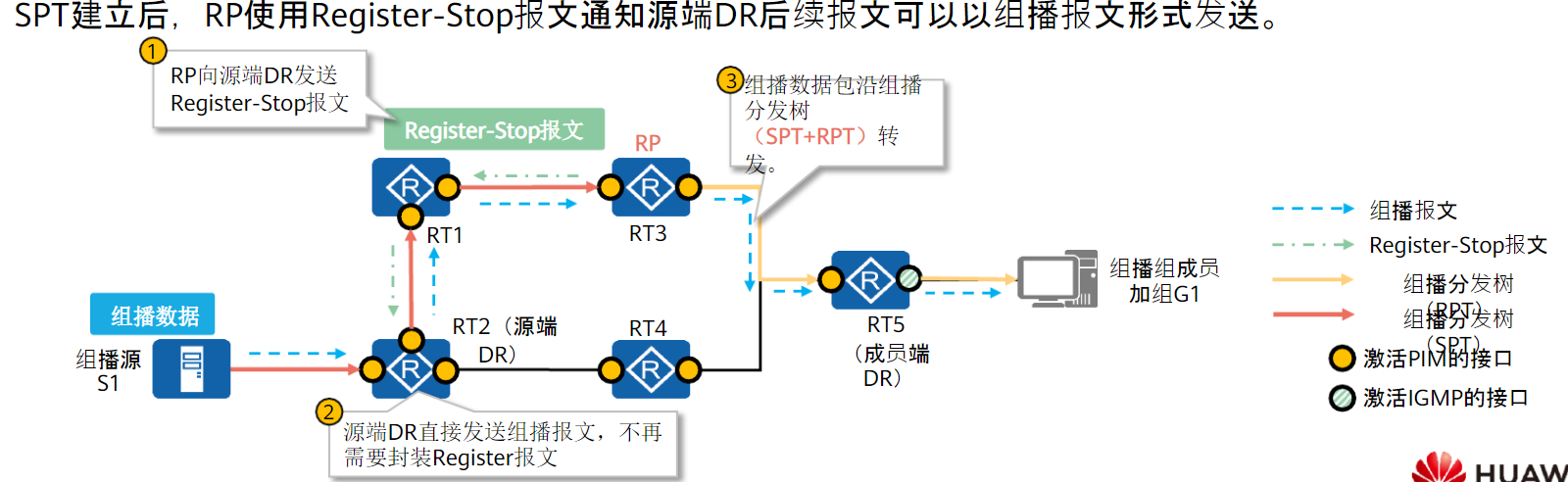
构建成功后,组播报文沿组播源到RP,再由RP向下游组播到组成员
组播源离组时,向RP发送剪枝Prune报文告知RP,RP在接收到Prune报文后,将在(S,G)树和SPT树中删除相应的条目,并停止向该成员组播数据包。
SPT切换机制:
由于PIM-SM(ASM)基于RP维护两段组播分发树,所以会产生次优路径问题
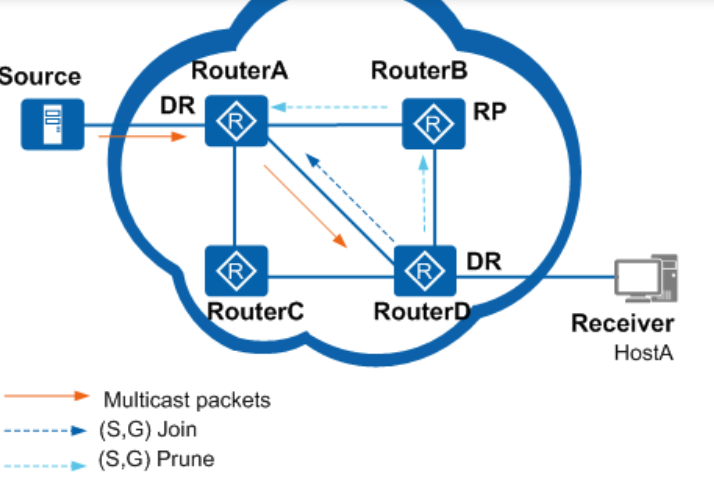
如图,从Router-D到Router-A显然比经过RP中转更优,此时就需要SPT路径切换机制,将组播转发切换到最优路径
切换原理:
- 成员端DR收到组播数据后,根据RFC检查得到的上游接口逐跳向组播源周期性发送
Join报文(60s),建立源端直接到组成员的SPT - 源端直接到组成员的SPT建立后,成员端逐跳向RP周期性发送剪枝(Prune)报文(60s),删除(S,G)表项中相应的下游接口。剪枝结束后,RP不再沿RPT转发组播报文到组成员端。
此时由于路径是RPF检查的结果,所以一定是最优的,如果RP处于最优路径上,则仍然可以看做组播数据经过了RP
如果在210s内没有组播流量,则源端直接到组成员的SPT消失,成员端DR恢复到以RP为根的RPT树
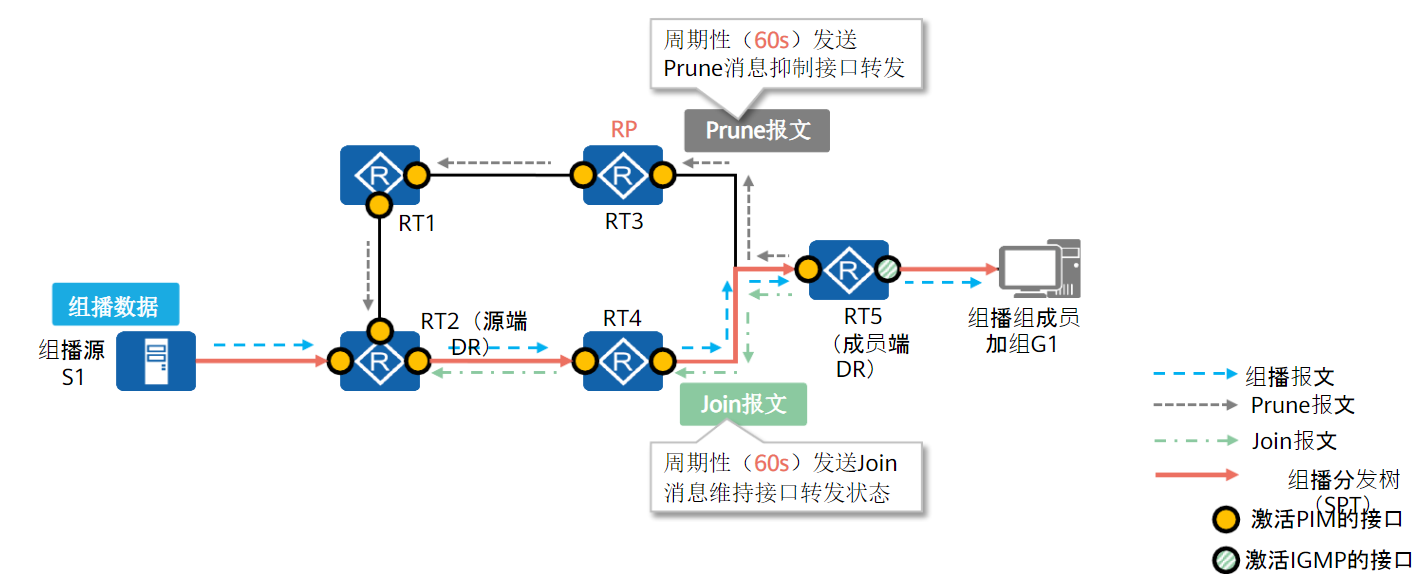
PIM协议的最终目的就是建立从源到成员的组播分发树,至于RP只是一个统筹两端的工具。
在组播分发树的构建中RP至关重要,而构建成功后就不那么重要了
PIM-SM(ASM)动态RP选举配置:
# PIM-SM的配置可以简单的分为两步:使能PIM-SM,配置RP
# 使能组播功能所以设备都需要配置
multicast routing-enable # 使能组播功能
interface GigabitEthernet0/0/2
pim sm # 使能sm
# 进入C-BSR设备配置
pim # 进入pim视图
c-bsr GigabitEthernet0/0/1 # 指定c-bsr为g0/0/1接口
# 进入C-RP设备配置
acl number 2000
rule 5 permit source 239.1.0.0 0.0.255.255
pim
# 指定c-rp为g0/0/0接口,并设置rp的服务范围是acl 2000
c-rp GigabitEthernet 0/0/0 group-policy 2000
-- rp服务范围可选,不设置默认为全部
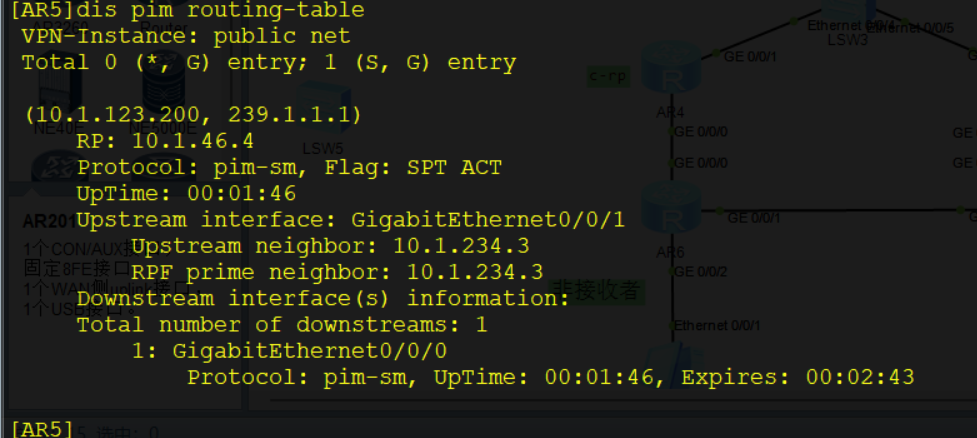
查看rp和bsr信息:
dis pim rp-info # 查看所有rp信息
dis pim bsr-info # 查看bsr信息
BSR和RP可以是同一设备甚至是同一接口
PIM-SM(PIM稀疏模式)【SSM模型】
SSM模型最大的特点是直接指定源组播,体现在PIM-SM(SSM)中就是:
SSM模型中,同一个源上不同的组播应用必须使用不同的SSM组播地址区分。同时由于组播源不同,不同组播源之间可以使用相同的SSM组播地址
即:SSM对组播源的要求不在全网唯一,而是在各自的组播源中唯一
SSM模型构建组播分发树的前提是成员端DR必须预先知道组播源地址和组播源中有那些组播组
基于这一前提,PIM-SM(SSM)可以直接从成员端DR向指定源反向周期性发送Join报文(60s),建立并维护组播分发树
所以PIM-SM(SSM)无需选举RP,无需构建RPT,无需注册组播源
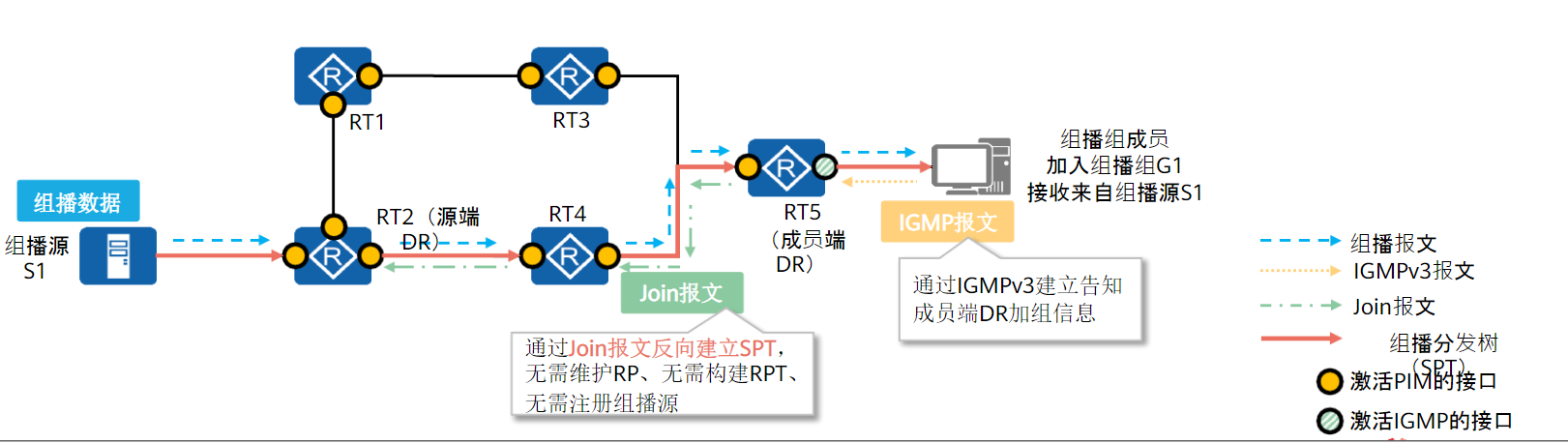
PIM-SM(SSM)形成的组播分发树会一直存在,不会因为没有组播流量而消息,除非组播源或者组成员断开连接
PIM-SM(SSM)配置命令:
SSM只需要组播网络使能sm即可,注意成员端使用IGMPv3加组
multicast routing-enable # 使能组播功能
interface GigabitEthernet0/0/2
pim sm # 使能sm
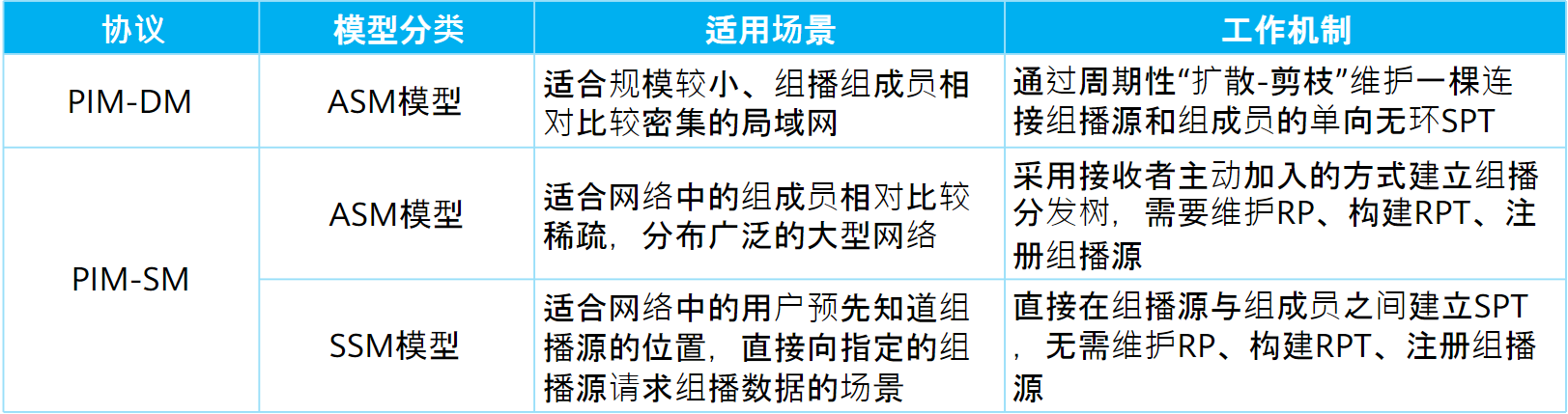
MPLS 多协议标签交换
MPLS 概述
MPLS: 多协议标签交换,是位于网络二层和三层之间的协议,被称为”2.5”层协议
MPLS通过交换标签的方式转发数据,本质上是一种隧道技术。同其他隧道技术一样,如果想要建立MPLS转发网络前提是已经建立了IP网络(IPv4\IPv6)
MPLS产生的历史原因此处不做记录
MPLS网络结构与术语解释
网络结构如图:
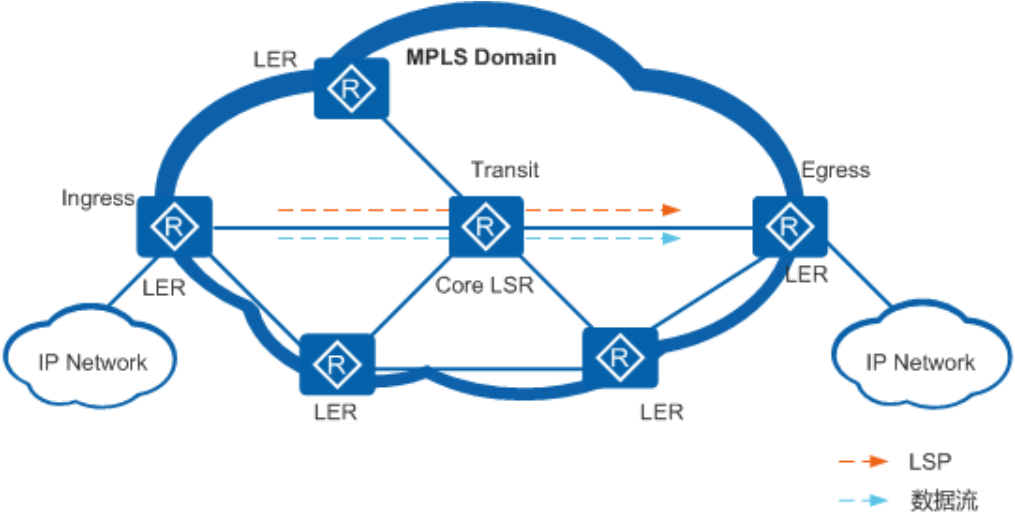
IP报文进入网络时,再入口(Ingress)LER位置打上标签,经过一系列标签转发后,从出口(Egress)剥离标签弹出
术语解释:
MPLS域:一系列连续的使能了MPLS的网络设备构成一个MPLS Domain(域)
LSR:使能了MPLS的设备称为LSR,其中位于MPLS域边缘、连接其他网络的称为边沿路由器LER
根据对数据处理方式的不同,LSR又分为三种:
- 入节点LSR(Ingress LSR):IP报文进入MPLS网络,开始标签转发的LSR
- 中间节点LSR(Transit LSR):在MPLS域中进行标签转发的LSR
- 出节点LSR(Egress LSR):报文离开MPLS网络,继续IP转发的LSR
FEC(转发等价类):划分标签的依据,是一组据有共同特性的数据流集合,相同FEC在转发过程中被网络节点以相同的策略处理
MPLS网络中,FEC可以根据多种方式进行划分,但最常用的是将一条路由作为一个FEC
数据属于哪个FEC,由数据进入MPLS时的Ingress LSR决定
同属一个FEC的数据,将通过相同的LSP转发,MPLS标签与FEC对应
LSP(标签交换路径):标签报文穿越MPLS网络所走的路径
LSP是一条单向的标签转发路径
MPLS标签
MPLS网络依靠标签进行转发,标签是一个短而定长(32bit),只具有本地意义的标识符
一个报文可以携带多个标签,这些标签统称为一个标签栈
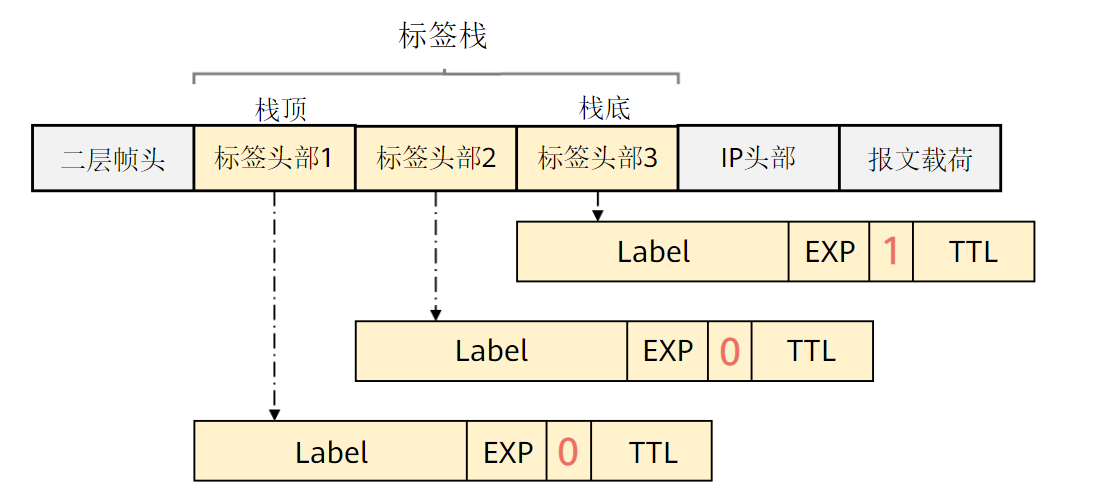
标签栈中靠近二层的称为栈顶标签,靠近三层的称为栈底标签
每个标签中都有四个字段:
- Label:20bit,标签值
- EXP:3bit,用于QOS
- S: 1bit,栈底标识,S置位为1时表示当前标签为栈底标签
- TTL:8bit,和IP报文中的TTL作用一致
MPLS中的TTL和IP中的作用一致
MPLS对TTL的处理包括MPLS对TTL的处理模式和ICMP响应报文这两个方面。
处理模式包括:Uniform和Pipe。缺省为Uniform
- Uniform:IP报文进入MPLS网络时,在Ingress LSR,IP TTL减一映射到MPLS TTL,此后报文在MPLS网络中按标准TTL处理方式处理。在Egress LSR中将MPLS TTL减一映射到IP TTL
- Pipe:MPLS TTL和IP TTL不做映射,分别计算,即IP分组经过MPLS网络时,无论经过多少跳,IP TTL只在入节点和出节点分别减1。
对于ICMP,LSR将TTL超时消息回应给报文发送者的方式有两种
- LSR上存在到达报文发送者的路由,通过IP路由,直接向发送者回应TTL超时消息。
- LSR上不存在到达报文发送者的路由,ICMP响应报文将按照LSP继续传送,到达LSP出节点后,由Egress节点将该消息返回给发送者。
通常情况下,收到的MPLS报文只带一层标签时,LSR采用第一种方式回应TTL超时消息;收到的MPLS报文包含多层标签时,LSR采用第二种方式回应TTL超时消息。
标签空间:
标签空间就是只标签值的取值范围,划分如下:
- 0-15:特殊标签,MPLS自留。常见的有IPv4显式空标签0和IPv4隐式空标签3
- 16-1023:静态LSP和静态CR-LSP(流量工程)使用的标签空间
- 1024以上:LDP、RSVP-TE、MPLS-BGP等动态标签分配协议使用的标签空间
显示空标签和隐式空标签:
数据从MPLS网络转发,如果在出节点弹出标签进入IP转发,就要先查一次MPLS转发表,再查一次IP转发表,这样对出节点压力较大
通过在出节点上一跳设备(次末跳)定义特殊标签3,并规定遇到标签3弹出标签转发,从而使报文以IP报文的身份进入出节点,这样就直接可以查IP表转发而无需查标签表,从而达到节约出节点资源的目的
这个机制称为:次末跳弹出
由于标签只具有本地意义,所以无法通过抓包看到标签3,所以标签3称为隐式空标签
动态标签分发协议都有定义次末跳弹出机制
而在QOS的场景中,出节点还需要根据标签携带的EXP值进行服务质量处理,所以需要保留标签
显示空标签0就是为此而存在,最后一跳收到显示空白标签时,根据EXP值进行QOS,并且直接查IP转发
MPLS标签的处理动作:
MPLS对标签有三种处理动作,压入、交换、弹出,作用就是字面意思
一般来说,Ingress LSR是压入,Transit LSR是交换,Egress是弹出,但多标签例外
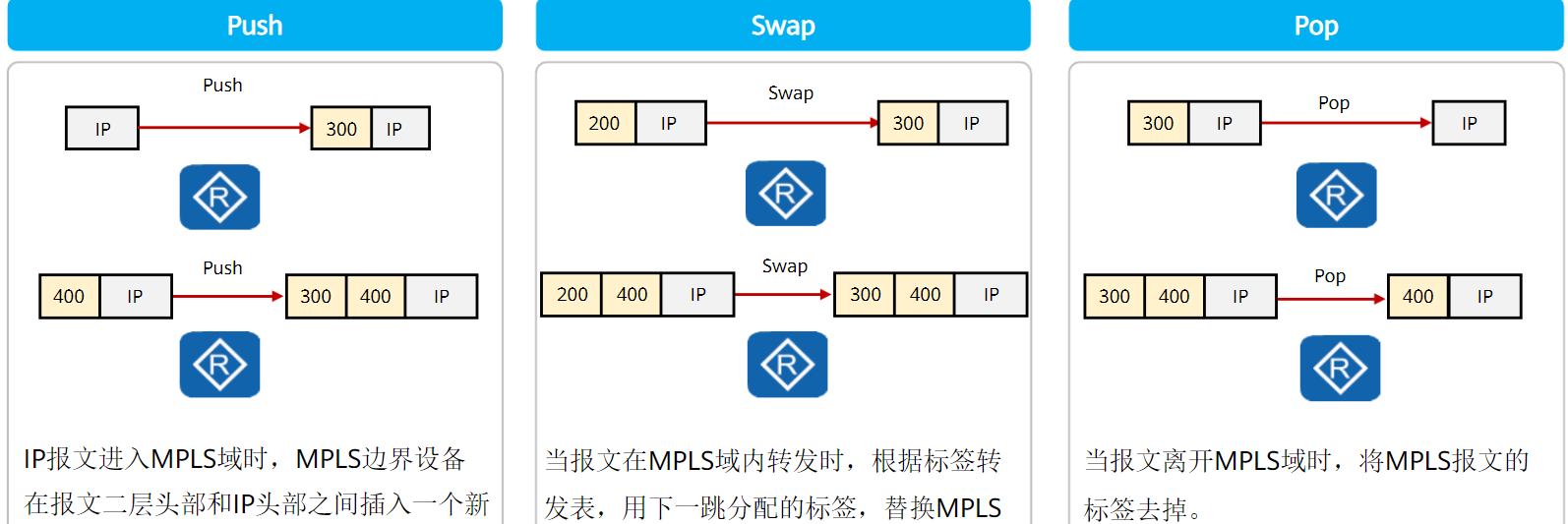
通过查询nhlfe表,可以得知标签在该节点的转发动作
diagnose # 进入诊断模式(模拟器中只有router有此命令)
display mpls nhlfe # 查看nhlfe表

其中TUNNEL ID指隧道ID,OPER指标签转发动作
静态LSP的建立
建立标签转发路径LSP有两种方式,静态手工配置和动态标签分发协议自主建立
一般情况下,MPLS网络中都使用LDP(Label Distribution Protocol)建立LSP。但LDP是通过路由信息来建立LSP,出现问题可能导致MPLS流量的丢失。
因此,对于某些关键数据或重要业务,通过配置静态LSP来确定传输路径。
静态手工配置如下:
所有LSR使能MPLS功能
mpls lsr-id 10.1.1.1 # 配置本设备mpls lsr-id为10.1.1.1 mpls # 全局使能mpls interface GigabitEthernet0/0/0 mpls # 接口使能mplsmpls的lsr-id在mpls网络中必须唯一,一般使用环回口地址作为lsr-id。
根据LSR角色配置静态LSP
# Ingress LSR static-lsp ingress 1 destination 10.1.3.3 32 nexthop 10.1.12.2 out-label 100 -- 配置名称为1的入节点静态lsp,目的地址10.1.3.3/32,下一跳10.1.12.2,出标签100 # Transit LSR static-lsp transit 1 incoming-interface GigabitEthernet0/0/0 in-label 100 nexthop 10.1.23.3 out-label 200 -- 配置名称为1的中间节点静态lsp,报文入接口g0/0/0,入标签100,下一跳10.1.23.3,出标签200 # Egress LSR static-lsp egress 1 incoming-interface GigabitEthernet0/0/0 in-label 200 -- 配置名称为1的出节点静态lsp,入接口g0/0/0,入标签200只配置出接口也可以,但最好还是加上下一跳,只配置出接口的静态LSP好像有点问题
查看静态LSP状态:
display mpls static-lsp

状态为UP时表示LSP正常建立
MPLS转发原理
MPLS体系结构:
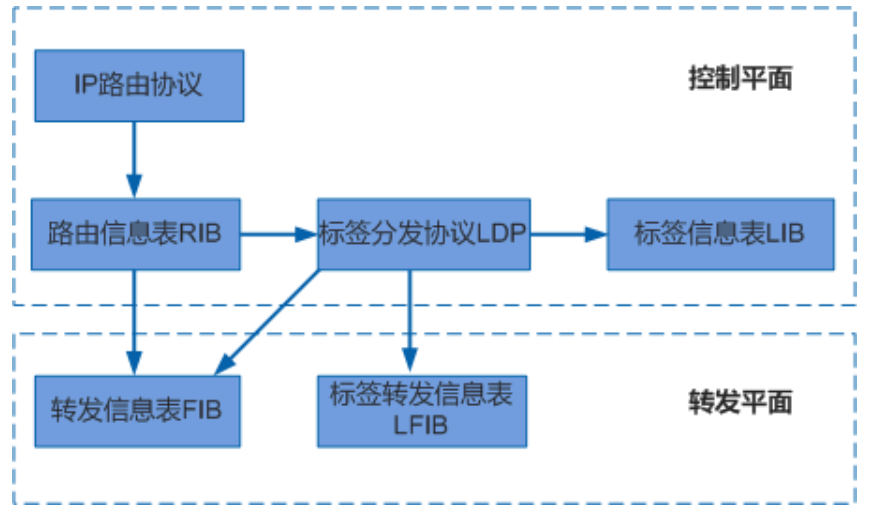
网络设备转发流量都可以分为控制平面和转发平面两个部分
控制平面负责路由优选、标签分发等任务,转发平面负责根据控制平面下发的转发表进行具体的转发处理
比如IP网络中,控制平面根据各类路由协议优选出IP路由表,然后下发给转发平面转发表FIB,数据到达设备,实际是直接通过转发表进行转发
dis fib # 查看路由转发表
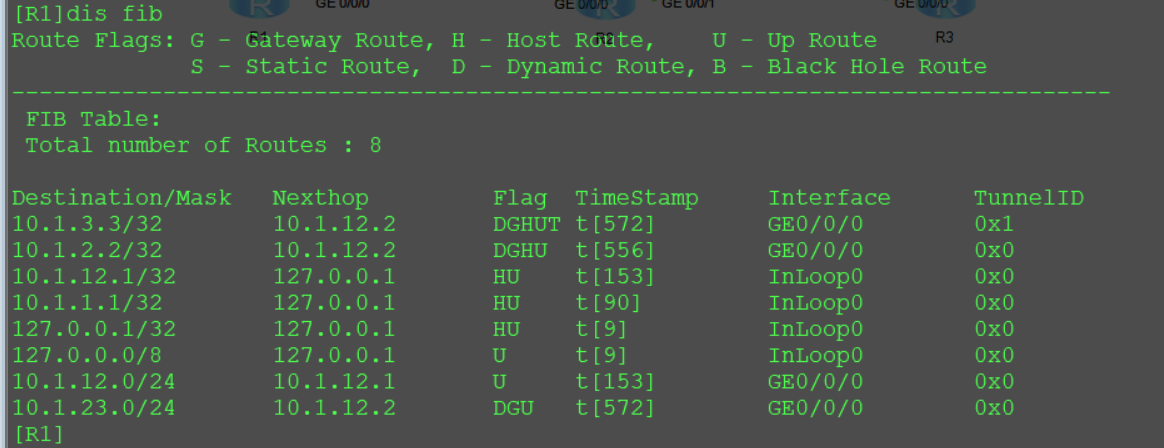
在之前的技术中,转控两个平面的特点体现并不是很明显,而想要研究标签交换的转发原理,就需要将转发平面和控制平面分开来看
详细转发原理:
给FEC分配标签后,MPLS联合IP,会将IP转发表FIB中的Tunnel ID赋值
如图,去往10.1.3.3的条目tunnel id为0x1,其他路由均为0x0
每个FEC都有对于设备而言唯一的
tunnel id与之对应为了给使用隧道的上层应用(如VPN、路由管理)提供统一的接口,系统自动为隧道分配了一个ID,也称为Tunnel ID。该Tunnel ID的长度为32比特,只是本地有效。
当IP数据来到该设备查到tunnel id不为0x0时,认为该设备为Ingress LSR,并根据tunnel id查询nhlfe表进入MPLS转发
下一跳标签转发表项NHLFE(Next Hop Label Forwarding Entry)

根据tunnel id查到的nhlfe表项转发动作,压入标签,从g0/0/0口传出
中间设备R2收到该标签报文后,查询mpls的ilm表项
入标签映射ILM(Incoming Label Map)
diagnose # 进入诊断模式
display mpls ilm # 查看mpls ilm表项

根据ILM表中入标签对应的Tunnel ID,查询nhlfe表

根据tunnel id查到的nhlfe表项转发动作,交换标签为stack指定标签,从g0/0/0口传出
stack指出标签值
出节点一般只会收到已经次末跳弹出的IP报文,如果收到标签报文,则先查标签表项(ilm+nhlfe),再查IP表项fib转发
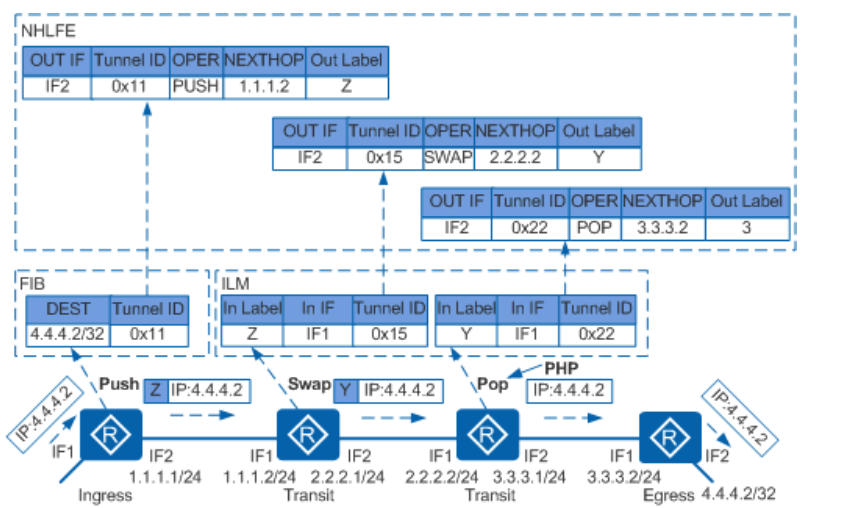
通过ping lsp 可以进行lsp连通性测试
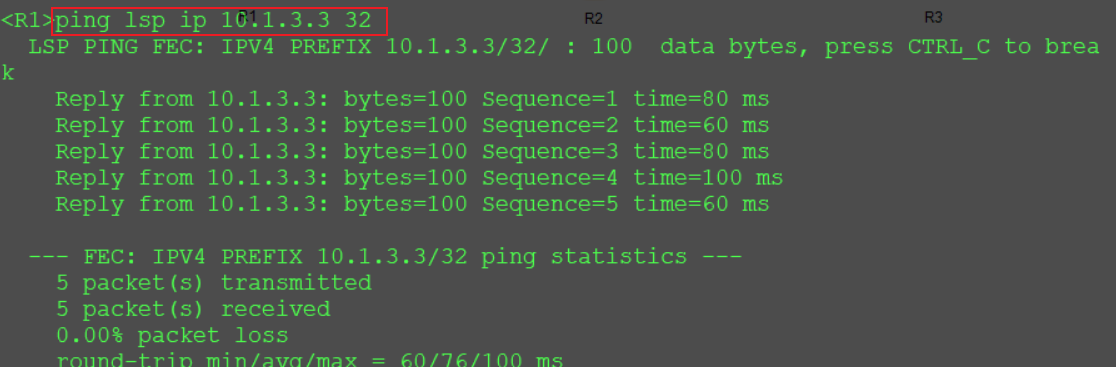
MPLS LDP 标签分发协议
MPLS的一种控制协议,负责转发等价类FEC的分类、标签的分配以及标签交换路径LSP的建立和维护等操作。
相当于IP网络中的OSPF
MPLS LDP协议的核心是MPLS LDP的邻居关系以及会话建立机制和LSP的建立机制
LDP SESSION建立
LDP协议位于应用层,使用四类消息进行交互:
- 发现(Discovery)消息:用于通告和维护网络中LSR的存在,一般专指Hello消息。
- 会话(Session)消息:用于建立、维护和终止LDP对等体之间的会话,如Initialization消息、Keepalive消息。
- 通告(Advertisement)消息:用于创建、改变和删除FEC的标签映射。
- 通知(Notification)消息:用于提供建议性的消息和差错通知。
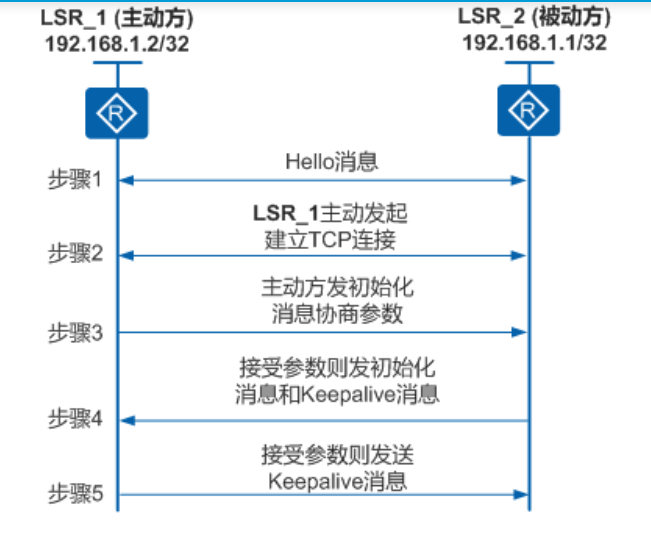
建立邻居关系:
设备使能MPLS LDP后,会使用UDP从使能MPLS LDP的接口上周期性(5s)发送Hello报文,目的地址为组播224.0.0.2
Hello报文每5s发送一次,如果15s没有收到邻居的Hello报文,则认为邻居断开
如果LSR在特定接口接收到LDP链路Hello消息,表明该接口存在LDP对等体。
两个设备成功交互Hello报文后,MPLS LDP邻居关系建立
建立会话:
邻居建立后,接口地址较大的一方作为主动方,发起TCP连接。
TCP连接建立成功后,由主动方发送初始化消息(Initialization),协商建立LDP会话的相关参数。
被动方收到初始化消息,做以下处理:
- 被动方接受消息中携带的参数,向主动方发送初始化消息,同时发送
Keepalive报文 - 被动方不接受消息中的参数,向主动方发送Notification消息终止LDP会话的建立
初始化消息中包括LDP协议版本、标签分发方式、Keepalive保持定时器的值、最大PDU长度和标签空间等
- 被动方接受消息中携带的参数,向主动方发送初始化消息,同时发送
主动方收到初始化消息后,接受相关参数,则发送Keepalive消息给被动方。
如果主动方不能接受相关参数,同样发送Notification消息终止LDP会话的建立。
当双方都收到Keepalive消息后,LDP会话建立成功
Keepalive消息周期性发送,时间间隔15s。如果45s内没有收到对端Keepalive报文,则认为LDP断开
会话分类:
MPLS LDP会话分为两类:本地LDP会话和远程LDP会话
二者的区别在于建立本地LDP会话的两个设备时直连的,而建立远程LDP会话的两个设备不一定
所以对于本地LDP会话,Hello消息以组播形式发送,而远程LDP会话以单播形式发送
LSR-ID与LDP-ID:
每个启动了MPLS的设备必须有唯一的LSR-ID,每个启动了LDP协议的设备也必须有LDP-ID
LDP-ID的长度为48bit,以32bit的LSR-ID + 16bit标签空间标识符组成,例如:2.2.2.2:0
标签空间标识符有两种:
- 值为0:表示基于设备的标签空间,标签在设备上唯一【缺省值为0】
- 值为1:表示基于接口的标签空间,标签在设备上可以重复,在接口上必须唯一
相关命令:
display mpls ldp peer # 查看ldp邻居信息
如图:PeerID表示邻居的LDP-ID,TransportAddress表示邻居用于建立TCP连接的地址
display mpls ldp session # 查看ldp会话信息
如图:
Status表示会话的状态,Operational表示建立成功,NonExistent表示建立失败;
LAM表示标签发布模式,默认DU
SsnRole表示LSR在LDP中的角色,Active表示主动方,Passive表示被动方
标签的发布与管理:LSP建立机制
LDP通过发送标签请求和标签映射消息,在LDP对等体之间通告FEC和标签的绑定关系来建立LSP,而标签的发布和管理由标签发布方式、标签分配控制方式和标签保持方式来决定。
标签发布方式:
在MPLS,由下游LSR将标签分发给特定FEC,再通知上游LSR。即标签的分配按从下游到上游的方向转发
标签发布有两种方式:
- 下游自主方式
DU:下游LSR无需从上游获得标签请求消息即进行标签分配与分发。 - 下游按需方式
DoD:LSR获得标签请求消息之后才进行标签分配与分发。
默认的,以太网转发使用DU,信令转发使用DOD
标签分配方式:
标签分配方式指LSR按什么原则决定要不要给FEC打标签
- 独立标签分配方式
Independent:本地LSR可以自主地分配一个标签绑定到某个FEC,并通告给上游LSR,而无需等待下游的标签。 - 有序标签分配方式
Ordered:只有当该LSR具有此FEC下一跳的标签映射消息、或者LSR就是此FEC的出节点时,该LSR才可以向上游发送此FEC的标签映射。
标签保持方式:
标签保持方式指LSR对收到的标签如何处理
- 自由标签保持方式
Liberal:从邻居LSR收到的标签映射,无论邻居LSR是不是自己的下一跳都保留。 - 保守标签保持方式
Conservative:从邻居LSR收到的标签映射,只有当邻居LSR是自己的下一跳时才保留。
以太网数据默认为:下游自主方式(DU)+ 有序标签分配控制方式(Ordered)+ 自由标签保持方式(Liberal)
当一个新的FEC加入网络时,首先由Egress将FEC和标签进行绑定,并以入节点的身份将这种绑定通告给邻居。
Transit收到标签映射消息后,判断标签映射的发送者(Egress)是否为该FEC的下一跳。若是,则在其标签转发表中增加相应的条目,然后主动向上游LSR发送对于指定FEC的标签映射消息。
Ingress收到标签映射消息后,判断标签映射的发送者(Transit)是否为该FEC的下一跳。若是,则在标签转发表中增加相应的条目。
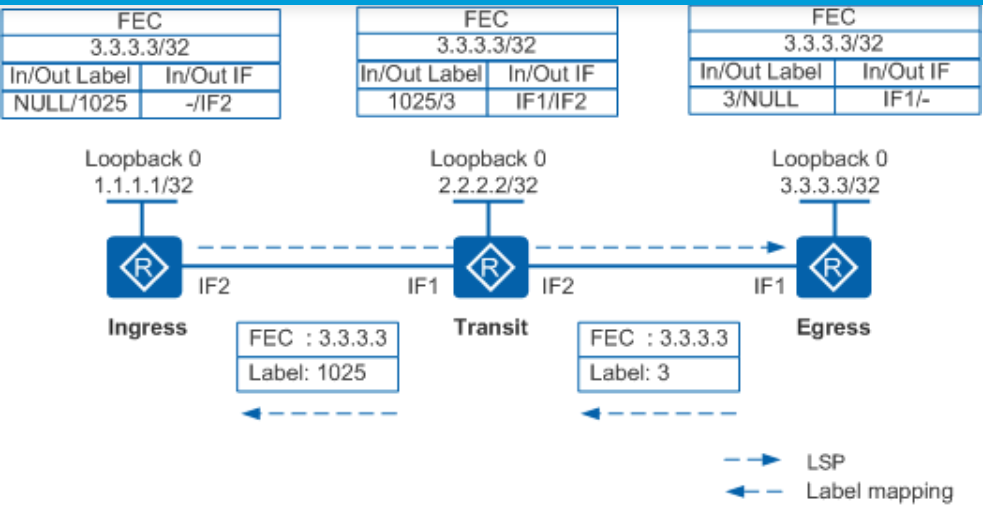
MPLS LDP配置
mpls lsr-id 10.1.1.1 # 配置mpls lsr-id
mpls # 全局使能mpls
mpls ldp # 全局使能mpls ldp
interface GigabitEthernet0/0/0
mpls # 接口使能mpls
mpls ldp # 接口使能mpls ldp
mpls lsp表条目解析:
查看mpls lsp转发表项时不难发现对于一个FEC,LDP总会创建两个条目
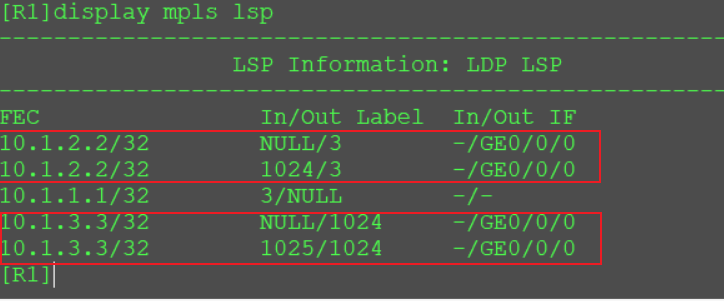
这是由于LSR作为Transit和Egress时,为了使后来的接入者快速加入MPLS网络,LDP会以Transit的身份创建一条标签为xxx/xxx、以Ingress的身份创建一条标签为NULL/xxx的表项
MPLS LDP标签分发原则:
LDP协议并不是给开启MPLS LDP设备的所有网段都创建标签转发,缺省时只会为主机路由分配标签
所以缺省时lsp表中全是32位掩码主机路由
可以通过命令改变:
lsp-trigger ? # 改变标签分配对象
all 给所有IGP路由分配
bgp-label-route 给mbgp(MPLS-BGP)协议的主机路由分配标签
host 给本地主机路由分配标签
ip-prefix 给ip-prefix匹配的路由分配标签
none 不分配标签
MPLS VPN
基本概念
BGP/MPLS IP VPN简称MPLS VPN,是在IP网络的基础上,结合BGP和MPLS组件的VPN网络。
VPN按照面向对象的不同,分为二层VPN
L2VPN(提供二层隧道)和三层VPNL3VPN(提供三层隧道)MPLS VPN是一种L3VPN(三层VPN)技术
MPLS VPN网络架构如下图所示: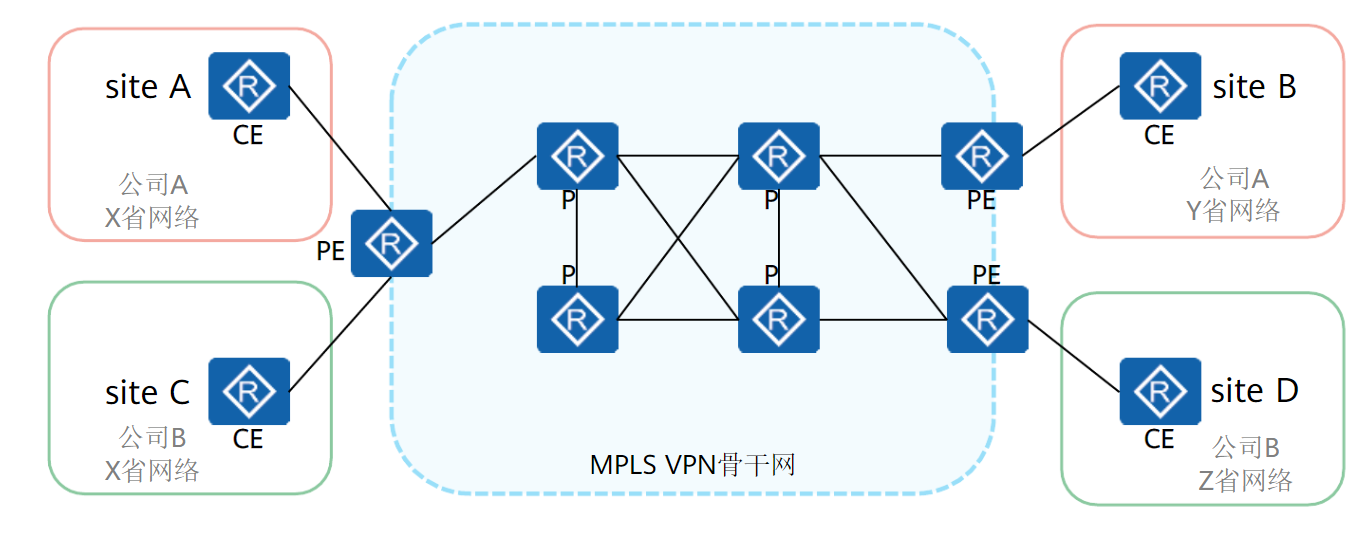
将网络分为以下角色
Site: 站点,指相互之间具备IP连通性的一组IP系统。一般将一个内部网络称为一个站点
一个Site可以属于多个VPN,一个VPN中也可以有多个Site
CE:用户私网和运营商VPN网络直连的出口设备,CE感知不到VPN实例,也不需要使能MPLS
PE:运营商VPN网络中直连用户私网的入口设备,对VPN的所有处理都发生在PE上
P:运营商提供的VPN网络中的骨干设备,只负责基本的MPLS标签转发
VPN 网络由服务提供商构建向用户提供,用户自己无法构建(除非拉专线打通站点)
构建VPN的目的就是为了让用户私网站点互通
比如A公司总部在北京,分部在深圳,且两个部门有数据交换的需要,此时通过公网直接发送有数据泄露的风险,总是要经过NAT地址转换也不方便
现在普遍使用两种方案解决这个问题:
- 专线:直接拉一根网线打通两个部门的私网,部门间数据交换通过这跟网线。这根网线称为专线
- 专线虽好,但不是人人都可以拉,一是成本高,普通企业负担不起,二是挖地埋线需要资质,绝大多数企业都没有部署专线的资质
- 现在普遍使用专线组网的企业有三大运营商,国家电网,国防等
- VPN: VPN技术是在公网上建立一条私网隧道,从而达到安全传递私网路由,打通私网的目的。
- 比起专线,VPN的安全性有所不足,但成本低
- VPN大多是由运营商提供服务
BGP/MPLS IP VPN支持地址空间重叠、支持重叠VPN、组网方式灵活、可扩展性好,并能够方便地支持MPLS TE,成为在IP网络运营商提供增值业务的重要手段,因此得到越来越多的应用。
MPLS VPN由以下技术组合形成:
- MP-BGP:扩展了标签转发功能的BGP协议,支持VPNv4路由的传递
- LDP :MPLS LDP协议,负责组建MPLS转发网络
- VRF:虚拟路由转发,又称VPN实例,一个VPN对应一个VRF。每个VPN实例都由独立的路由表和转发表,实现VPN之间的逻辑隔离
- 静态路由、IGP、BGP:负责CE和PE之间的路由传递
MPLS VPN 路由交互过程
MPLS VPN需要从路由交换过程和流量转发过程两个部分来看
路由交互过程指不同Site互相学到对方路由的交互过程,如图所示:
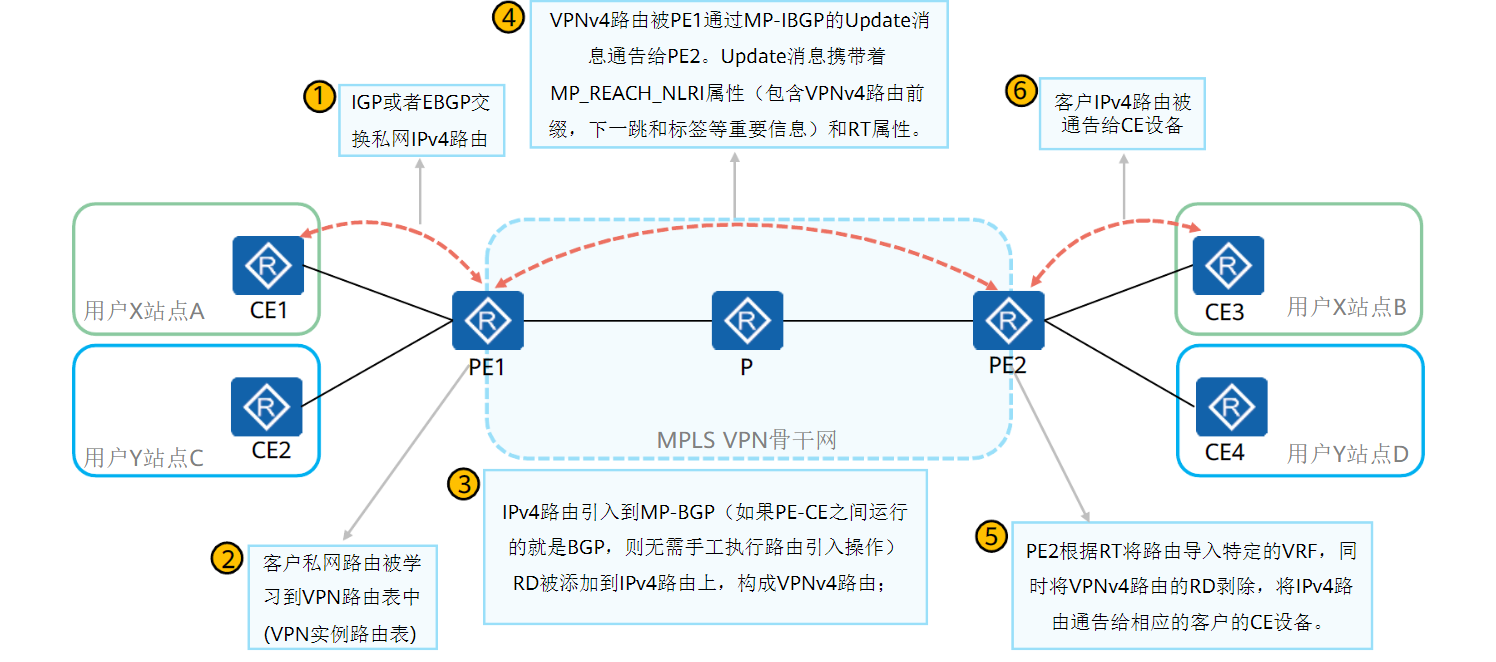
术语解释:
路由标识符RD(Route Distinguisher):VPN的”身份证号”,唯一标识一个VPN。
RD命令规则遵循
AA:NN格式,AA是指VPN实例所在AS号,NN由管理员自行分配RD只具有本地意义,也就是说不同路由器的VPN实例可以配置相同的RD,但在路由交互过程中,相同RD的路由被认为属于一个VPN(即使Site不同)。
为了避免冲突问题,需要预先规划好RD
VPNv4路由:增加了RD的IPv4地址称为VPN-IPv4地址,如
1:1 192.168.1.1由于RD唯一标识一个VPN,所以
RD+IPv4唯一标识一条路由,杜绝地址冲突的可能性BGP VPNv4 family: BGP协议VPNv4地址簇,用于传递VPNv4路由VPNv4簇和IPv4簇以及其他簇均相互隔离,但配置只是将IPv4簇中的配置放在VPNv4簇中
VPN Target:简称RT,MP-BGP扩展的团体属性,用于决定传到PE的VPNv4由那个VPN实例接收
RT式和RD格式一样,均为
AA:NNRT分为
import RT和export RTexport RT:PE发布VPNv4路由时会携带事先配置好的RT作为BGP的扩展团体属性随路由发布import RT:PE收到VPNv4路由时,检查本端是否有VPN实例的import RT中存在路由携带的任何一个export RT,有则交由对应VPN实例接收,无则丢弃
MP-BGP内层标签:PE发送VPNv4路由会同时携带一个由MP-BGP发布的标签,对端收到路由会创建对应MP-BGP标签转发条目
在路由交换中无意义,主要用于流量转发
假设有条路由从Site A传递给Site B,那么该路由会经历如下过程:
CE和PE绑定了VPN实例的接口建立正常的IGP、EBGP、静态路由,将私网IPv4路由传递给PE设备接口绑定的VPN实例
PE将收到的IPv4路由保存到对应实例的路由表中
如果是通过EBGP传递路由,直接建立CE-IPV4簇到PE-VPN实例簇的邻居关系
如果是IGP、静态路由,通过在PE对应IGP、静态路由进程中绑定VPN实例,将IPv4路由加载到VPN实例路由表
PE将VPN实例中的路由加上RD前缀交给MP-BGP VPNv4簇传递
管理员手动配置,引入对应实例即可
VPNv4路由通过MPLS标签转发传递到对端VPNv4簇MP-BGP对等体(对端PE)
对端PE检查路由携带
export RT是否有任何一个对应自身实例的import RT,有则保存到对应VPN实例路由表中由VPN实例通过EBGP、IGP、静态的方式传递给Site B
MPLS VPN流量转发过程
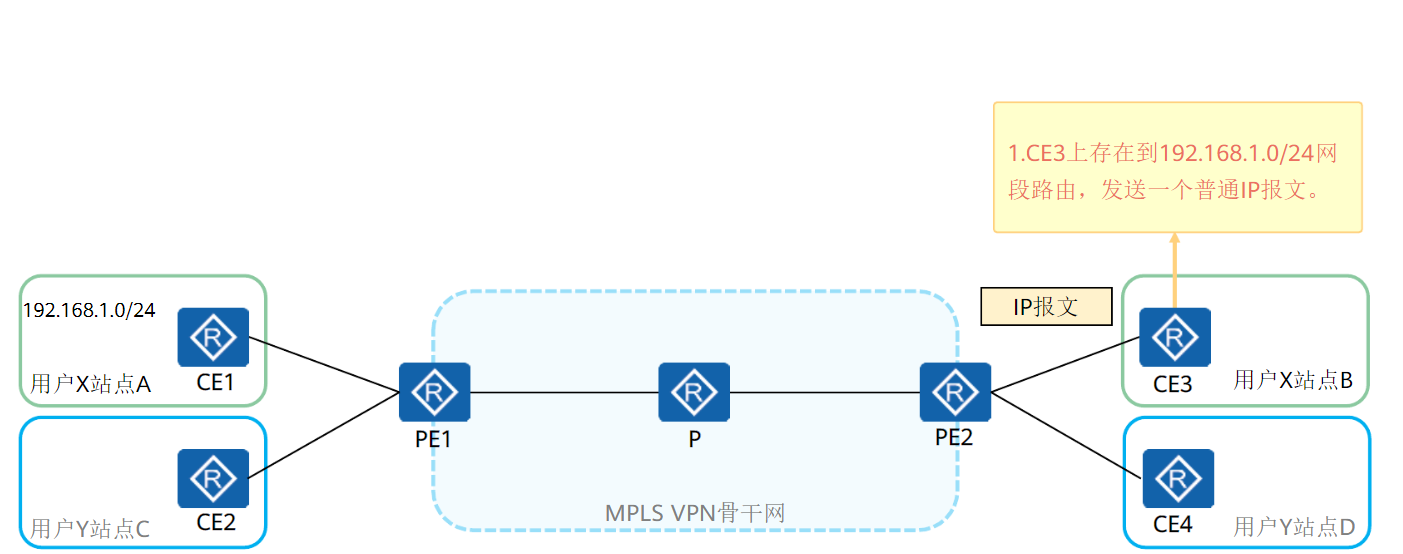
现在路由以及传递到了CE3,CE3需要向SiteA发送数据
数据发送到PE2,由PE2根据对应VPN实例的路由条目打上内层MP-BGP标签
路由有RD和RT标识,可以准确传递到对端,但流量没有。所以路由传递时就携带了一个内层标签,用于指导流量转发
PE2通过MPLS网络,打上LDP标签发往对端PE
此时流量在MPLS网络中携带两层标签
对端PE接收,通过内层标签指导转发,将流量发往对应的VPN实例
注意事项:
由于MPLS LDP协议默认基于host发布标签,所以MPLS VPN网络中不能做路由聚合
MP-BGP EBGP和IBGP邻居都会自动更新下一跳地址,并不止是EBGP自动更新
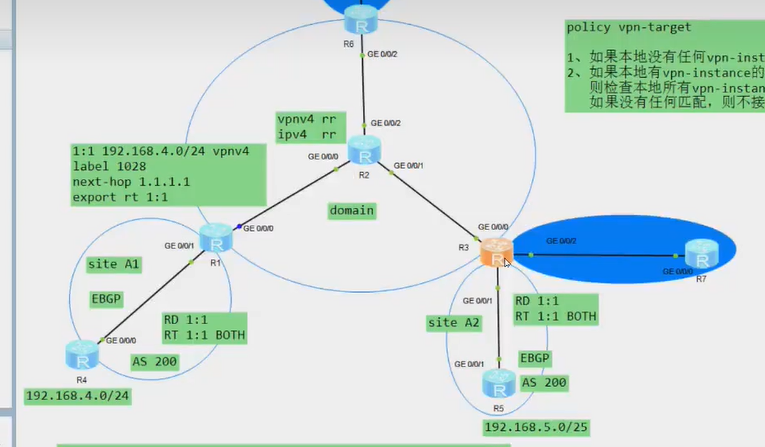
对于存在RR反射器网络,路由会先传递给RR,在由RR反射给对端PE
但RR并没有对应的VPN实例,为了让RR可以顺利接收并反射路由,需要关闭RT检查
bgp 100
ipv4-family vpnv4
undo policy vpn-target # 关闭RT检查
关闭检查后路由直接写入VPNv4路由表中,而不传递给VPN实例路由表
MPLS VPN组网命令配置:
CE: 【正常OSPF即可】
ospf 10
area 0.0.0.0
network 10.1.1.1 0.0.0.0
network 10.1.12.0 0.0.0.255
PE:【比较复杂】
将CE的路由放到VPN实例中,然后将对应的路由发布到MP-BGP
# VPN实例
ip vpn-instance VPN1 # 创建一个VPN实例
ipv4-family # 进入ipv4簇
route-distinguisher 100:1 # 设置RD为100:1
vpn-target 100:1 export-extcommunity # 设置export RT 100:1
vpn-target 100:2 import-extcommunity # 设置import RT 100:2
# 接口绑定
interface GigabitEthernet0/0/0
ip binding vpn-instance VPN1 # 将VPN实例绑定到接口
-- 注意:绑定VPN实例后接口原有的配置会全部清空,需要重新配置
ip address 10.1.12.2 255.255.255.0
# OSPF 配置
ospf 10 vpn-instance VPN1 # 创建ospf进程10并绑定VPN实例
import-route bgp # 引入BGP路由
-- 这里是为了将收到的对端PE路由发布给CE
area 0.0.0.0
network 10.1.12.0 0.0.0.255
# BGP配置
bgp 100 # 配置BGP
peer 10.1.5.5 as-number 100 # 宣告邻居
peer 10.1.5.5 connect-interface LoopBack0
ipv4-family unicast
undo synchronization
undo peer 10.1.5.5 enable
# 缺省时邻居自动使能ipv4簇,但MPLS VPN 只需要VPNv4邻居关系,所以可以undo掉
ipv4-family vpnv4
policy vpn-target # 【缺省开启】使能RT检查
peer 10.1.5.5 enable # 建立VPNv4邻居关系
ipv4-family vpn-instance VPN1 # 进入VPN1簇
network 10.1.1.1 255.255.255.255 # 将VPN1中的10.1.1.1宣告进MP-BGP成为VPNv4路由
# 使能MPLS LDP
mpls lsr-id 10.1.2.2
mpls
mpls ldp
interface GigabitEthernet0/0/1
mpls
mpls ldp
P配置:【正常使能MPLS LDP】
mpls lsr-id 10.1.3.3
mpls
mpls ldp
interface GigabitEthernet0/0/1
mpls
mpls ldp
如果CE和PE之间是通过EBGP交互私网路由,则CE正常配置,PE需要在
ipv4-family vpn-instance中宣告邻居,而不是直接宣告【直接宣告是以IPv4 Public的身份宣告并建立邻居关系】bgp 100 ipv4-family vpnv4 policy vpn-target # 【缺省开启】使能RT检查 peer 10.1.5.5 enable # 建立VPNv4邻居关系 ipv4-family vpn-instance VPN1 # 进入VPN1簇 peer 10.1.12.1 as 65001 # 宣告和CE的EBGP邻居关系 network 10.1.1.1 255.255.255.255 # 将VPN1中的10.1.1.1宣告进MP-BGP成为VPNv4路由
IPV6网络
IPv6涉及太多了,单独写了一个笔记,有需要可以去我博客看
BGP高级特性技术
正则表达式
正则表达式是按一定模板来匹配字符串的公式,和各大编程语言一样,可以将组成表达式的字符分为两类
- 普通字符:没有正则含义,表达原本意思的字符
- 特殊字符:正则语法涉及的字符
除特殊字符之外的字符都是普通字符
例如:
^123_;^和_是特殊字符,关系到正则的语法,123是普通字符,就只是表达123的意思
特殊字符:



匹配规则和编程语言正则一致
BGP对等体组:Peer Group
原理描述
在大型BGP网络中,往往有众多存在相同配置的BGP对等体,可以把这些对等体创建为一个对等体组。
使用对等体组进行批量配置,以达成简化管理的难度,提高路由发布效率的目的。
在存在RR-路由反射器的场景中应用较多
根据对等体所在的AS是否相同,对等体组可分为以下三类:
- IBGP对等体组:所包括的对等体属于同一个内部AS。
- 纯EBGP对等体组:所包括的对等体属于同一个外部AS。
- 混合EBGP对等体组:所包括的对等体属于不同的外部AS。
这三类对等体组原理一致,只是配置命令不同
新加入的对等体如果没有单独的配置,那么将继承对等体组的配置。
加入对等体组之后,如果某个BGP对等体有特殊的配置要求,还可以进行单独的配置,单个对等体的配置将覆盖从对等体组继承的配置。
可向组中加入多个对等体。如果该对等体还未创建,系统会自动在BGP视图下创建该对等体,并设置其AS编号为对等体组的AS编号。
配置命令
配置IBGP对等体组
配置IBGP对等体组不需要指定自治系统号,直接使用本设备的自治系统号。
bgp 200
group 1 internal # 创建对等体组 1
peer 1 connect-interface LoopBack0 # 设置对等体组1的对等体都由环回口0建立邻居关系
peer 10.1.1.1 group 1 # 将10.1.1.1 加入组
peer 10.1.2.2 group 1 # 将10.1.2.2 加入组
ipv4-family unicast
peer 1 enable
peer 1 reflect-client # 设置对等体组1中的所有对等体都是RR客户
配置纯EBGP对等体
配置纯EBGP对等体需要给对等体组指定对端AS号
bgp 200
group 1 external # 创建对等体组 1
peer 1 as-number 100 # 指定对等组组1的所有对等体AS为100
peer 1 connect-interface G 0/0/1 # 设置对等体组1的对等体都由g0/0/1建立邻居关系
peer 10.1.1.1 group 1 # 将10.1.1.1 加入组
peer 10.1.2.2 group 1 # 将10.1.2.2 加入组
配置混合EBGP对等体组
配置混合EBGP对等体组时,需要单独指定各对等体的自治系统号。
bgp 200
group 1 external # 创建对等体组 1
peer 1 connect-interface G 0/0/1 # 设置对等体组1的对等体都由g0/0/1建立邻居关系
peer 10.1.1.1 as 200 # 创建对等体
peer 10.1.1.1 group 1 # 将10.1.1.1 加入组
peer 10.1.2.2 as 100 # 创建对等体
peer 10.1.2.2 group 1 # 将10.1.2.2 加入组
其他配置:
# 配置对等体组描述信息方便网络管理
peer group-name description description-text
# 查看对等体组信息
display bgp group [ group-name ]
路由匹配工具 : AS_Path Filter
原理描述
任何协议中,对路由/流量的控制大体都可以分为两步
- 使用匹配工具抓取路由/流量
- 使用策略工具处理抓取到的路由/流量
绝大多数工具都只实现了一种功能,只有少数工具兼顾匹配和处理两种功能
AS_Path Filter 就是BGP协议定义的,抓取AS_Path属性的路由匹配工具,除了抓取对象是AS_Path外,和其他匹配工具(ACL、IP-Prefix)没有本质区别
AS_Path Filter中的permit和deny同样可以理解为【抓取】和【不抓取】,路由没有匹配到则:默认【不抓取】
AS_Path Filter抓取的是对应AS_Path的所有路由
AS_Path添加原则:
- 路由初入AS时,设备检查AS_Path是否有本AS的AS号,无则接收,有则丢弃
- 路由离开AS时,设备将本AS号添加到AS_Path最前面(最左边)
- 发送给IBGP不改变AS_Path
所以最右边AS是路由始发位置,越往左距离当前AS越近
BGP路由的AS_Path属性实际上可以看作是一个包含空格的字符串,所以可以通过正则表达式来进行匹配。

配置命令
创建AS_Path Filter过滤器
ip as-path-filter deny_100 deny _100$ # 不抓取AS_Path以100结尾的路由
ip as-path-filter deny_100 permit .* # 抓取剩下的全部
方案一:在BGP中直接调用AS_Path Filter
bgp 300
ipv4-family unicast
peer 10.1.59.5 as-path-filter deny_100 import
# 接收从10.1.59.5发来的,AS_Path过滤器deny_100抓取到的入方向路由
方案二:通过路由策略调用
# 用route-policy调用AS_Path Filter
route-policy deny_100 permit node 10
if-match as-path-filter deny_100
# 在BGP中调用route-policy
bgp 300
ipv4-family unicast
peer 10.1.59.5 route-policy deny_100 import
路由匹配工具:Community Filter
原理描述
同AS_Path Filter一样,Community Filter同样也是BGP协议下的一种路由匹配工具
AS_Path Filter配合AS_Path属性使用,Community Filter配合Community属性使用
Community Filter有两种类型
- 基本
Community Filter:匹配团体号或公认团体属性 - 高级
Community Filter:使用正则表达式匹配团体号
BGP设备在将带有团体属性的路由发布给其它对等体之前,可以先改变此路由原有的团体属性。
团队属性可以自定义,同时BGP也有一些定义好的公认团体属性
路由器对公认团体属性有默认的处理动作,自定义团体属性的动作也需要自己定义
一条路由可以有多个团体属性
公认团体属性:
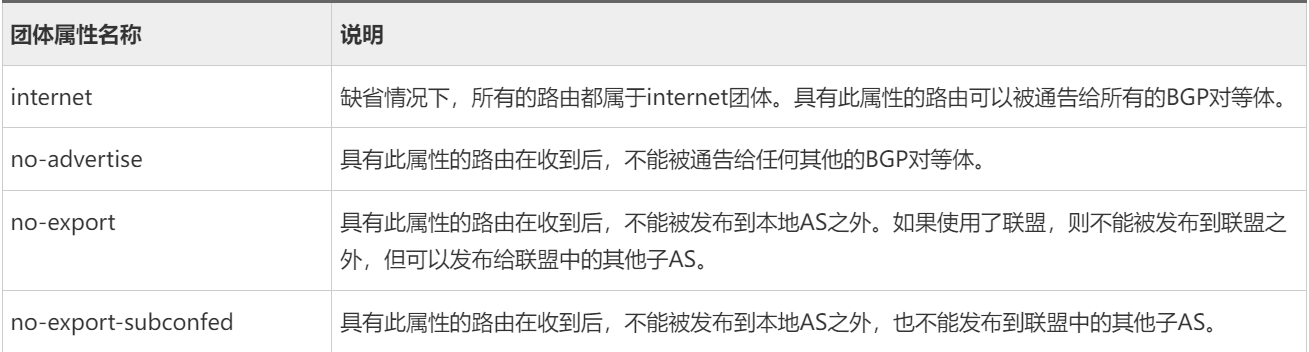
自定义团体属性:
- Community属性是一组4个字节的数值,对应团体属性的定义,RFC1997规定前两个字节表示AS号,后两个字节表示基于管理目的设置的标示符,格式为AA:NN。
- 例如:
100:1表示AS号为100,设置的管理标识符为1 - 也可以直接定义为一个十进制整数【不推荐】
类似基本ACL编号为2000-2999,高级ACL为3000-3999的编号划分,团体属性过滤器也有编号范围
团体属性过滤器Community Filter编号范围
- 基本
Community Filter:1-99 - 高级
Community Filter:100-199
配置命令
要使用团体属性过滤器,前提是路由携带了Community属性。如下图:
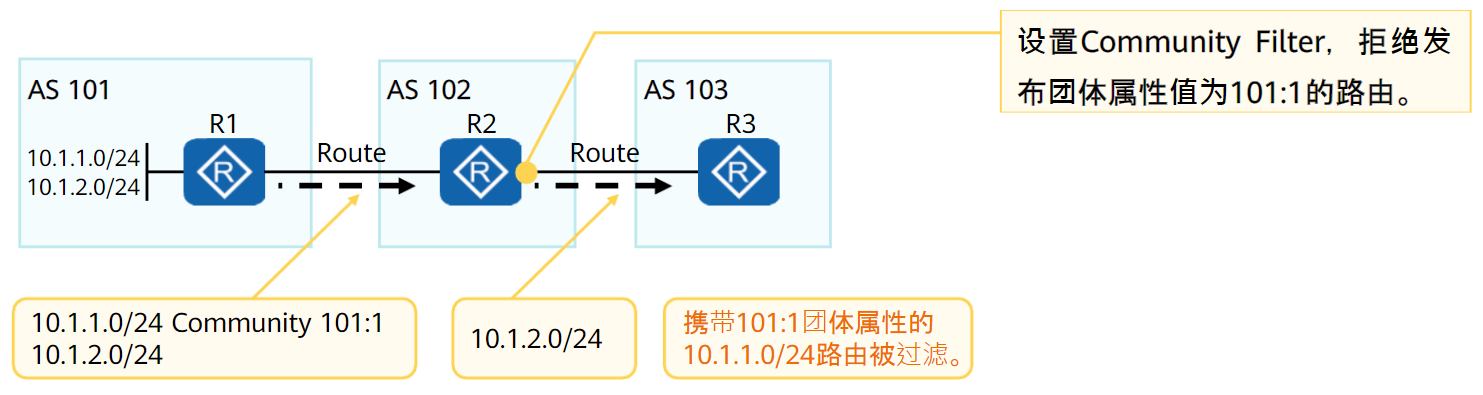
给路由设置团体属性
ip ip-prefix 1 index 10 permit 100.100.100.100 32
route-policy 1 permit node 10
if-match ip-prefix 1
apply community 100:1 # 赋予团体属性100:1
route-policy 1 permit node 20
配置使能将团体属性发布给对等体
默认情况下,Community属性是不会随路由前缀更新给BGP peer的,因此在路由途径的对等体上都需要通过peer advertise-community配置将团体属性发布给对等体的功能。
bgp 100
ipv4-family unicast
peer 10.1.18.1 route-policy 1 export # 使用路由策略
peer 10.1.18.1 advertise-community # 使能将团体属性发布给对等体
使用Community Filter抓取打了团体属性的路由并过滤
# 抓取团体属性100:1
ip community-filter 1 permit 100:1
# 使用route-policy处理
route-policy de deny node 10
if-match community-filter 1
route-policy de permit node 20
# bgp调用route-policy
peer 10.1.59.5 route-policy de import
出口路由过滤器:ORF
原则描述
出口路由过滤器ORF,全称Outbound Route Filters
技术背景:
AS之间往往需要做一些策略,并且在路由出方向做策略比入方向更优。但不同AS往往不能互通,不同AS的网络维护人员也无权维护对端AS设备,这就导致了策略几乎只能做在路由入方向。
本来就要过滤的路由任然被传入AS内,极大的浪费了带宽和设备资源。频繁联系对端维护人员也不现实
出口路由过滤器ORF可以解决这类问题
基于前缀的ORF能力,能将用户配置的基于前缀的入口策略通过路由刷新报文发送给对端,对端自动将这些策略应用到出口策略,从而在路由发送时对路由进行过滤,避免用户接收大量无用路由,节省资源。
ORF支持路由按需发布,在降低对带宽占用的同时,可以有效减少配置工作。
ORF处理的必须是基于前缀列表(ip-prefix)的过滤策略
配置命令
首先查看对端路由发送,以及本端路由接收情况
对端路由发送
dis bgp routing-table peer 10.1.59.9 advertised-routes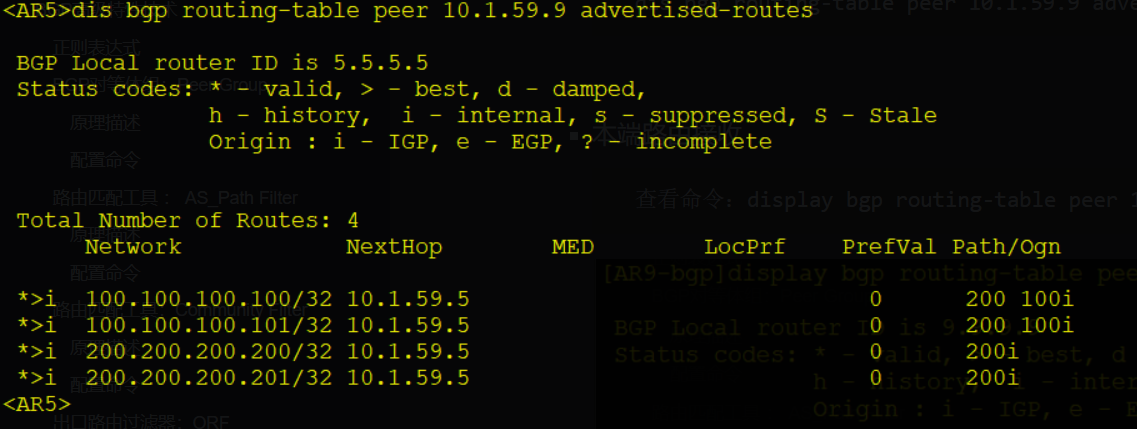
本端路由接收
查看命令:display bgp routing-table peer 10.1.59.5 received-routes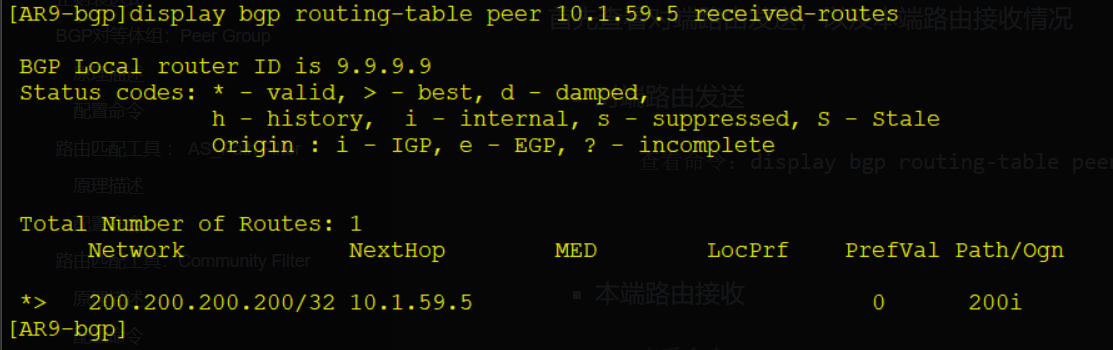
可知对端发送4条,本端接收一条,三条浪费带宽
配置对等体基于前缀列表的路由过滤策略
# 配置前缀列表
ip ip-prefix 1 index 10 permit 200.200.200.200 32
# bgp直接调用前缀列表生成入向过滤策略
bgp 300
ipv4-family unicast
peer 10.1.59.5 ip-prefix 1 import
在对等体两端同时开启ORF
本端:
bgp 300
ipv4-family unicast
peer 10.1.59.5 capability-advertise orf ip-prefix send # 本端send(发送)
对端:
bgp 200
ipv4-family unicast
peer 10.1.59.9 capability-advertise orf ip-prefix receive # 对端receive(接收)
查看本端和对端路由发送/接收情况
对端路由发送
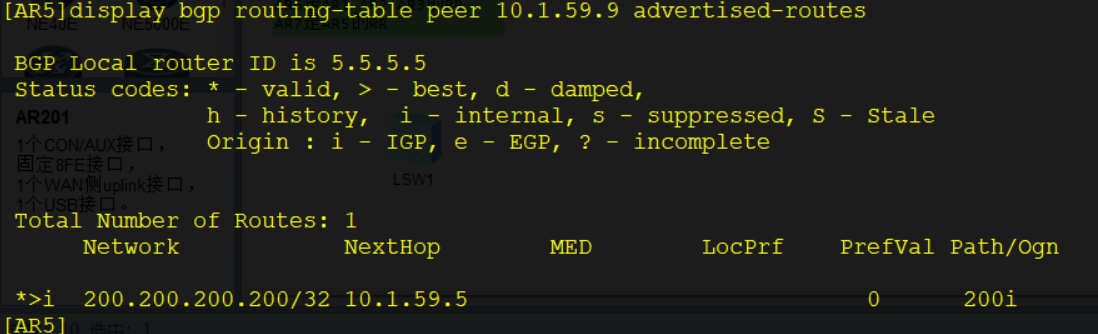
本端路由接收
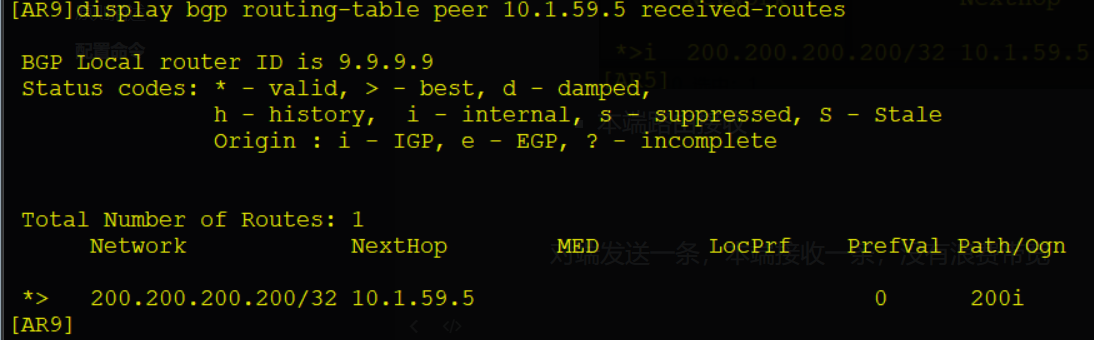
对端发送一条,本端接收一条,没有带宽浪费
BGP安全性
常见的BGP攻击有两种:
- 建立非法的BGP邻居关系,通告非法路由条目干扰路由表
- 发送大量的非法BGP报文,路由器收到后上送CPU,导致CPU利用率提高
BGP认证
BGP认证通过建立BGP对等体时验证”密码”,从而预防非法邻居关系建立
分为MD5认证和Keychain认证,并且这两种认证互斥
链路两端要进行相同的配置
MD5认证
通过在建立TCP连接时验证密码,预防非法邻居关系建立
配置简单,但只能针对TCP连接的建立过程进行认证,无法作用于其他过程
- 最明显的现象就是给已经建立邻居关系的对等体一端设备配置MD5认证,邻居关系不会断开
在配置MD5认证密码时,如果使用simple选项,密码将以明文形式保存在配置文件中,存在安全隐患。建议使用cipher选项,将密码加密保存。MD5认证存在安全风险。
为防止BGP对等体所设置的MD5密码被破解,需要周期性的更新MD5认证密码。
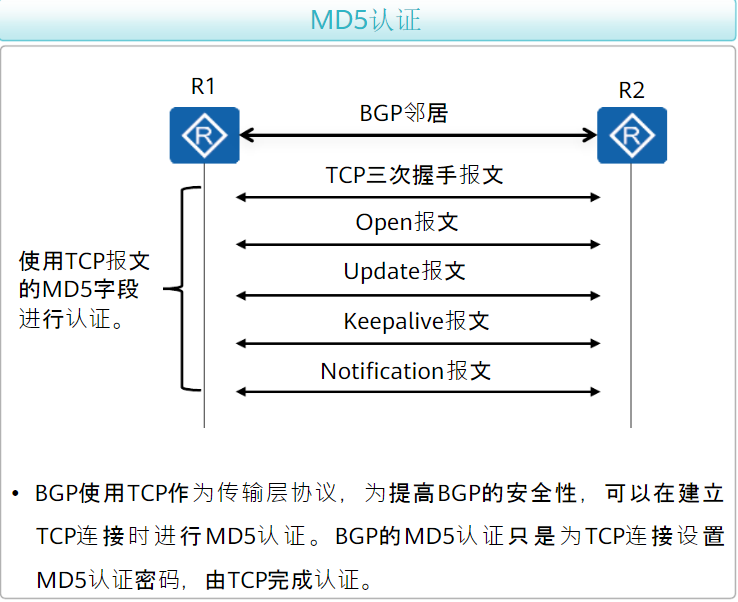
配置:
bgp 100
peer 10.1.18.1 as-number 200
peer 10.1.18.1 password cipher [密码]
Keychain认证
Keychain认证相对MD5认证安全性更高,但配置也更加麻烦,适用于对安全要求较高的网络
BGP对等体两端必须都配置针对使用TCP连接的应用程序的Keychain认证,且配置的Keychain必须使用相同的加密算法和密码,才能正常建立TCP连接,交互BGP消息。
Keychain认证推荐使用SHA256和HMAC-SHA256加密算法。
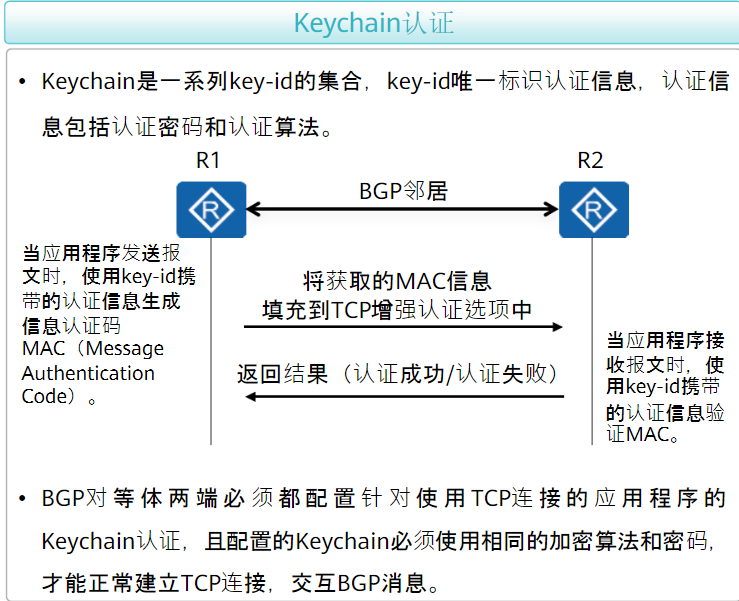
配置:
配置keychain认证需要提前配置keychain
bgp 100
peer 10.1.18.1 as-number 200
peer 10.1.18.1 keychain [keychainName]
其他命令:
display bgp peer verbose # 查看对等体详细信息
BGP GTSM(通用TTL安全保护机制)
争对伪造非法BGP报文的攻击,由于TTL机制,无论报文如何逼真,TTL值一定有问题
比如路由器和邻居直连,收到的TTL应为255,但攻击者不和BGP设备直连,发送给设备的TTL就会小于255
GTSM功能通过检测IP报文头中的TTL值。根据实际组网的需要,对于不符合TTL值范围的报文,GTSM可以设置为通过或丢弃。
TTL计算公式:
[255-hops+1 : 255]注:从环回口始发的报文到设备时,TTL也会减一
配置:
bgp 300
peer 10.1.59.5 valid-ttl-hops 255 # 设置有效TTL最小255
其他配置:
gtsm default-action { drop | pass } # 设置未匹配GTSM策略的报文的缺省动作
gtsm log drop-packet all # 打开单板的LOG信息的开关,在单板GTSM丢弃报文时记录LOG信息
缺省情况下,未匹配GTSM策略的报文可以通过过滤。
缺省情况下,不记录单板的LOG信息
这两条命令在模拟器上敲不上去
RR组网
为了增加网络可靠性,有时需要在一个网络中部署多个RR,在这类场景下,可以将RR的组网方式分为两类
单集群RR组网
也叫备份RR组网
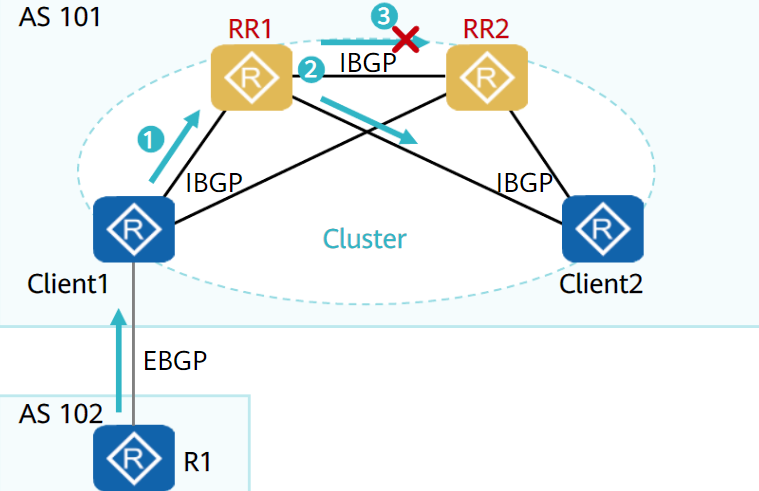
如图,两个RR在一个集群内,配置了相同的簇ID(Cluster ID)
缺省情况下,每个路由反射器使用自己的Router ID作为集群ID(
Cluster ID)。
Client1、Client2和RR1、RR2都建立邻居关系,RR1、RR2之间建立普通IBGP关系(非客户)
RR反射原则:
从客户学到的路由,反射给所有对等体(客户和非客户)
从非客户学到的路由,反射给所有客户
- 对于Client而言,会收到两个RR反射的路由,形成冗余链路
- 对于RR而言,两个RR都独立工作,由于具有相同簇ID,根据RR反射器防环规则,两个RR都会丢掉对方发给自己的路由
单集群RR组网问题
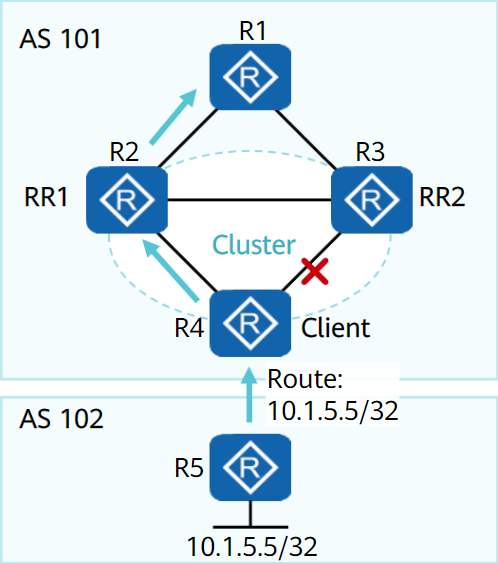
如图,AS内多个RR单集群组网,如果R4和反射器R3之间的邻居关系断开(配置错误、网络波动等原因)
此时RR1仍然将R4的路由反射到R1,而RR2由于和R4没有邻居关系,不会反射R4的路由
最终导致虽然有两个RR,但链路故障后失去的冗余链路(R1到R4此时只有RR1反射的路由)
想要解决这个问题,就需要配置簇ID不同的多集群组网
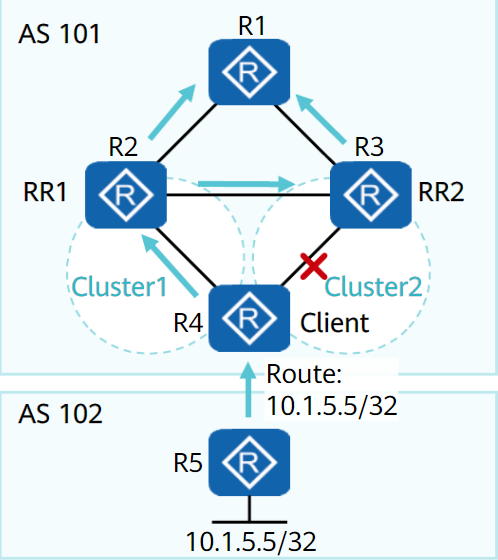
此时R4和RR2断开,但由于RR1和RR2之间有不同的簇ID,RR1将从R4学到的路由同时反射给R1和RR2
RR2和R1仍然存在邻居关系,所以将路由反射给R1
此时R1到R4有从RR1学到的和RR2学到的2条路由,冗余仍然存在
多集群RR组网
综上,在比较复杂的网络中,多集群RR组网比单集群更优,多集群组网又分为两种方案
多集群全互联组网
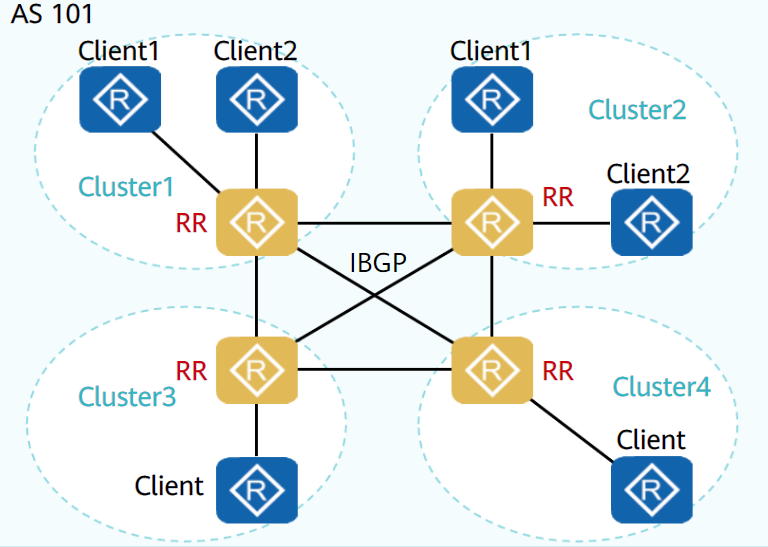
如图,每个RR都和本集群的Client建立IBGP对等体,同时RR之间建立普通IBGP对等体(非客户)关系并形成全互联
此时图中4个RR都属于同级关系,除非链路全断,否则一直存在三个链路的冗余
多集群分级组网
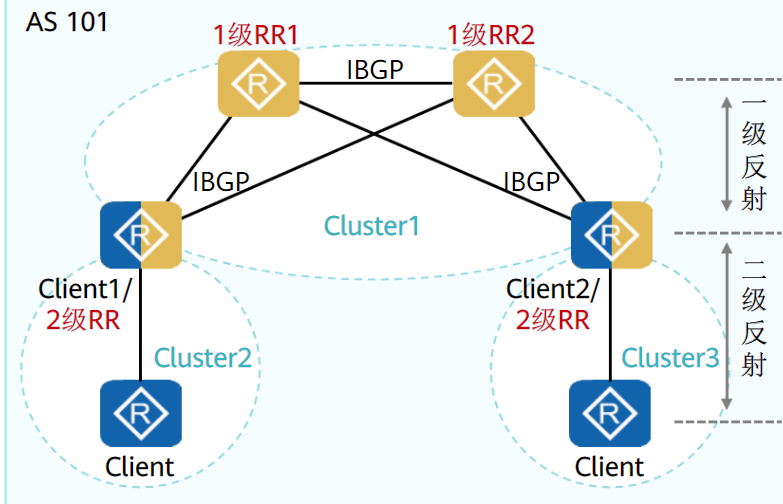
如图,将核心设备分入一个簇,其他设备分入不同簇,就是多集群下的分级组网
以核心的RR为一级反射,使客户端路由互通
同时一级RR的客户端也是二级反射簇的RR,负责本客户端集群的路由反射
RR组网示例
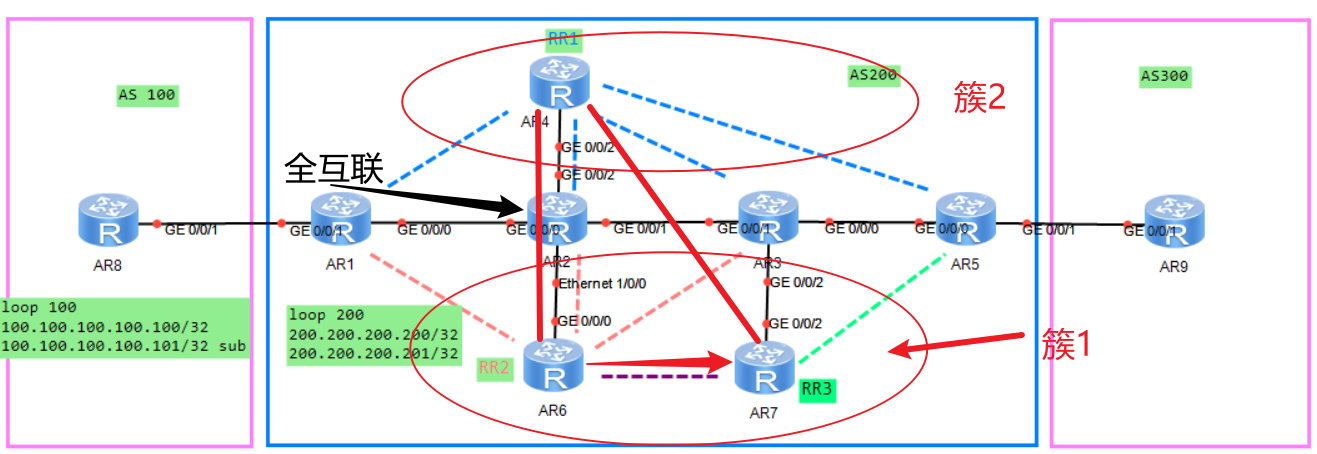
上图拓扑可以分为两块
- RR1单独维护AR1-4的路由
- RR2和RR3共同维护AR1-4的路由
所以RR2和RR3肯定要建立对等体关系,由于两个RR的客户没有重复,所以划入一个簇
RR1可以选择和RR2、RR3一个簇并全互联形成单集群备份组网,但由于单集群组网局限性,这里不优先考虑
为避免局限性,将RR1划入一个单独的簇,和RR2、RR3形成全互联的多集群组网
可以简单写为如下逻辑图:
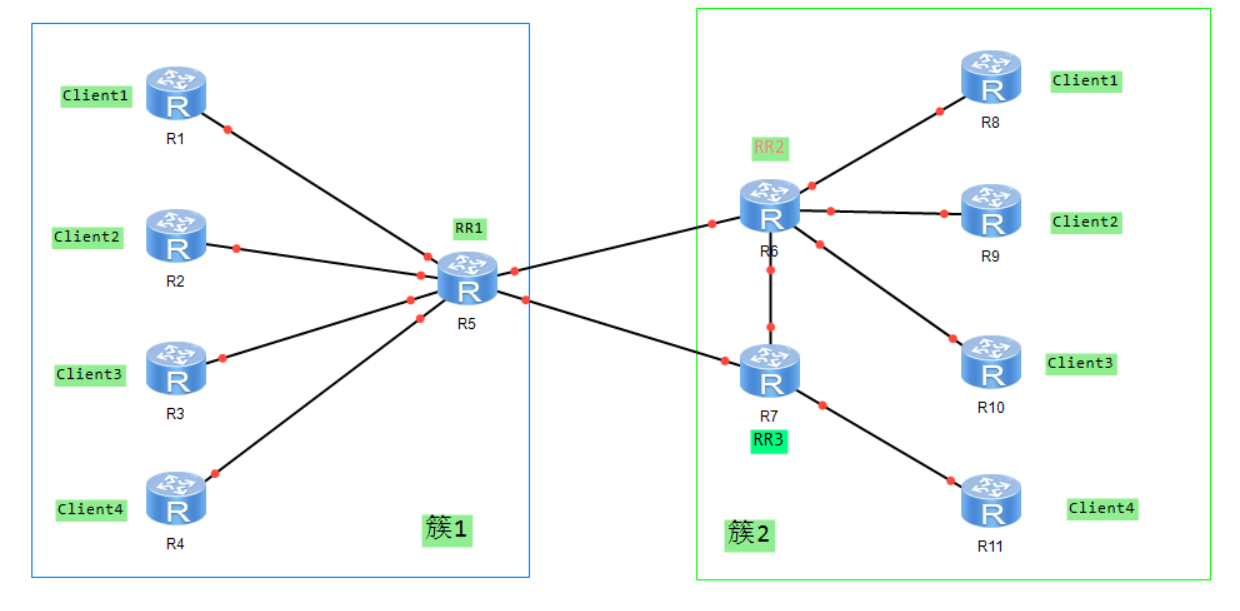
配置命令:
各Client已经和对应RR建立了邻居关系
RR1
bgp 200
# 将client加入一组
group client_peer internal
peer client_peer connect-interface LoopBack0
peer 10.1.1.1 group client_peer
peer 10.1.2.2 group client_peer
peer 10.1.3.3 group client_peer
peer 10.1.5.5 group client_peer
# 将rr加入一组
group rr internal
peer rr connect-interface LoopBack0
peer 10.1.6.6 group rr
peer 10.1.7.7 group rr
ipv4-family unicast
# 设置RR1簇ID为10.1.4.4
reflector cluster-id 10.1.4.4
# 将client设为RR1客户
peer client_peer reflect-client
RR2
bgp 200
group client_peer internal
peer client_peer connect-interface LoopBack0
peer 10.1.1.1 group client_peer
peer 10.1.2.2 group client_peer
peer 10.1.3.3 group client_peer
peer 10.1.7.7 group client_peer
group rr internal
peer rr connect-interface LoopBack0
peer 10.1.4.4 group rr
ipv4-family unicast
reflector cluster-id 10.1.67.67
peer client_peer reflect-client
RR3
bgp 200
group client_peer internal
peer client_peer connect-interface LoopBack0
peer 10.1.5.5 group client_peer
peer 10.1.6.6 group client_peer
group rr internal
peer rr connect-interface LoopBack0
peer 10.1.4.4 group rr
ipv4-family unicast
reflector cluster-id 10.1.67.67
peer client_peer reflect-client
此时查看AR5路由表
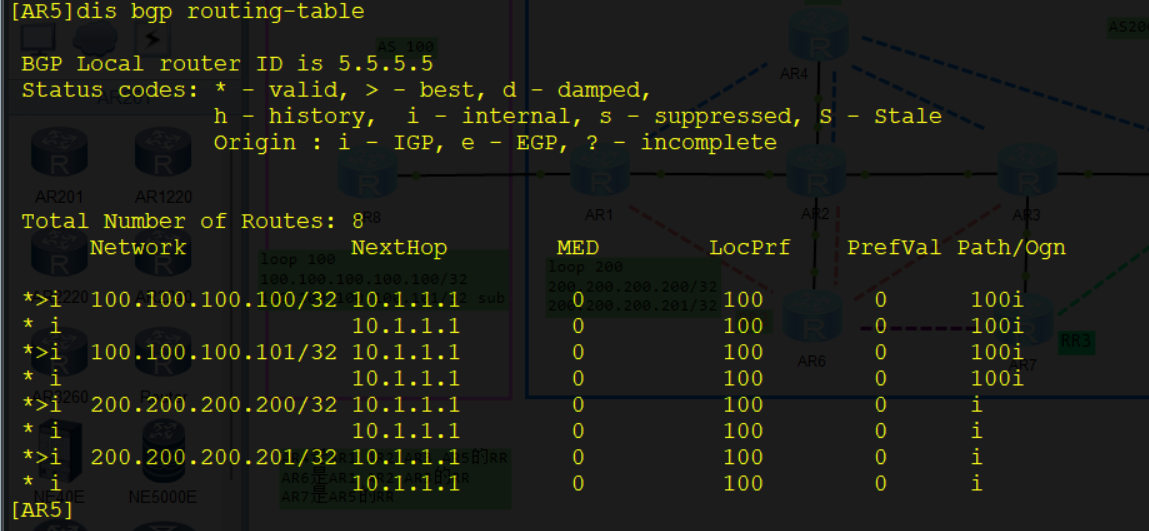
可以看到每个路由都有两个冗余
WLAN组网基本概念
WLAN概述
WLAN: Wireless LAN(无线局域网) ,指通过无线技术连接的网络,包括电磁波,激光,红外等
WIFI是WLAN中基于电磁波的一种无线网络
WLAN基于IEEE 802.11标准
802.11标准聚焦于TCP/IP模型的下两层
- 数据链路层:负责信道接入、寻址、数据帧校验、错误检测、安全机制等
- 物理层:负责传输比特流,规定使用的频段
具体使用的技术如下图:

对于Wifi,目前我们使用wifi 6(第6代wifi技术),其中各代技术和标准的对应关系如图:
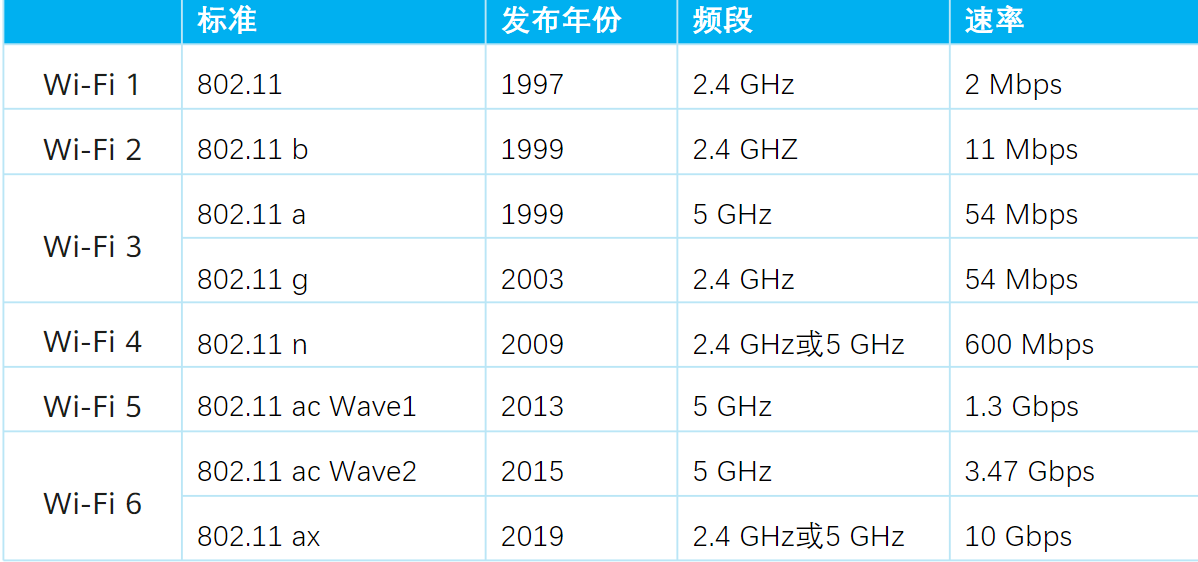
WLAN-有线侧组网概念
AP-AC组网方式
AP-AC间有二层和三层两种组网方式
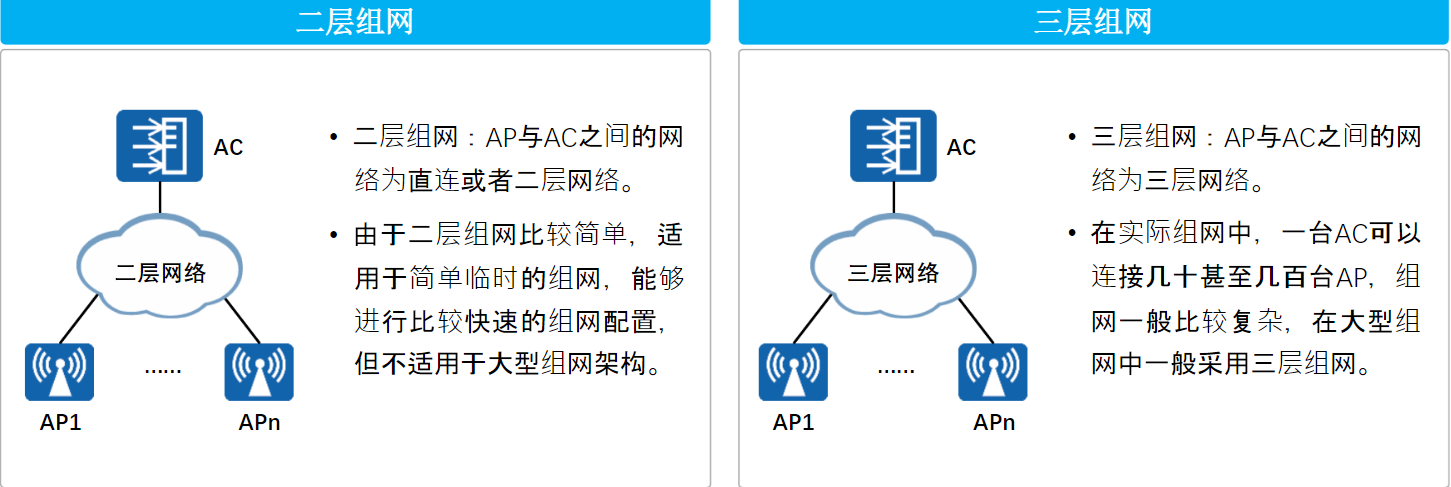
AC连接方式
AC接入网络有直连式和旁挂式两种
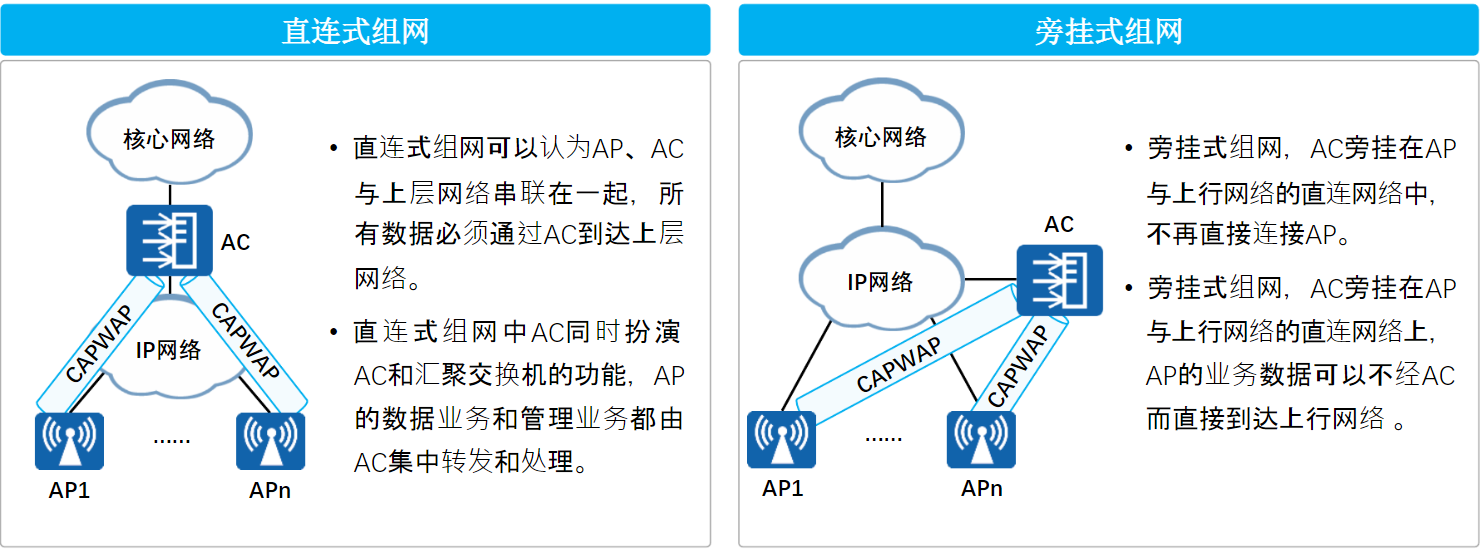
CAPWAP协议
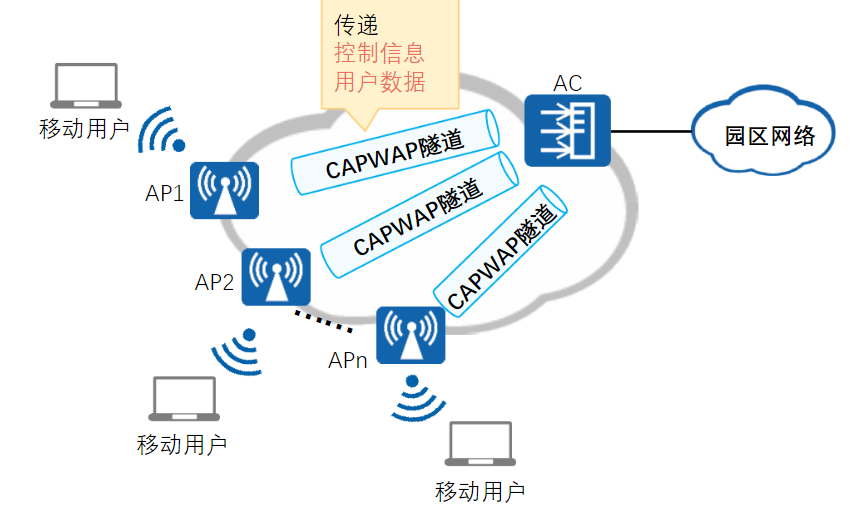
CAPWAP:无线接入点配置和控制协议。该协议定义如何对AP进行管理、业务配置。
在WLAN中AC和AP之间会建立并维护一条CAPWAP隧道,AC通过CAPWAP隧道实现对AP的统一管理。
一般CAPWAP隧道只转发配置报文,但采用隧道转发模式时,AP会将数据也通过CAPWAP发送给AC
AP上线没有一个标准定义,华为文档的定义是从AP获取地址到AC下发配置,华为提供的学习ppt是到建立并维护
CAPWAP隧道的过程个人认可到维护
CAPWAP隧道就算上线成功的说法CAPWAP隧道本身不携带VLAN,也就是默认VLAN1
WLAN-无线侧组网概念
无线电磁波
无线电磁波,特指频率3赫兹到300G赫兹的电磁波,也叫做射频电波、简称射频、射电。
WIFI就利用无线电磁波传递
民用无线网络使用两个电磁波频段:
- 2.4GHz(2.4G-2.4835GHz)
- 5GHz(5.15G-5.35GHz,5.725G-5.85GHz)
这两个频段也就是家用路由器所谓的2.4G和5G,不是5G网络
并且根据物理学,频率越大,波长越短,穿透能力越弱。所以2.4G网速比5G慢,但穿透性优于5G,而5GHz带宽大,网速快,但穿墙后衰减明显
可以对家里的路由器按需进行配置
其他频段均有特殊用途,随意使用属于违法行为:

无线信道
无论时2.4G还是5G,频率范围都是有限的,随意使用必然会产生干扰问题,所以无线通信协议对2.4G和5Gd对应的频段做了进一步划分,划分后的每个频率范围就是信道
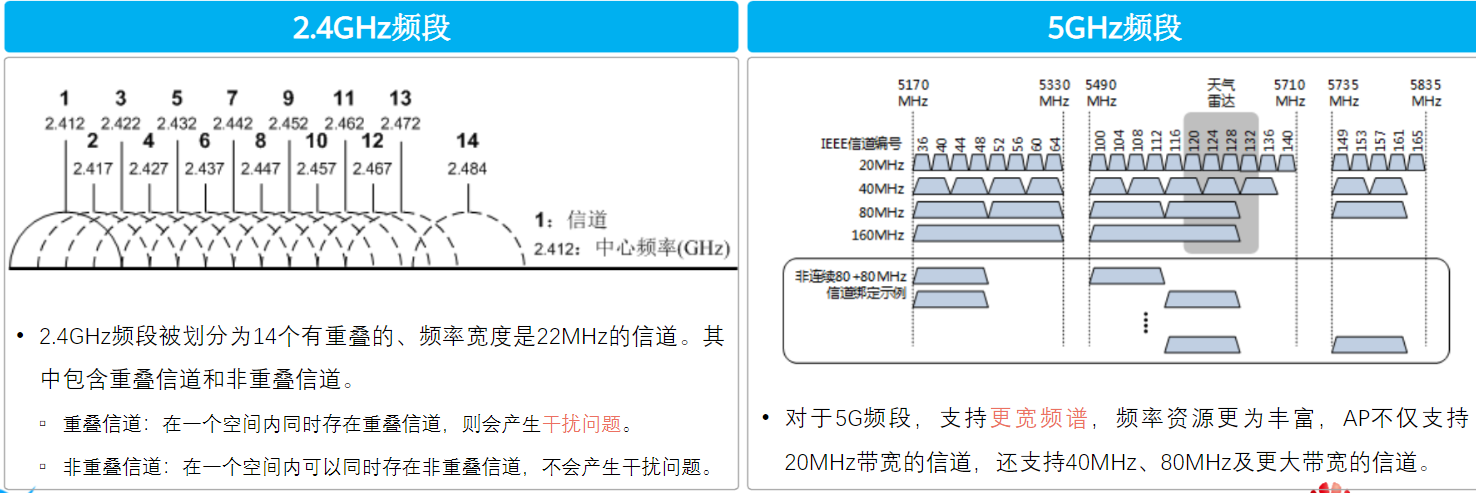
2.4G被分为14个信道,14信道属于特殊信道,不能使用,1-13信道相邻4个信道都会发生重叠
如果想避免干扰,应该选用不重叠的信道,如1,5,9或者2,6,10、3,7,11、4,8,12等
规律是隔4个信道取一个
5G支持多频合一:多个信道合成一个信道,所以不用刻意避免冲突,别放同一个频率就行
5G信道每个单位都是20MHz,两个信道合一就是40MHz,家用无线常用20MHz或40MHz,由于5G频段有一部分用于天气雷达,所以信道合一的极限是单个160MHz或者不连续的80+80MHz
BSS/SSID/BSSID
- BSS:基本服务集
- 一个AP覆盖的范围就是一个BSS
- 一个BSS内的设备可以直接相互通信(可以理解是一个广播域)
- BSSID:基本服务集标识符
- 唯一标识一个AP,用AP的MAC地址表示
- SSID:服务集标识符
- 无线网络的身份标识,与BSSID相似但有所不同
- BSSID标识一个AP,SSID标识一个网络(无线漫游时多个AP组成的网络也是一个网络)
- SSID就是常说的WiFi名称
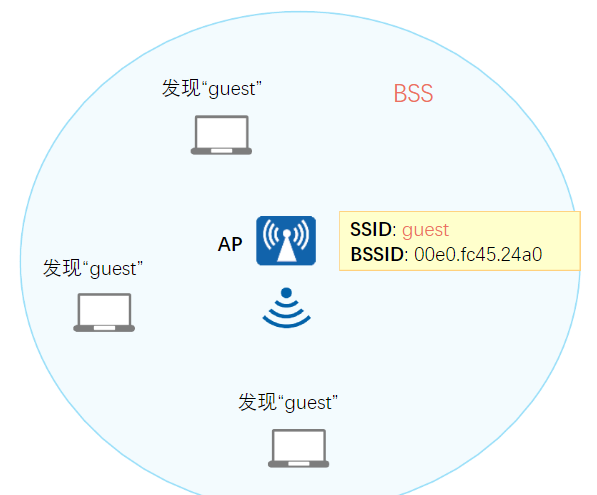
VAP
早期一个AP只能创建一个无线网络,如果要在同一空间部署多个BSS,就需要安放多个AP
VAP即Virtual AP(虚拟AP技术),通过在一个物理AP上虚拟出多个逻辑AP,每个逻辑AP对应一个BSS,以达成一个AP部署多个网络的目的
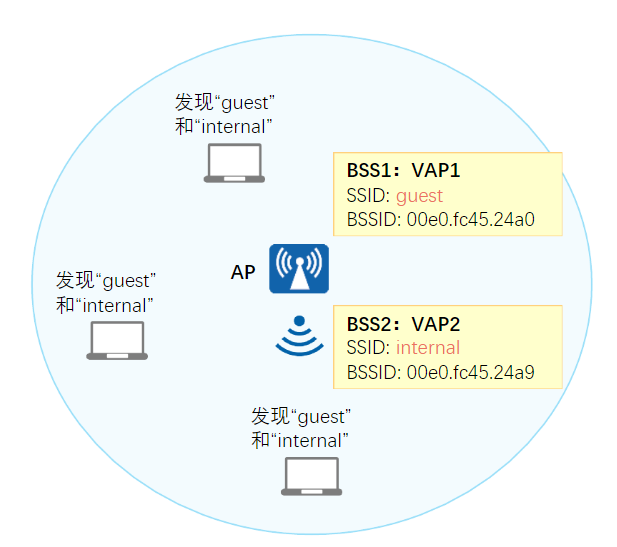
ESS:扩展服务集
单个AP的网络覆盖范围有限,在一些场景下,采用部署多个BSS的方式对网络覆盖范围进行扩展。
由于此时仍然是一个网络,所以用户从一个BSS移动但另一个BSS不能使其感知到网络变化
ESS:扩展服务集是由多个BSS组成的SSID相同的更大规模的网络(更大规模的虚拟BSS)
通常,我们所指的SSID即为ESSID。
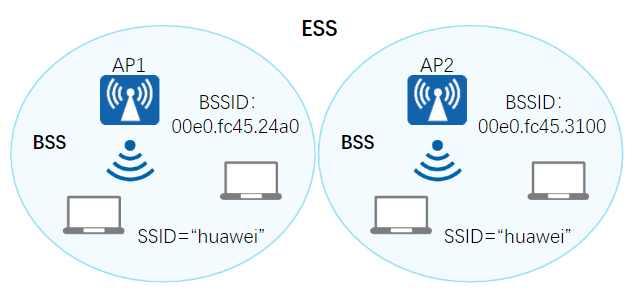
WLAN组网架构
FAT AP 和 FIT AP
在现有网络架构中,WLAN的组网有两种方式:
- FAT AP 架构:胖AP组网,适用于家用网络,小型企业
- 特点:由AP直接分发配置,每个AP都据有管理功能
- FIT AP 架构:瘦AP组网,适用于大型企业网络
- 特点:由AC统一管理AP,一切配置都由AC下发,AP只负责无线接入部分
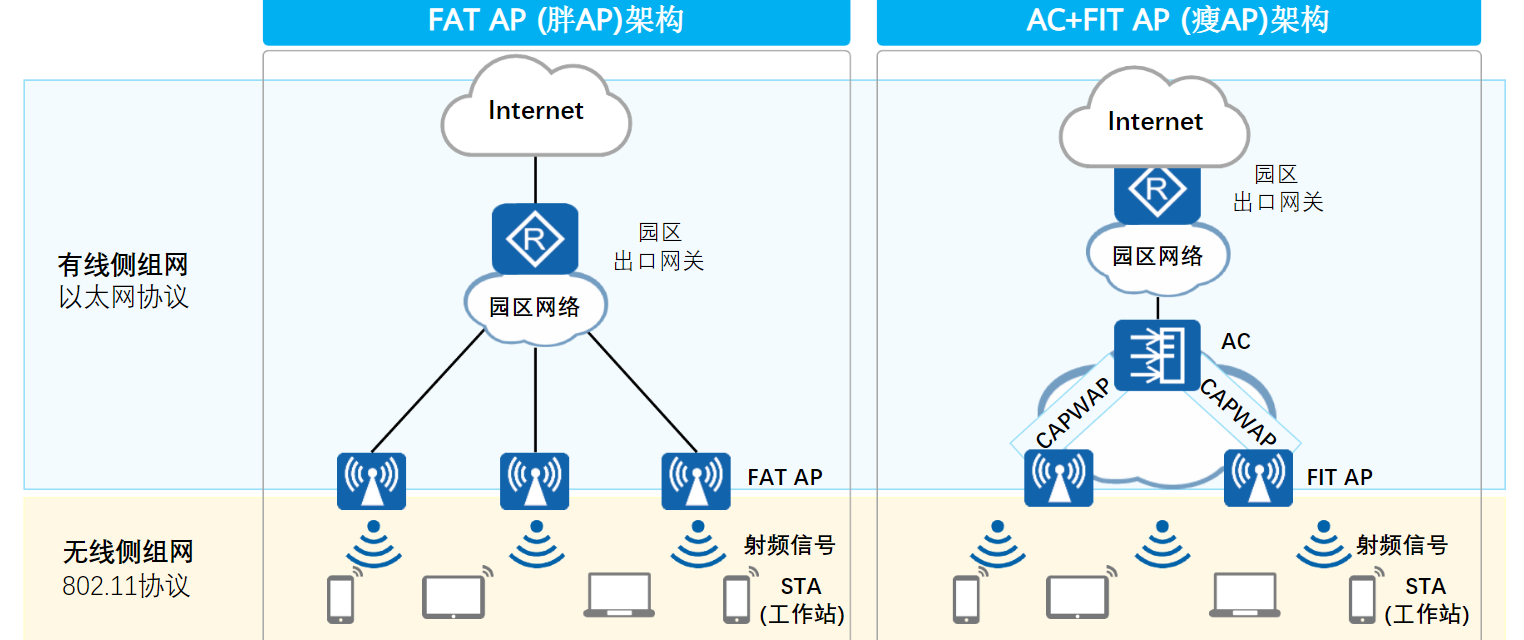
FAT AP

FIT AP

敏捷分布式AP
通过AC设备直接管理多个中心AP,在由中心AP管理全部子AP(敏分AP),以达到减少AC压力的目的
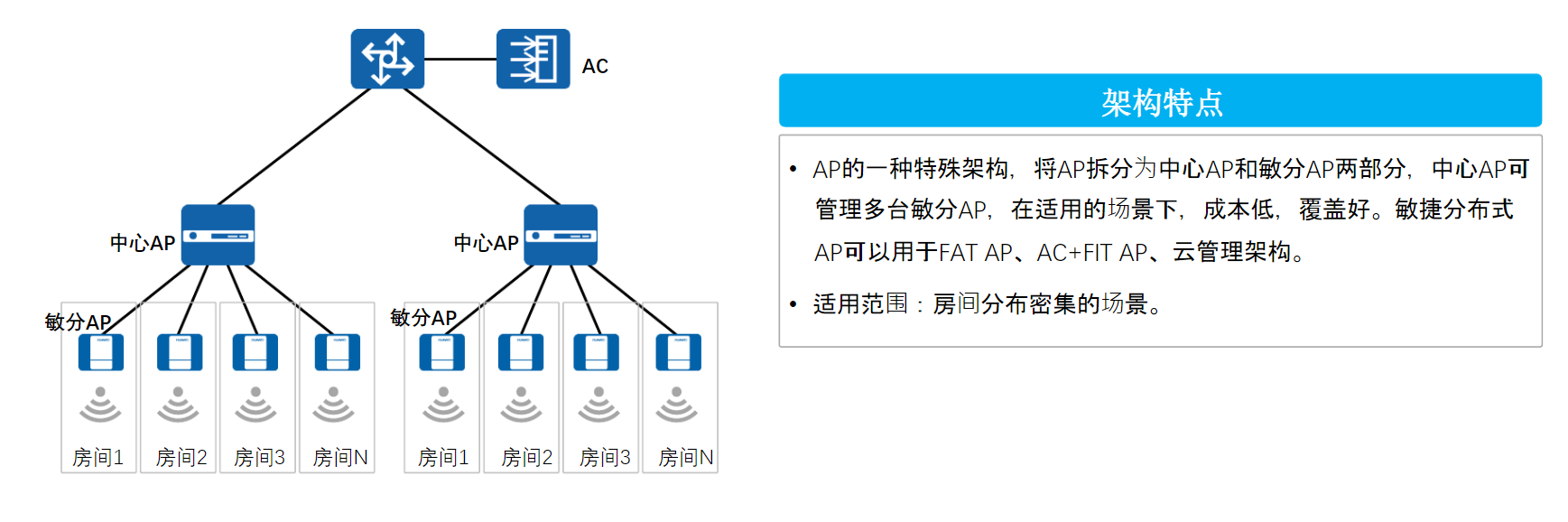
智简园区:IMaster NCE
华为主推的网络云管理平台,企业有钱可选
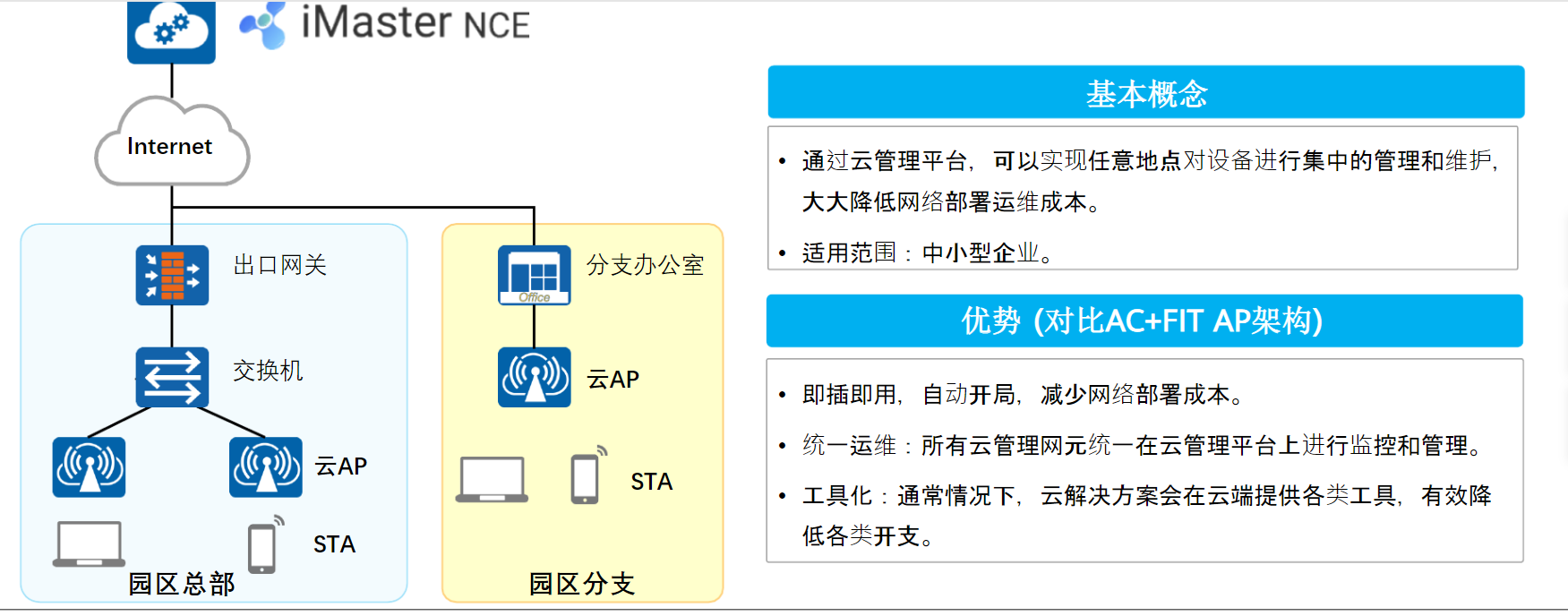
WLAN组网配置
WLAN组网分为四步:
- AP上线
- AC给AP下发WLAN配置
- 无线终端接入WLAN网络
- 数据传输
其中,3、4两步我们不太关心,我们主要关心1、2两步
AP上线
AP上线流程如下图所示,大体流程口述如下:
- 在AC上进行预配置(DHCP服务、指定CAPWAP隧道使用的接口等)
- AP首先会获取IP地址,可以是从AC的DHCP获取,也可以是其他设备
- AP通过三种方式去寻找AC
- AP和AC建立CAPWAP隧道

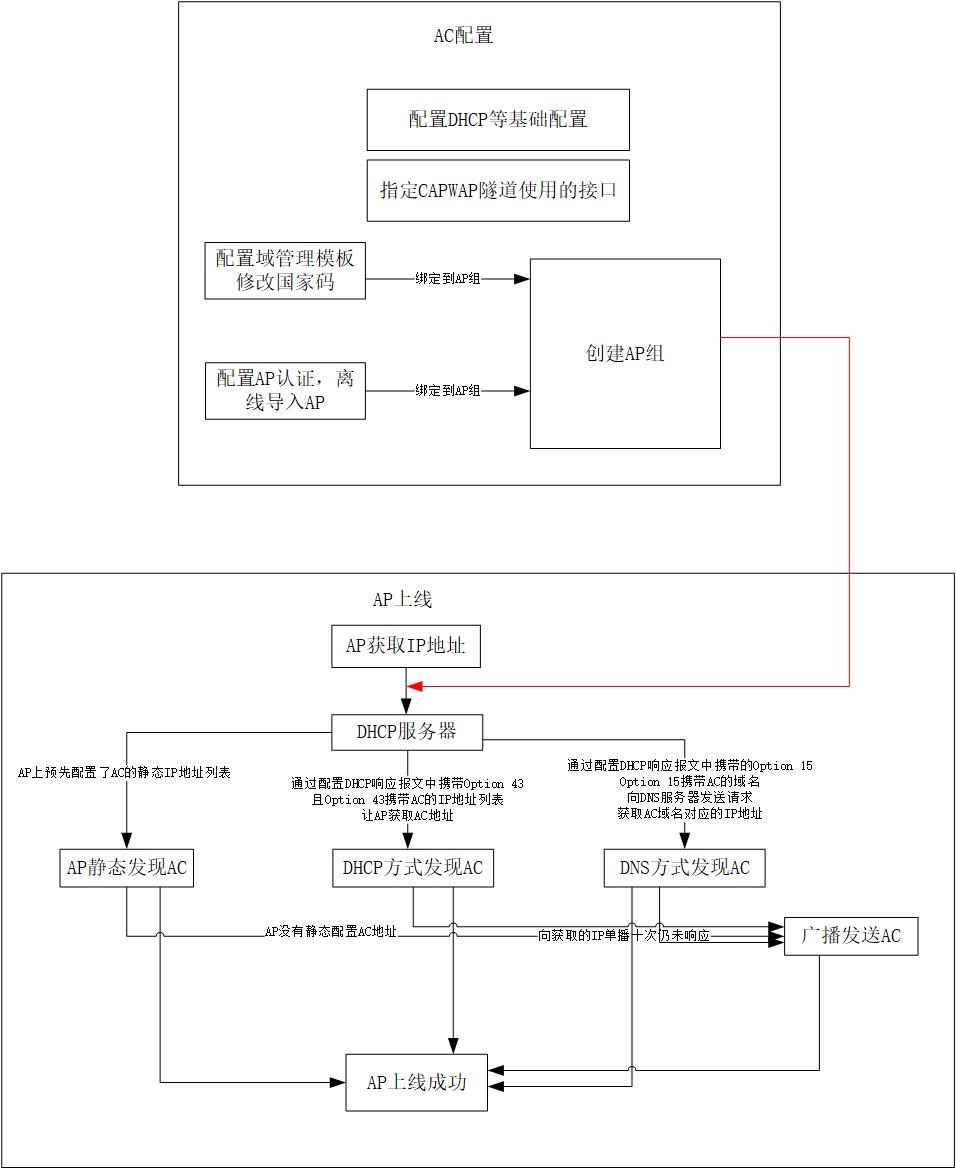
AP上线 细节描述以及对应配置
AC预配置:
# 配置DHCP以及其他基础配置
dhcp enable # 开启dhcp服务
interface Vlanif100
ip address 192.168.100.254 255.255.255.0 # 配置管理vlan地址
dhcp select interface # 开启DHCP
# 指定DHCP option 43 字段,使AP获取ip的同时获取AC地址
dhcp server option 43 sub-option 2 ip-address 192.168.100.254
capwap source interface vlanif100 # 配置使用vlanif100接口建立CAPWAP隧道
细节解释:
1、AP获取IP地址的方式:
2、AP发现AC的方式:
静态方式:
动态方式:
动态方式-广播方式:
简单来说,AP以广播方式请求AC,有以下两种请况
既没有在AP上静态配置AC地址,又没有配置DHCP的
option43和option15字段配置了DHCP的
option43或option15字段,但AP向这个地址发送的十次请求都没有被响应在双链路冷备,主链路
CAPWAP已经建立,备链路AC地址请求无响应时,备链路CAPWAP不会进行广播请求,而是一直单播3、建立CAPWAP隧道
CAPWAP隧道是一体两面的,一个隧道,既是控制隧道,又是数据隧道。所以可以理解为建立了两个在同一物理链路的CAPWAP隧道AC可以给
CAPWAP隧道发送的报文打上指定VLAN,但FIT AP做不到,FIT AP只能以不携带VLAN的方式向CAPWAP隧道发送报文。所以要将和AC直连的交换机端口pvid设置为指定
VLAN,保证CAPWAP隧道两端二层互通




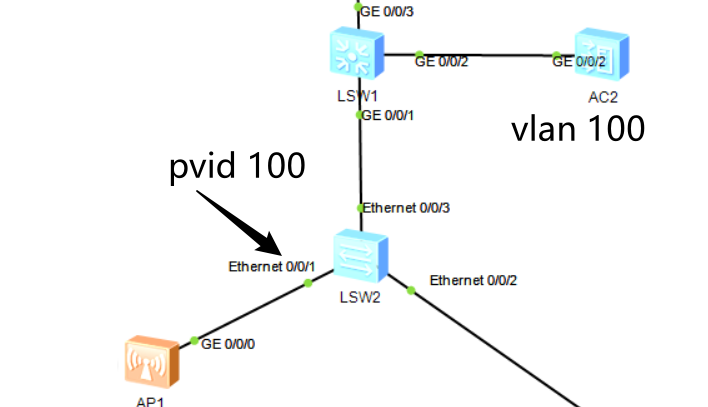
# 添加AP设备
wlan
# 配置域管理模板,华为的国家码默认CN
regulatory-domain-profile name atmujie
country-code CN # 配置国家码【默认CN】
# 创建AP组
ap-group name atmujie
regulatory-domain-profile atmujie # 绑定域管理模板
ap auth-mode mac-auth # 配置ap绑定认证模式为mac认证【默认,可以不配】
# 绑定一个ap设备
ap-id 0 type-id 69 ap-mac 00e0-fceb-5420 ap-sn 2102354483100D392801
ap-name ap1 # 给该设备起名ap1
ap-group atmujie # 将该设备绑定ap组"atmujie"
# 绑定下一个ap设备
ap-id 1 ap-mac 00e0-fcac-2110
ap-name ap2
ap-group atmujie
细节解释
AP发现AC建立隧道和接入控制是同步进行的
即AC绑定了AP,AP才能发现这个AC,才能进行接入控制。如果没有绑定AP,AP即使有AC的地址也无法发现AC
AP发现AC后,进入接入控制阶段
此AP发送
Join Request请求,AC收到后会判断是否允许该AP接入,并响应Join Response报文
Join Response报文携带了AC上配置的关于AP的版本升级方式及指定的AP版本信息。AP收到
Join Response报文,检查报文参数,判断当前的系统软件版本是否与AC上指定的一致。
- 一致,进入下一阶段
- 不一致,则AP开始更新软件版本
AP在软件版本更新完成后重新启动,重新获取地址->接入控制
接入控制成功后,进入CAPWAP隧道维持阶段
AP与AC之间交互
Keepalive(UDP端口号为5247)报文来检测数据隧道的连通状态。AP与AC交互
Echo(UDP端口号为5246)报文来检测控制隧道的连通状态。
查看AP上线状态
dispaly ap all # 查看ap信息
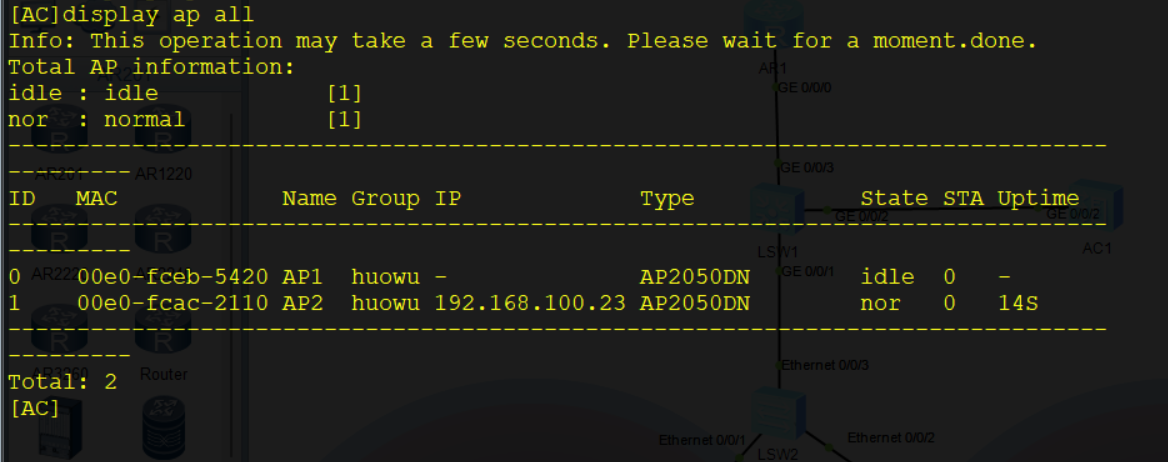
idle表示连接未建立, nor表示ap上线成功
WLAN业务下发

WLAN业务下发部分根据不同版本的AC命令配置有所不同,具体配置需要提前查阅对应的AC文档
学习时教的是如下流程,这里也按这个流程来做
这个流程只是一个简化流程,还有包括射频配置、QOS等设置,都需要引入其他模板
总得来说就是VAP模板引入其他模板完成射频配置,AP组引入VAP模板
配置SSID模板
SSID模板主要用于配置WLAN网络的SSID名称,还可以配置其他的功能,但这里并不太关注,需要配置其他功能自行查阅文档
wlan # 进入wlan视图
ssid-profile name atmujie # 创建SSID模板,名为atmujie
ssid atmujie # 配置网络的ssid为atmujie
配置安全模板
无线终端通过SSID接入WLAN网络时,会根据VAP中安全模板配置的安全策略,完成身份认证后接入WLAN网络
就是说连接wifi时输入的密码就是安全模板中设置的密码
wlan # 进入wlan视图
security-profile name atmujie # 创建安全模板,名称为atmujie
security wpa-wpa2 psk pass-phrase atmujie123 aes # 设置认证方式、安全策略、密码
安全模板主要是作用于STA接入时的接入认证,有三个部分内容
密码:不必多说,就是密码
认证方式:有
PSK和802.1X认证两种 可以类比为P2P链路中的
PAP认证和CHAP认证,只是认证方式不同安全策略:和其他策略一样,就是定义处理动作的。
WLAN预定义了三种策略,具体区别如图
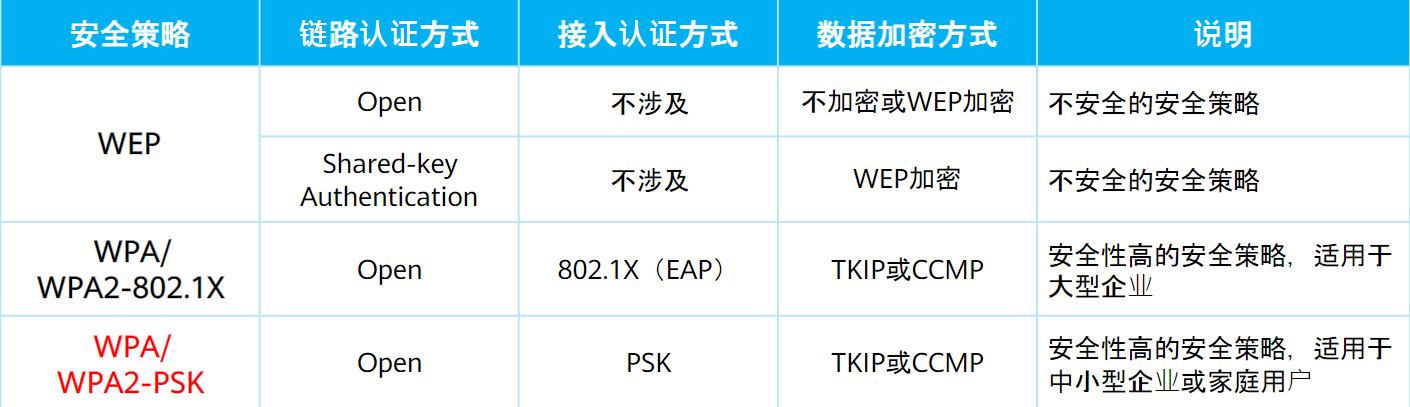
所以使用PSK认证,就使用wpa-wpa2 psk策略,使用802.1X认证,就使用wpa-wpa2 dot1X策略
最后指定加密标准为aes(高级加密标准)即可
配置VAP模板
将各类配置模板引入VAP模板,然后在AP组或AP中使用VAP模板,AP上就会生成VAP,从而为STA提供无线接入服务
通过配置多个VAP模板,就可以让AP创建多个网络
VAP模板可以引入的模板:
- SSID模板:主要用于配置WLAN网络的SSID名称,还可以配置禁止非HT终端接入功能、配置STA关联老化时间和DTIM周期参数。
- 安全模板:主要用于配置WLAN网络的安全策略,包括对STA的认证和加密。
- 流量模板:主要用于配置WLAN网络的优先级映射和流量监管功能
- 认证模板:主要用来统一管理NAC的配置信息
这里我们只需引入SSID模板和安全模板
wlan # 进入wlan视图
vap-profile name atmujie # 创建VAP模板,名称为atmujie
service-vlan vlan-id 101 # 指定业务vlan为vlan 101
ssid-profile atmujie # 引用ssid模板
security-profile atmujie # 引用安全模板
在AP组中使用VAP模板
配置完全后,只需在ap组中调用VAP,相应的WLAN配置就会下发给组中所有的AP
wlan # 进入wlan视图
ap-group name atmujie
# 将vap模板atmujie用于所有射频
vap-profile atmujie wlan 1 radio all
通过在AP组中将不同的VAP模板绑入不同的wlan-id中,就可以让AP创建多个WLAN网络
其他命令:
display vap ssid w # 查看指定ssid的信息
无线终端接入WLAN网络

如上图,分6个阶段
这里不是重点,直接贴截图
扫描阶段

如果之间连接过WIFI,下来再来,终端就会自动连接,就是携带指定SSID的主动扫描
之间没有连接过,第一个连接,终端不会携带SSID,就是携带空SSID的主动扫描
链路认证
只要对安全要求极高的网络才用的到,一般都不需要链路认证
关联

终端和AP、AC协商参数的阶段
接入认证

输入WIFI密码连接WIFI,就是接入认证
DHCP获取地址
用AC告知的业务VLAN对应网段请求DHCP,和传统的DHCP获取地址没有区别
WLAN业务数据转发

根据业务数据是否通过隧道转发,WLAN的业务转发方式也分为隧道转发和直接转发
一般来说,AC直连组网使用隧道转发,AC旁挂组网使用直连转发
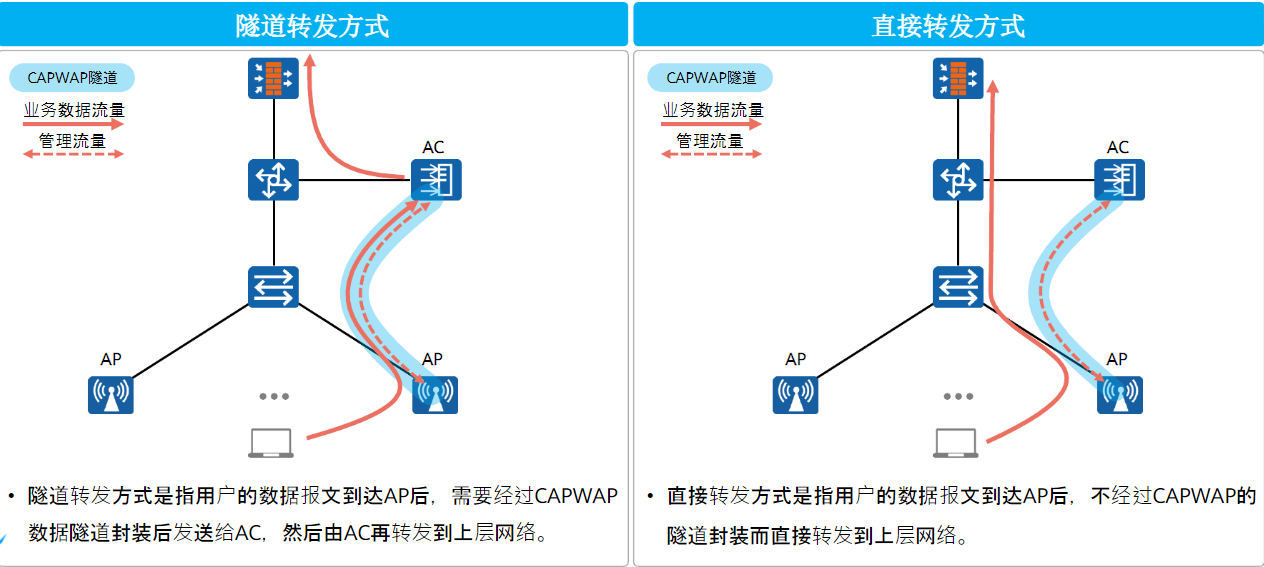
大型WLAN组网
大型WLAN组网包括以下技术点

VLAN POOL
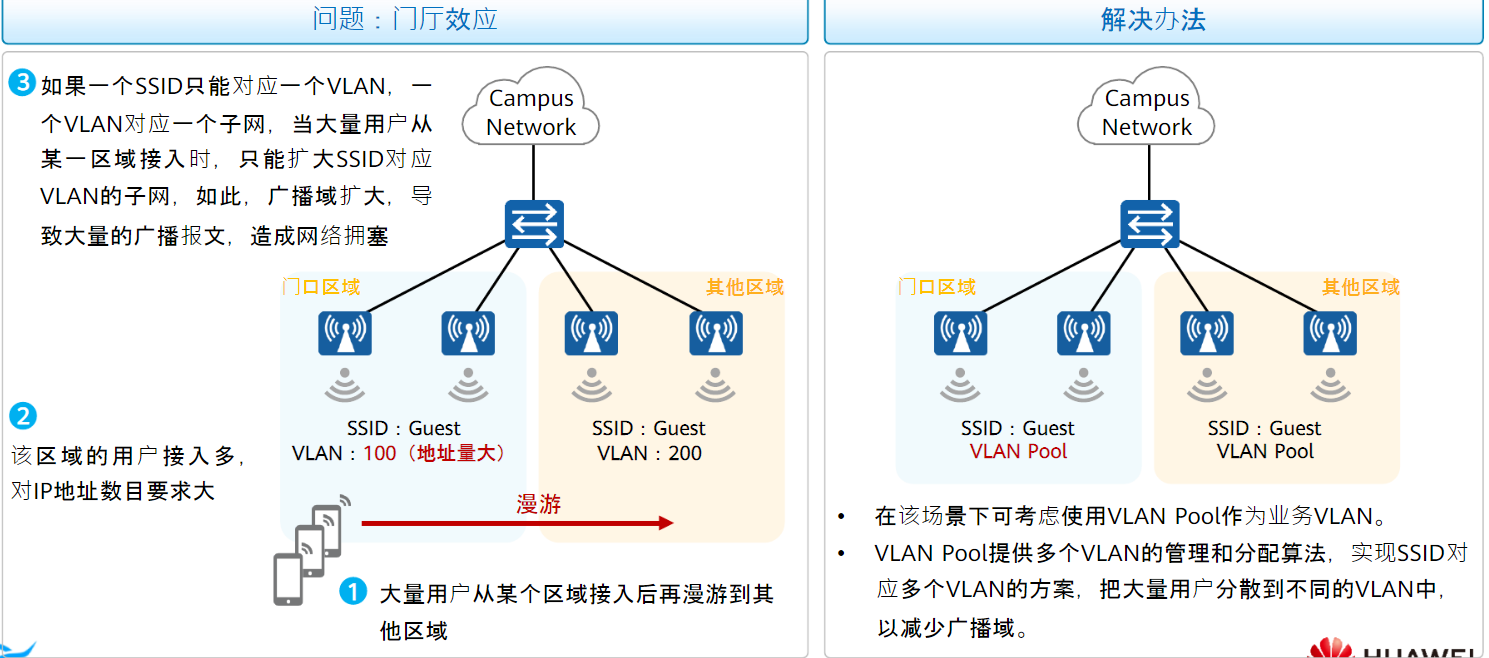
由于无线用户接入方式和接入位置较为灵活,经常会出现用户在某个地点(例如办公区入口或体育场馆入口)集中接入到同一个无线网络中,然后漫游到其它AP覆盖的无线网络环境下。
如果每个SSID中只有一个业务VLAN为无线用户提供无线网络服务,很容易产生接入用户数多的区域IP地址资源不足、而其它区域IP地址资源浪费的现象。
通过将VLAN pool配置为无线用户的业务VLAN,实现一个SSID能够同时支持多个业务VLAN。新接入的用户会被动态地分配到VLAN pool中的各个VLAN中,减少了单个VLAN下的用户数,缩小了广播域;同时每个VLAN尽量均匀地分配IP地址,减少了IP地址的浪费。
就是把多个VLAN放进一个池子,将池子作为业务VLAN,用户连接WALN网络时随机分配其中VLAN
VLAN Pool分配方式
VLAN Pool有两种分配方式:
- 顺序分配:根据用户的上线顺序分配
VLAN - HSAH分配:根据用户MAC地址计算HSAH值分配VLAN
VLAN Pool配置
创建VLAN Pool
vlan pool wj # 创建一个vlan pool,名为wj
assignment even # 设置为随机分配模式(HASH模式是 assignment hash)
vlan 100 to 101 # 将VLAN划入VLAN Pool
使用VLAN Pool
wlan # 进入WLAN视图
vap-profile name wj # 创建vap模板,名为wj
service-vlan vlan-pool wj # 以名为wj的vlan pool作为业务VLAN
检查vlan pool使用情况
display vlan pool all # 查看vlan pool 的简略信息
display vlan pool name [vlanPool名称] # 查看指定VLAN Pool详细信息
WLAN漫游
WLAN漫游是指STA在同属于一个ESS内的AP之间移动且保持用户业务不中断。
如图所示,STA从AP1的覆盖范围移动到AP2的覆盖范围的行为就叫做漫游。
实现漫游的两个AP必须使用相同的
SSID和安全模板(模板名称可以不同,但是配置必须相同)WLAN漫游策略避免了认证时间过长导致业务中断,并且漫游后用户的授权信息和IP地址不变
WLAN漫游相关术语
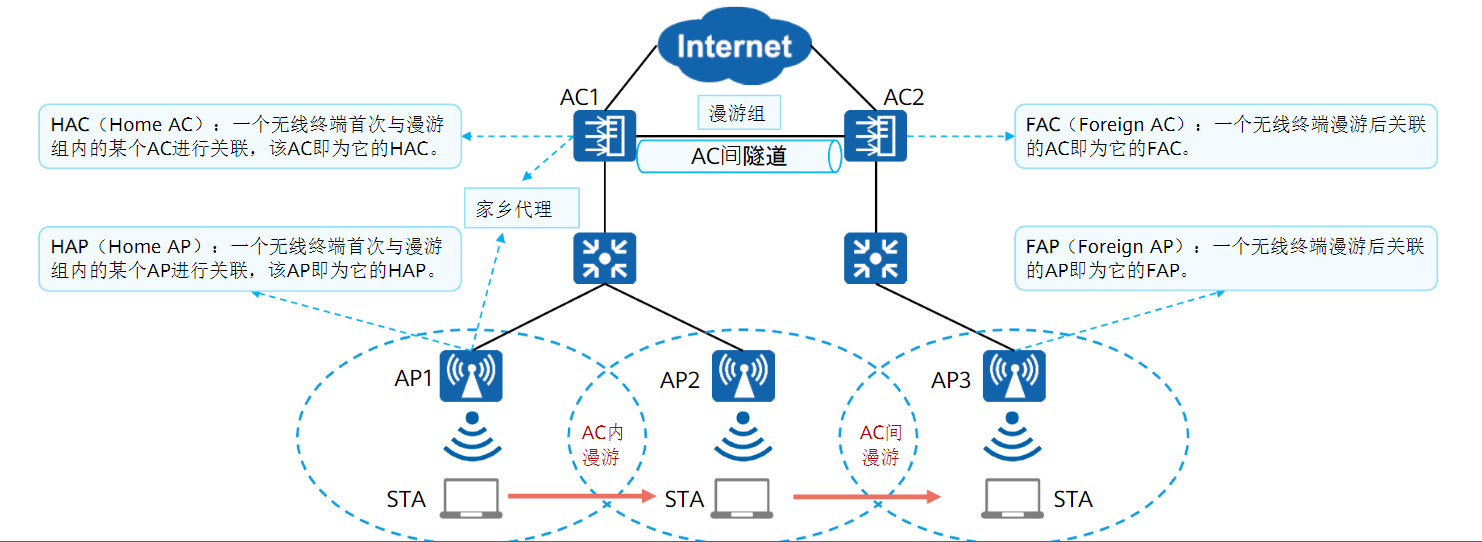
HAP/HAC:用户初次接入网络时关联的AP和ACFAC/FAC:用户漫游后关联的AP和AC- 家乡代理:为了保证IP地址不变,三层漫游后用户产生的数据会从
FAP发回HAC/HAP(具体发谁看情况),由HAC/HAP负责转发,此时负责转发的HAC/HAP就叫做家乡代理
二层漫游与三层漫游
根据用户是否跨网段进行漫游,将漫游的类型分为二层漫游(L2漫游)和三层漫游(L3漫游)
根据业务数据的转发方式,又分为直接转发和隧道转发
所以一共有四种漫游模型:
- 二层漫游直接转发
- 二层漫游隧道转发
- 三层漫游直接转发
- 三层漫游隧道转发
具体区别如下:

二层漫游
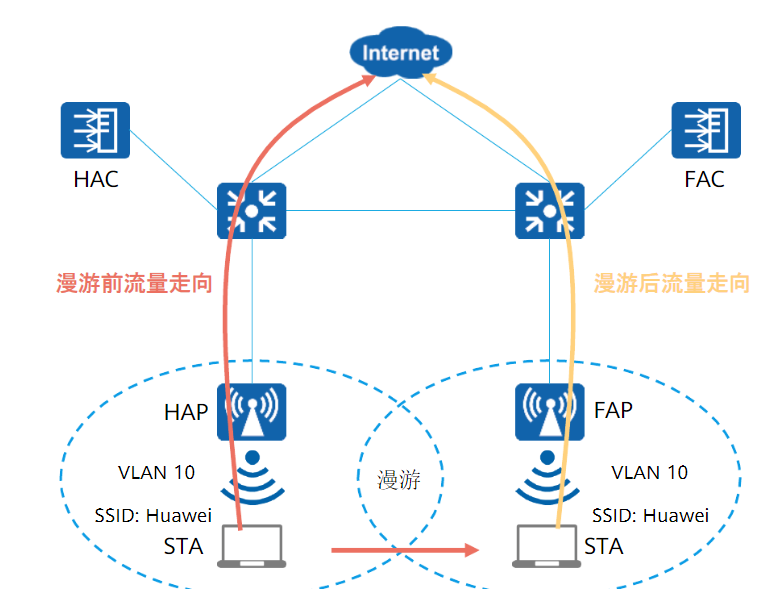
对于二层漫游而言,用户在AP之间的移动并没有导致网段发送改变,所以无论直接转发还是隧道转发,都无需额外配置
只需配置漫游组即可
wlan # 进入wlan视图
mobility-group name wj # 创建漫游组
# 将需要建立AC间隧道的AC管理网段网关加入漫游组
member ip-address xxx.xxx.xxx.xxx
三层漫游
对于三层漫游,由于移动后导致网段发生变化,所以需要先用CAPWAP将业务数据发往接入网段的HAC/HAP
让接入网段的HAC/HAP负责转发,从而保证用户IP地址不发生改变
根据转发模式,三层漫游有所区别
三层漫游隧道转发:
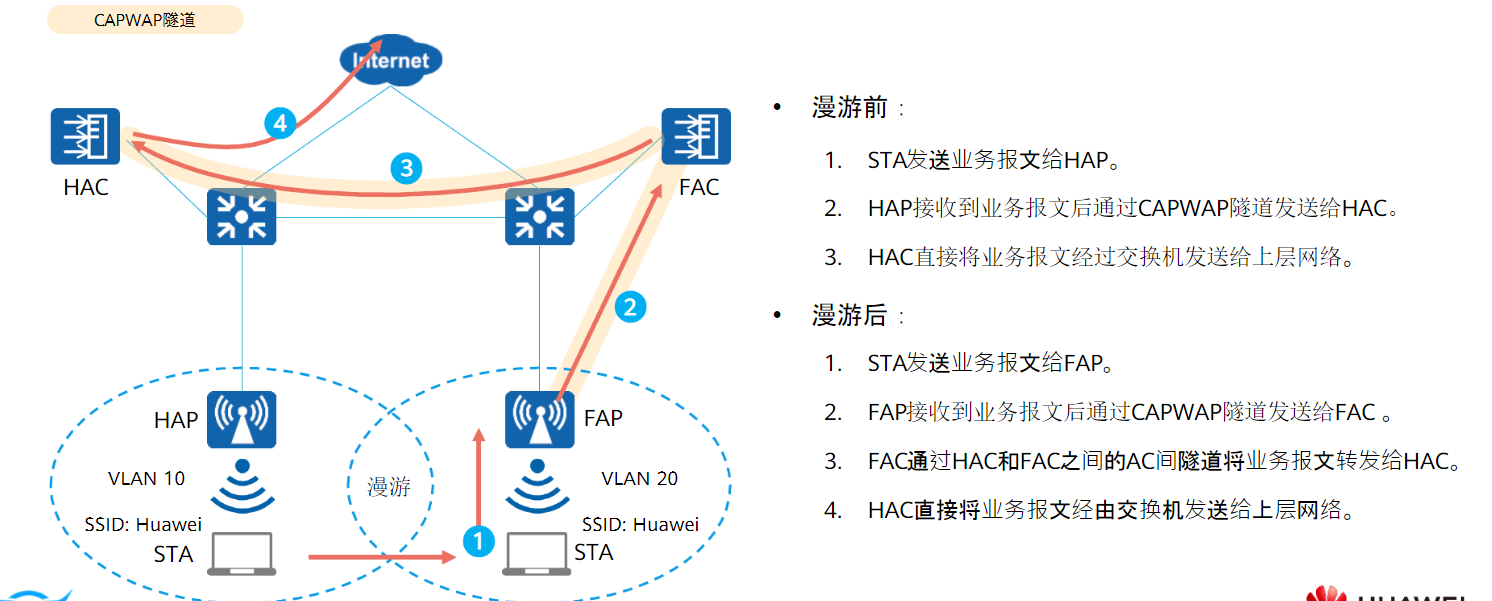
如图,STA从VLAN10漫游到VLAN 20,所在网段发生变化,但STA的IP不能改变,所以就需要FAP将STA的业务报文发回HAC/HAP
同时由于VLAN 10的报文不能再VLAN 20的区域传输,所以封入CAPWAP隧道,通过CAPWAP隧道转发给FAC
到达FAC后,由于漫游配置中会建立HAC-FAC的AC间隧道,报文重新封入AC间隧道转发给HAC
由于是VLAN 10是隧道转发,所以HAC无需转发给HAP,就可以知道到了接入网段,HAC将报文转发目的地址
回应报文也由HAC通过隧道传回FAP
此时HAC为家乡代理
由于
vlan 10业务报文通过capwap隧道转发FAC时会解封装外层隧道报头,露出vlan 10的报文头部,所以FAC需要创建vlan 10让设备可以识别内层报文,从而封装入AC间隧道如果不创建,FAC业务vlan为
vlan 20,不能识别vlan 10,FAC会将报文丢弃,导致漫游失败同理,从
VLAN 20漫游到VLAN 10,上图VLAN 10的AC也需要创建vlan 20
三层漫游直接转发:
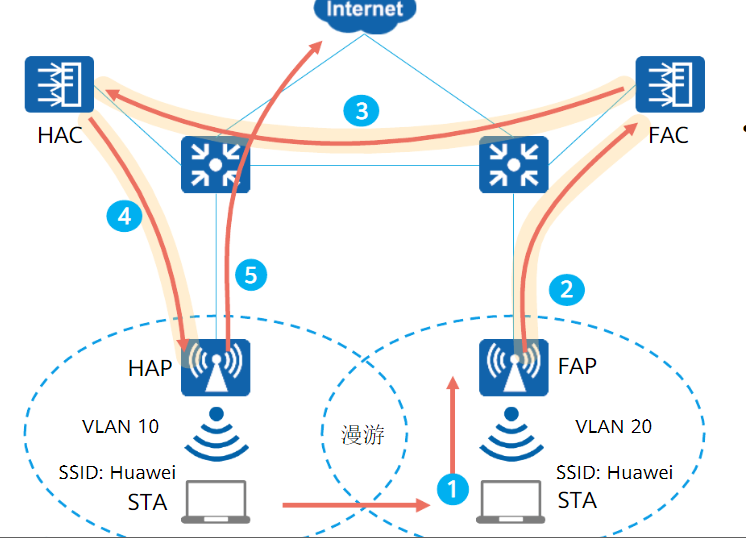
三层直接转发和隧道转发的唯一区别是业务报文通过CAPWAP隧道发到HAC后,仍然无法确定是否到达接入网段,所以需要通过HAC和HAP之间的CAPWAP隧道发往HAP
最终由HAP发送数据
此时家乡代理为HAP
三层漫游配置
topo:
前提:
- 两个WALN网络(两个AC)已经正常配置完毕、AP正常上线,并且
SSID和安全模板相同 - 两个AC管理vlan网关可以相互ping通
在上述前提完成的情况下做如下配置:
AC1:
vlan 102 # 创建对端业务vlan保证报文可以识别
wlan # 进入wlan视图
mobility-group name wj # 创建漫游组
# 将需要建立AC间隧道的AC管理网段网关加入漫游组
member ip-address 192.168.11.254 # AC1自己
member ip-address 192.168.12.254 # AC2
AC2:
vlan 101 # 创建对端业务vlan保证报文可以识别
wlan # 进入wlan视图
mobility-group name wj # 创建漫游组
# 将需要建立AC间隧道的AC管理网段网关加入漫游组
member ip-address 192.168.11.254 # AC1
member ip-address 192.168.12.254 # AC2自已
检查AC间隧道是否建立:
dis mobility-group name wj # 查看漫游组
检查漫游:
- 移动设备后查看ip是否改变
- 不断ping一个地址,然后让设备自然移动,查看响应情况